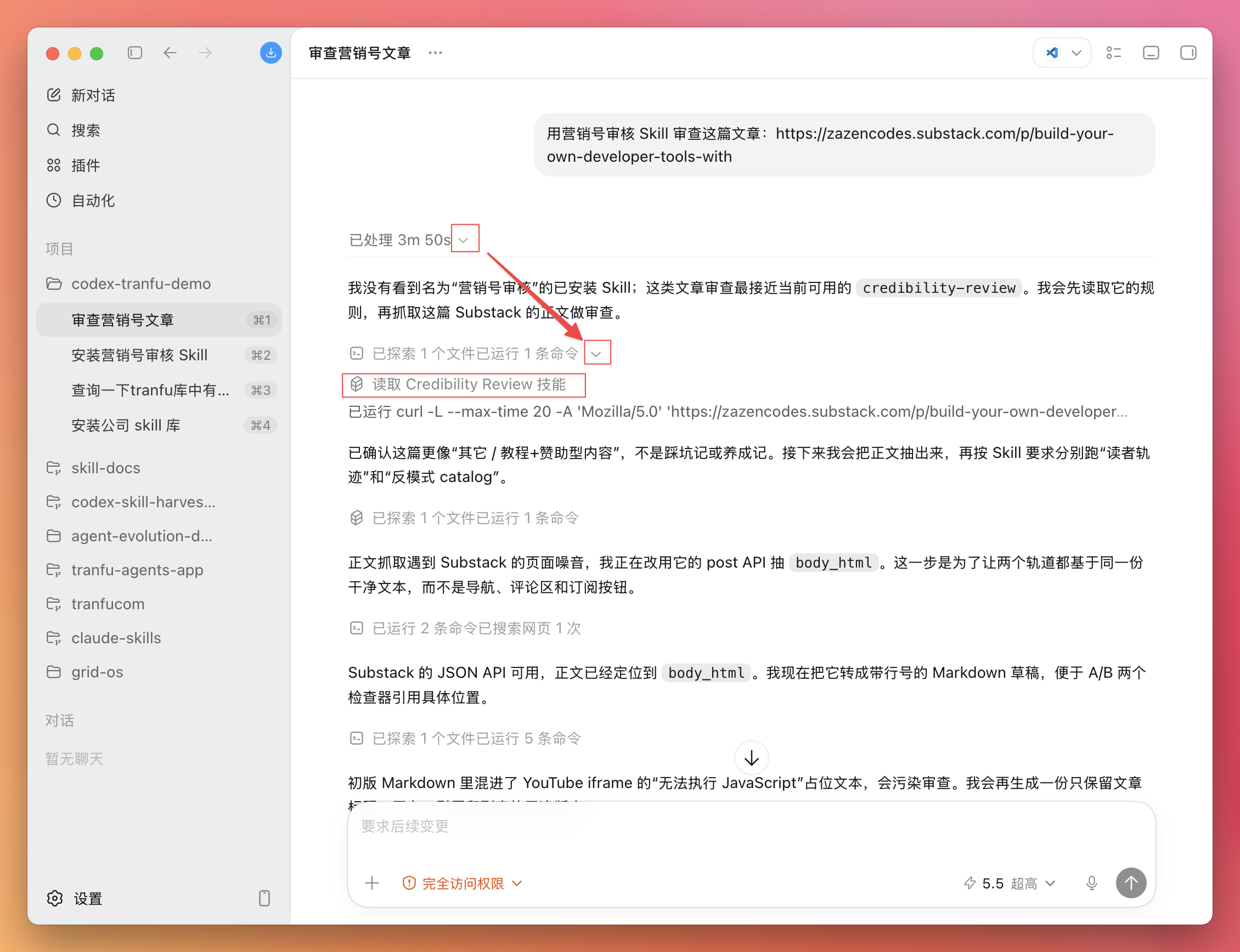
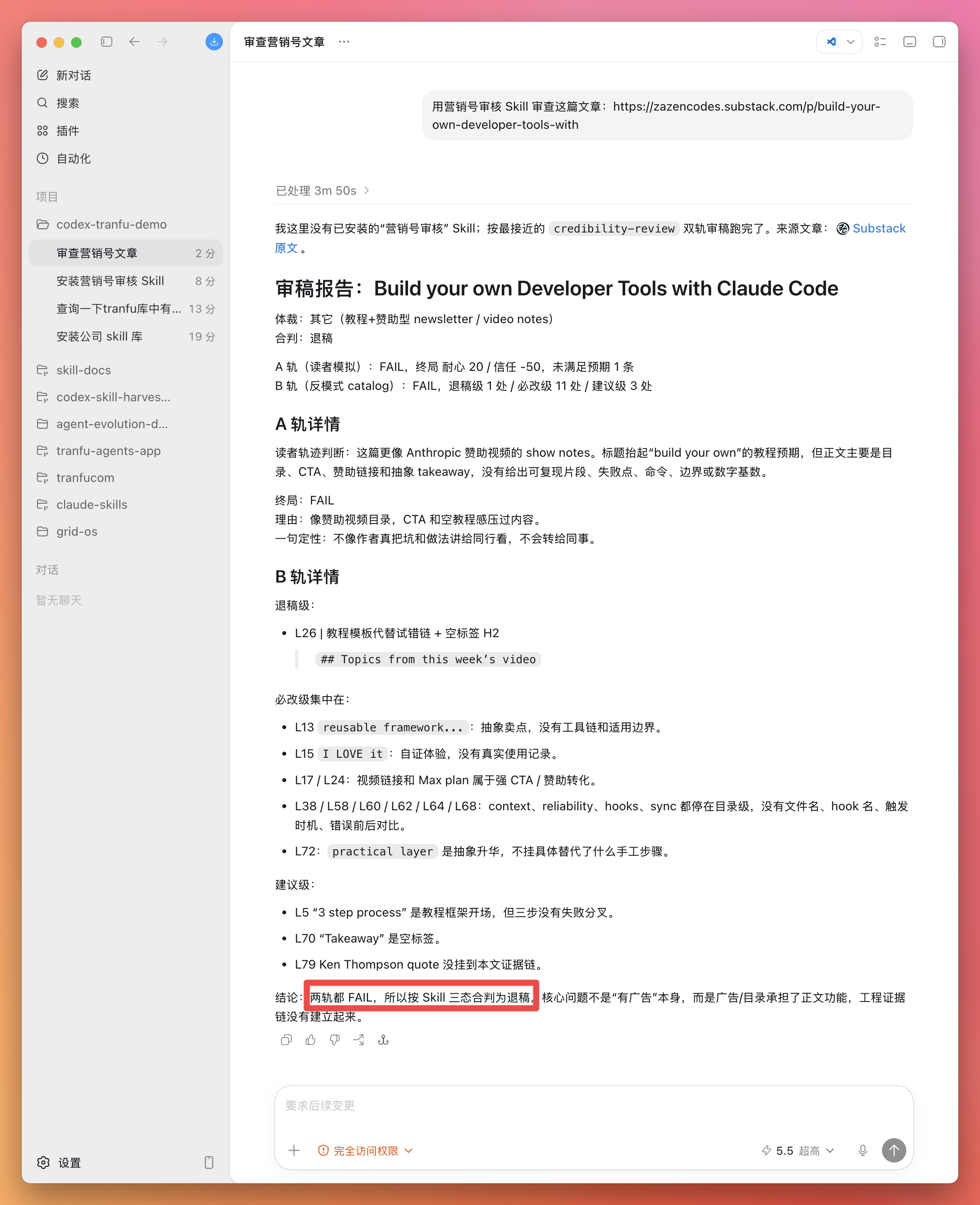
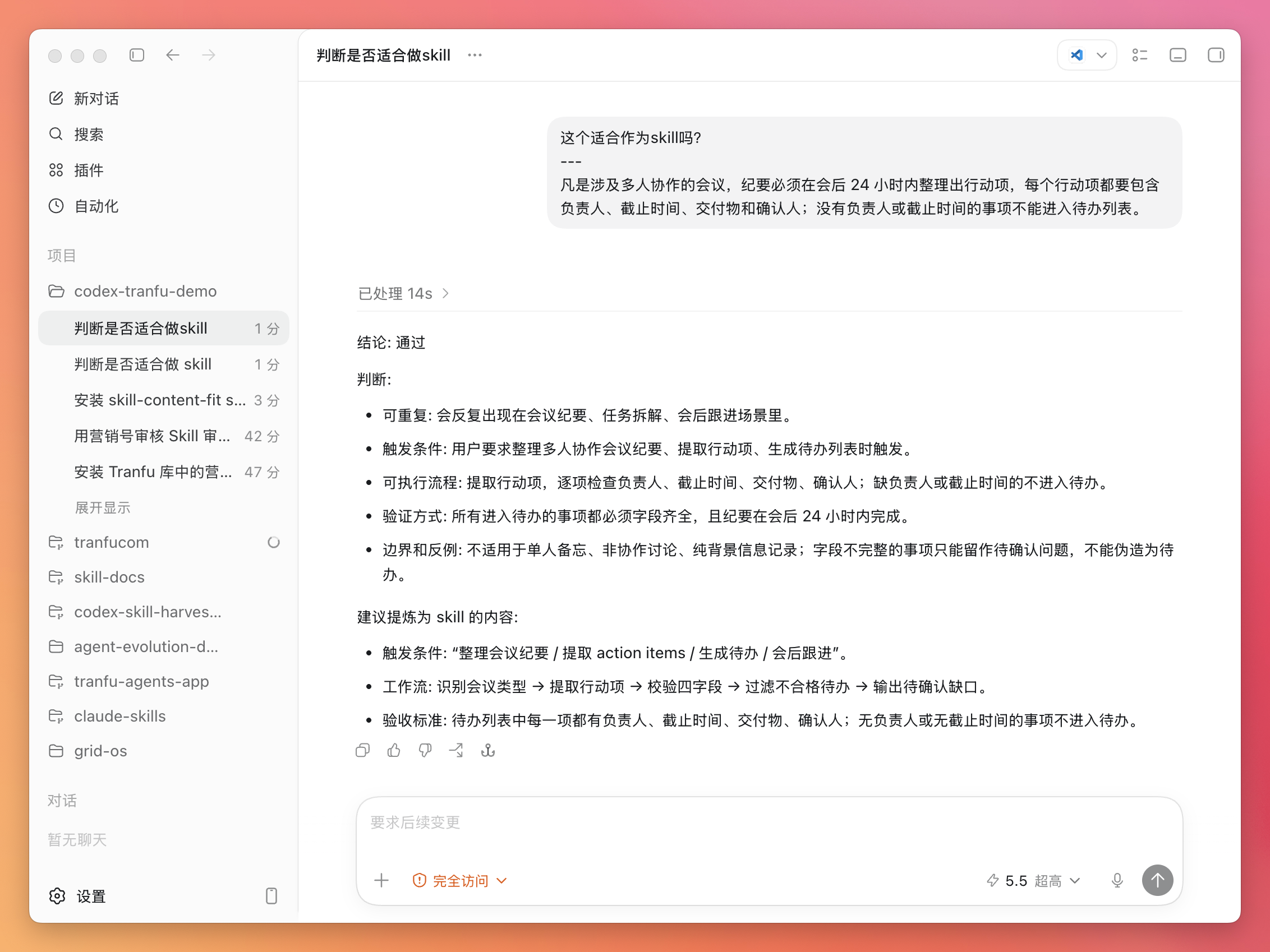
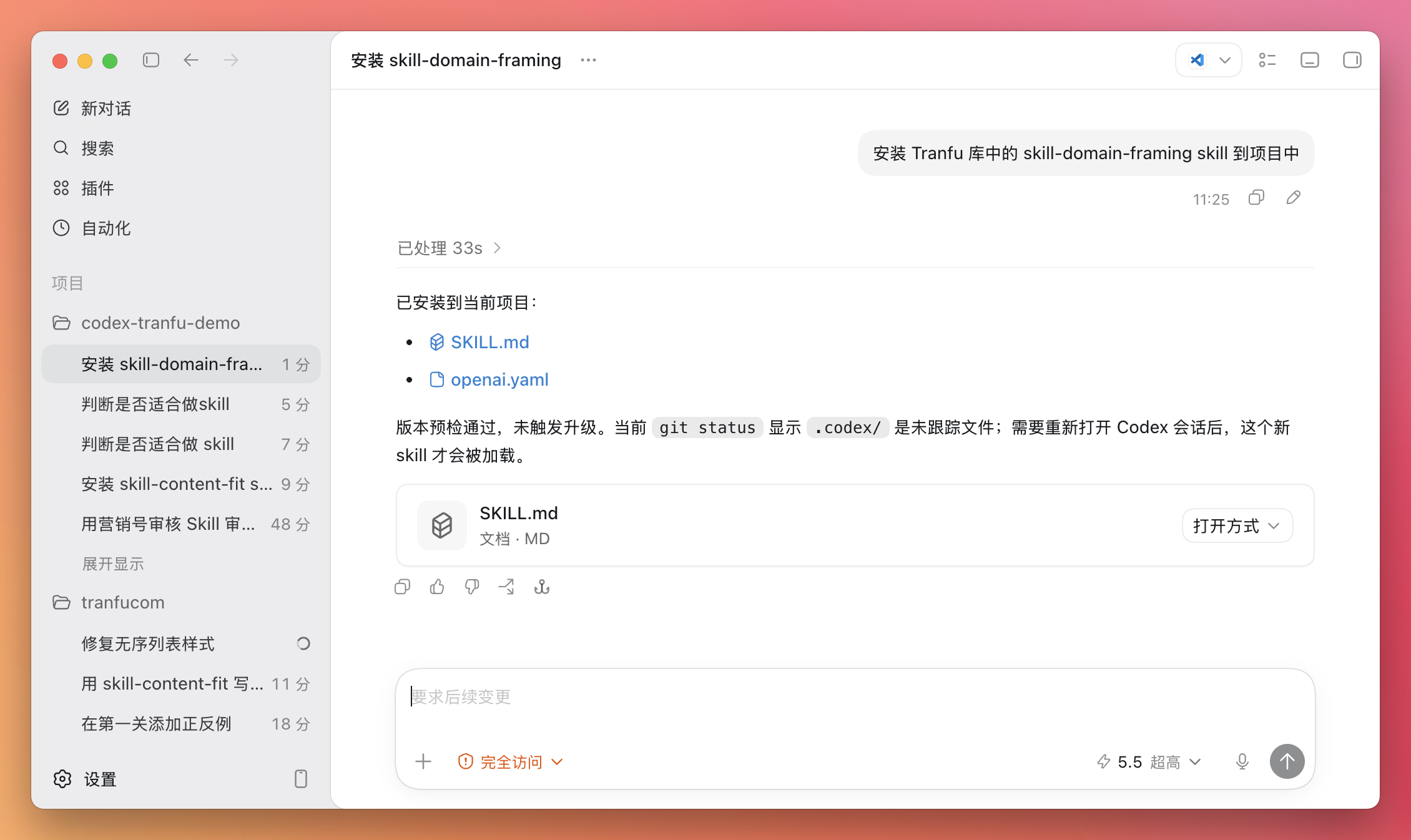
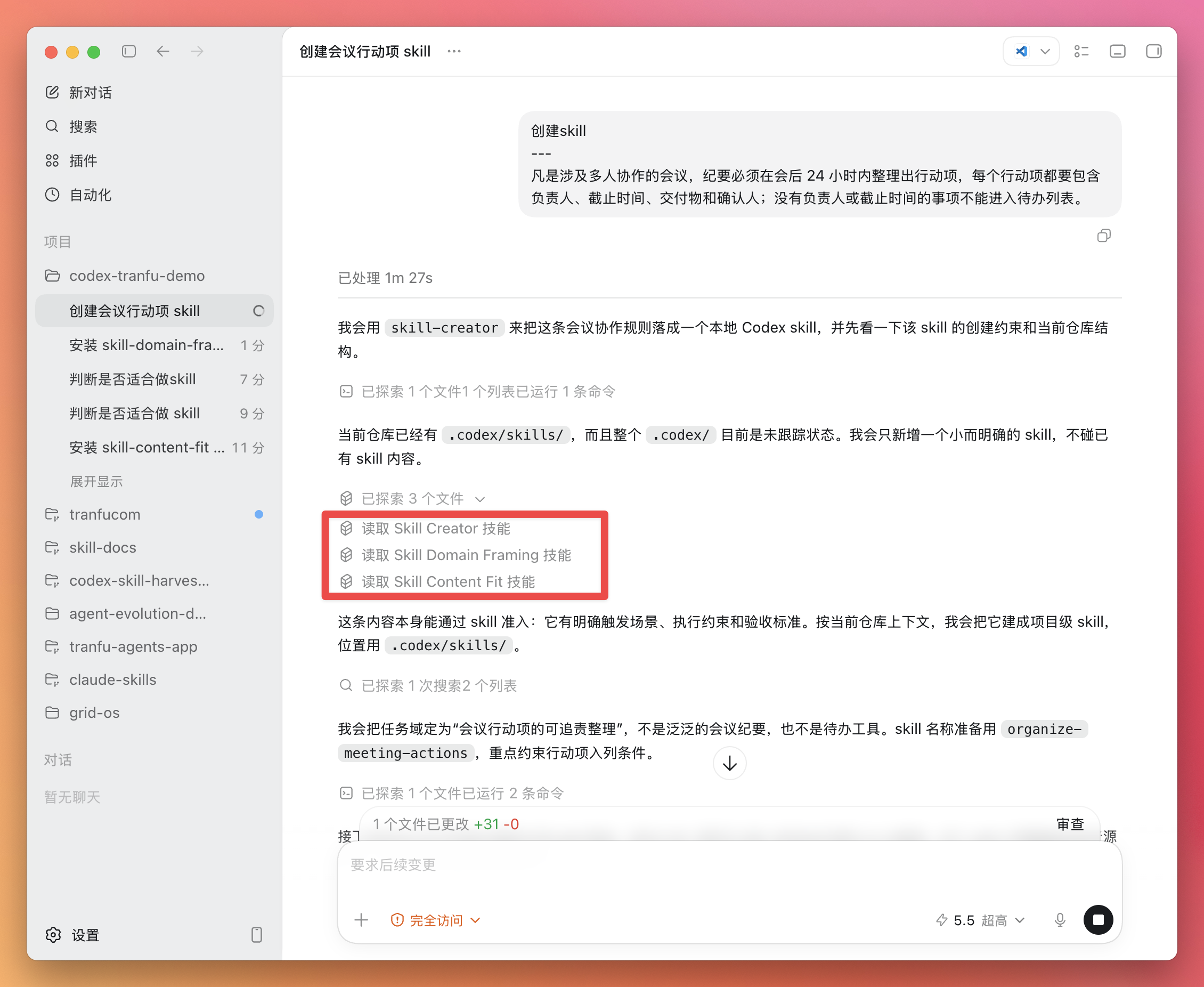
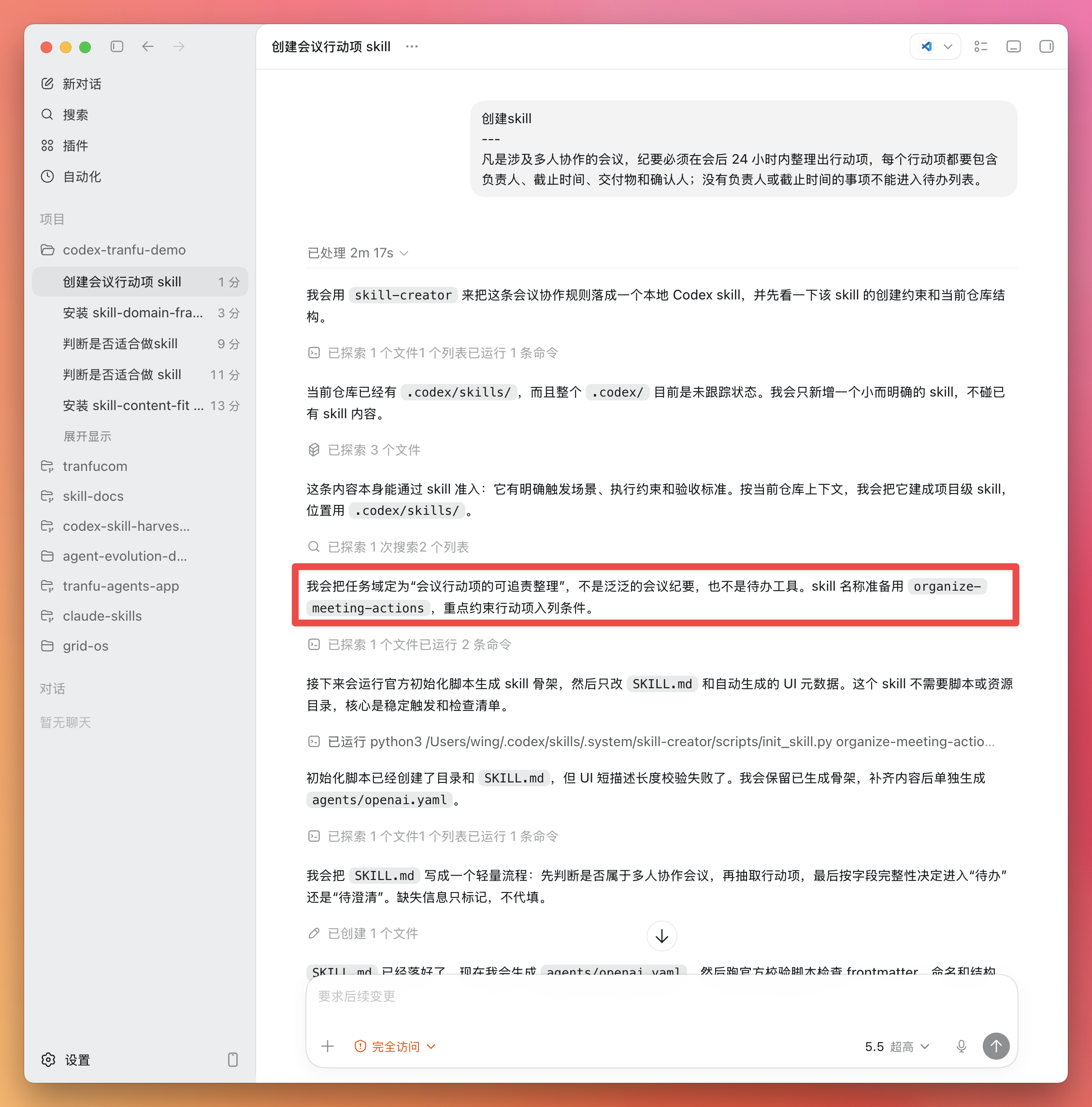
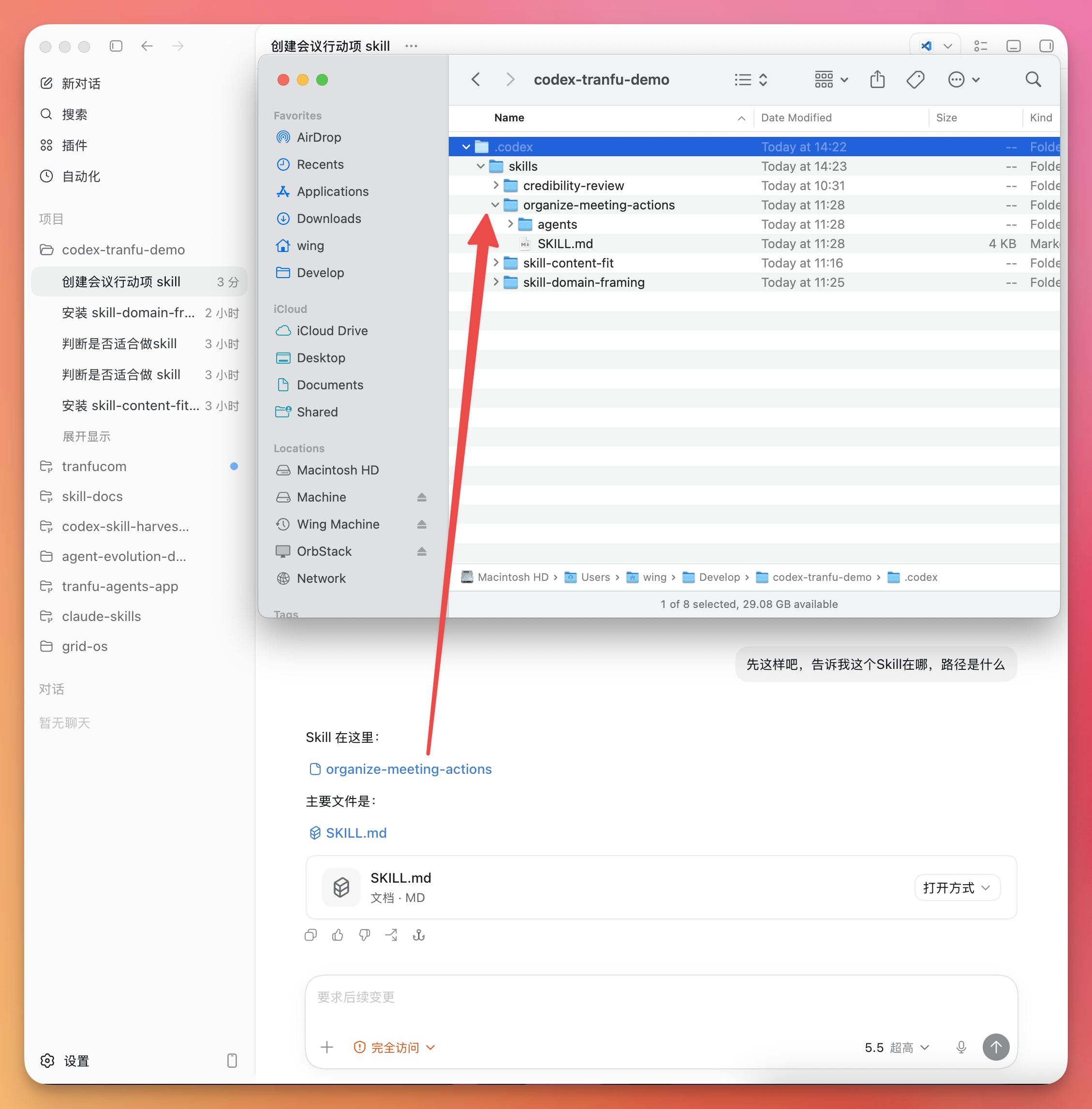
OpenClaw 联合 Claude Code 与飞书 Bot 操作完全指南
一、OpenClaw 与 Claude Code 的关系
1.1 各自定位
组件
定位
核心能力
Claude Code Anthropic 官方本地 AI 编程助手
读写代码、执行 Shell、操作 Git、处理复杂工程任务
OpenClaw 本地 AI Gateway + 渠道中枢
连接 Telegram/飞书/Discord、调度多种 AI 模型、集成飞书/日历/Gmail 等 tools
1.2 协作模式:OpenClaw → Claude Code
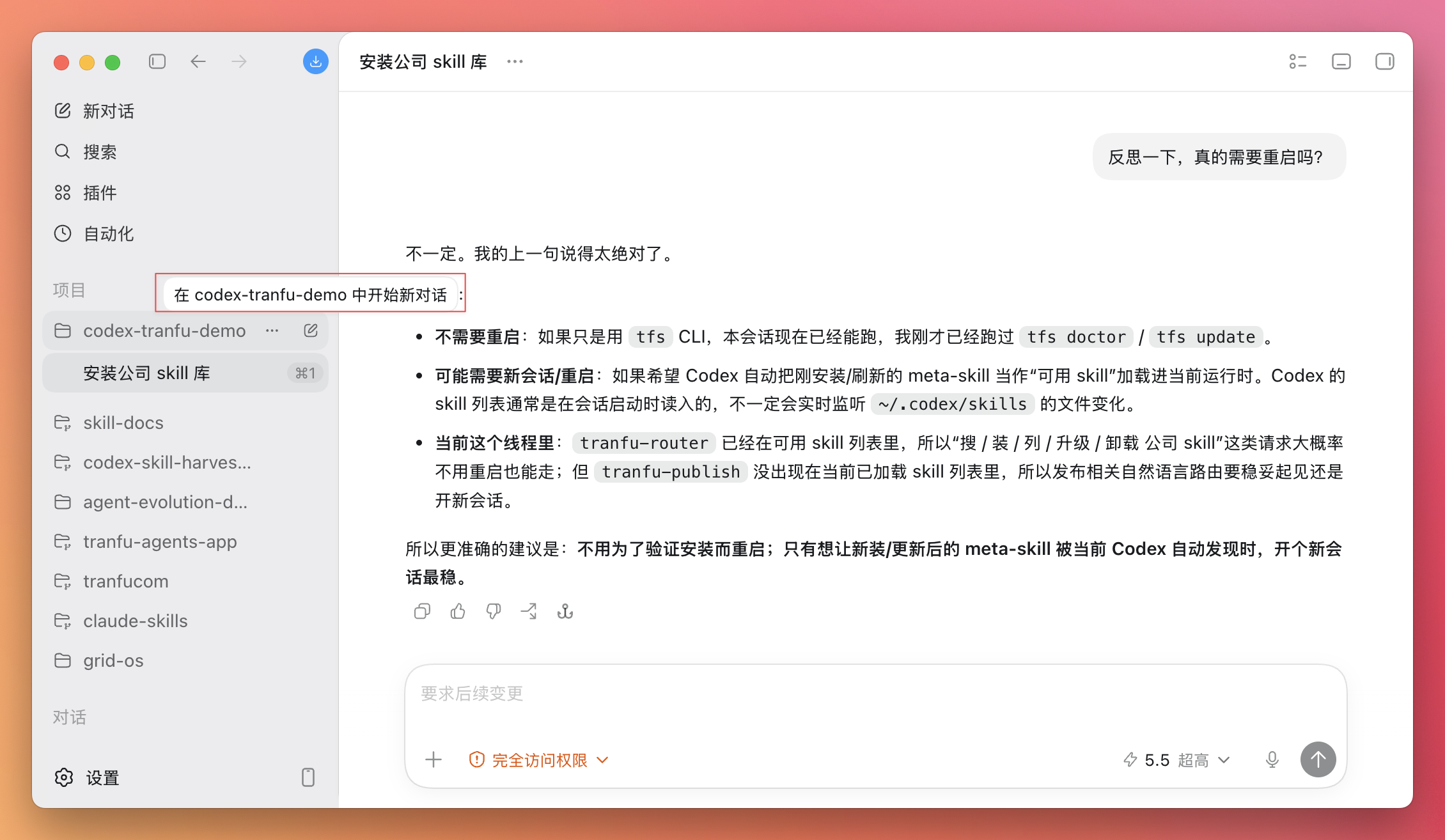
通过手机/电脑上的 Telegram 或 飞书 ,向 OpenClaw 发送指令。
OpenClaw 收到后,可以启动真正的 Claude Code CLI 作为子进程(通过 ACP 协议),让 Claude 在 Mac 上执行大型编程任务,完成后把结果返回到聊天窗口。
二、架构简图
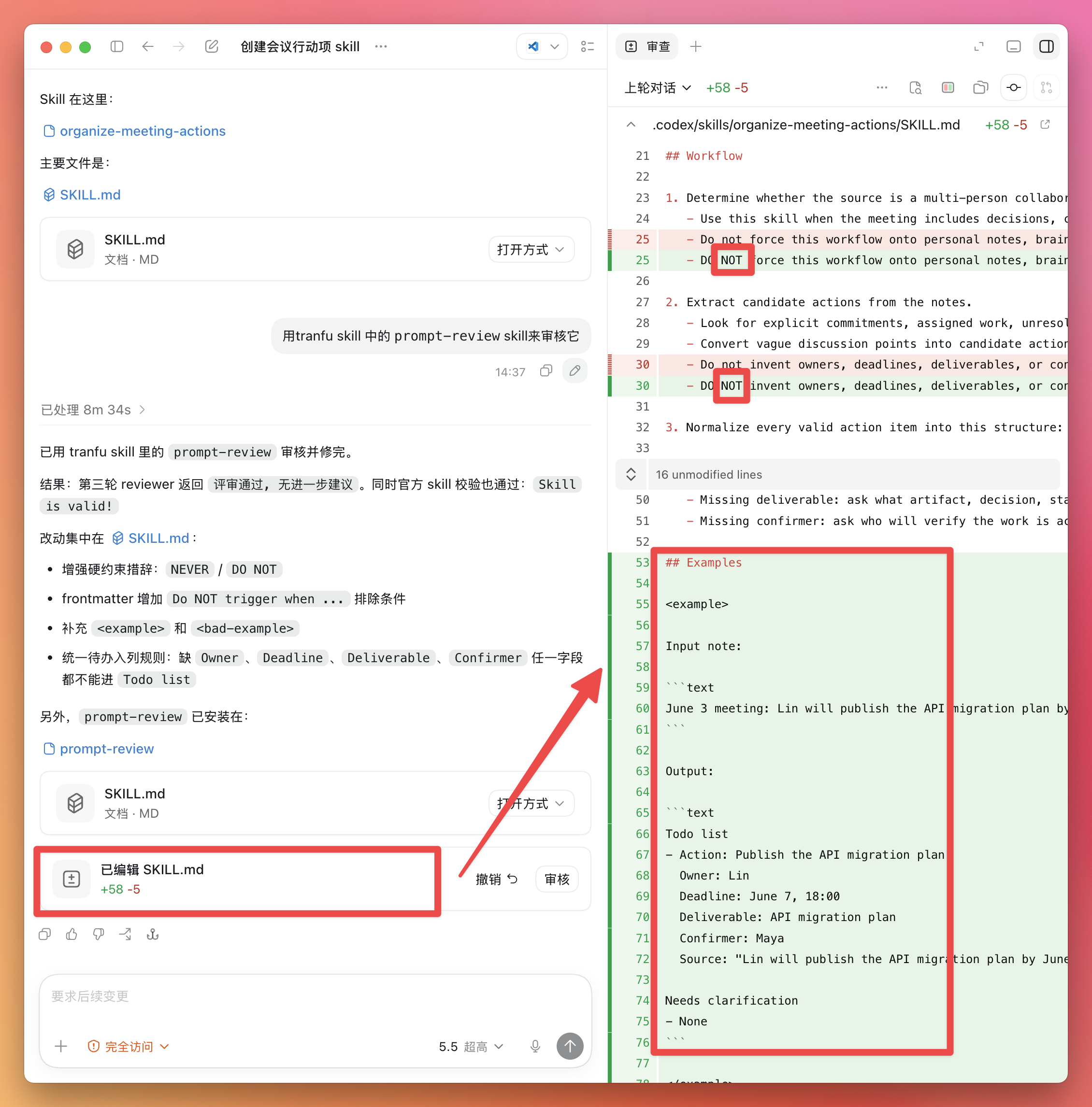
[你] → Telegram / 飞书 ↓ [OpenClaw Gateway] ← 本地运行 (127.0.0.1:18789) ↓ ┌─────┴─────┐ │ │ 飞书操作 ACP 子进程 │ │ lark-cli [Claude Code] │ │ 文档/Base 代码/Shell/Git 三、在 Telegram / 飞书中指挥 Claude Code
3.1 绑定当前聊天到 Claude
发送以下命令:
/acp spawn claude --bind here 效果:
在当前聊天中创建一个 Claude ACP 会话
之后你发的每条消息都会直接传给 Claude Code 处理
Claude 在 ~/.openclaw/workspace-claude 下工作
3.2 创建持久话题(大型任务推荐)
在支持话题/线程的渠道(如飞书群、Discord):
/acp spawn claude --mode persistent --thread auto 效果:
自动开一个话题/线程
Claude 的回复和中间过程都在这个线程里
不污染主聊天
3.3 只执行一次性任务
/acp spawn claude --mode oneshot 效果:
执行一个任务就结束
适合"帮我 review 这个 PR"、"生成一份报告"等短任务
3.4 常用 ACP 控制命令
命令
作用
/acp status查看当前聊天的 ACP 绑定状态
/acp cancel取消当前正在执行的任务
/acp close关闭 ACP 会话并解绑
/acp doctor检查 ACP 系统健康状态
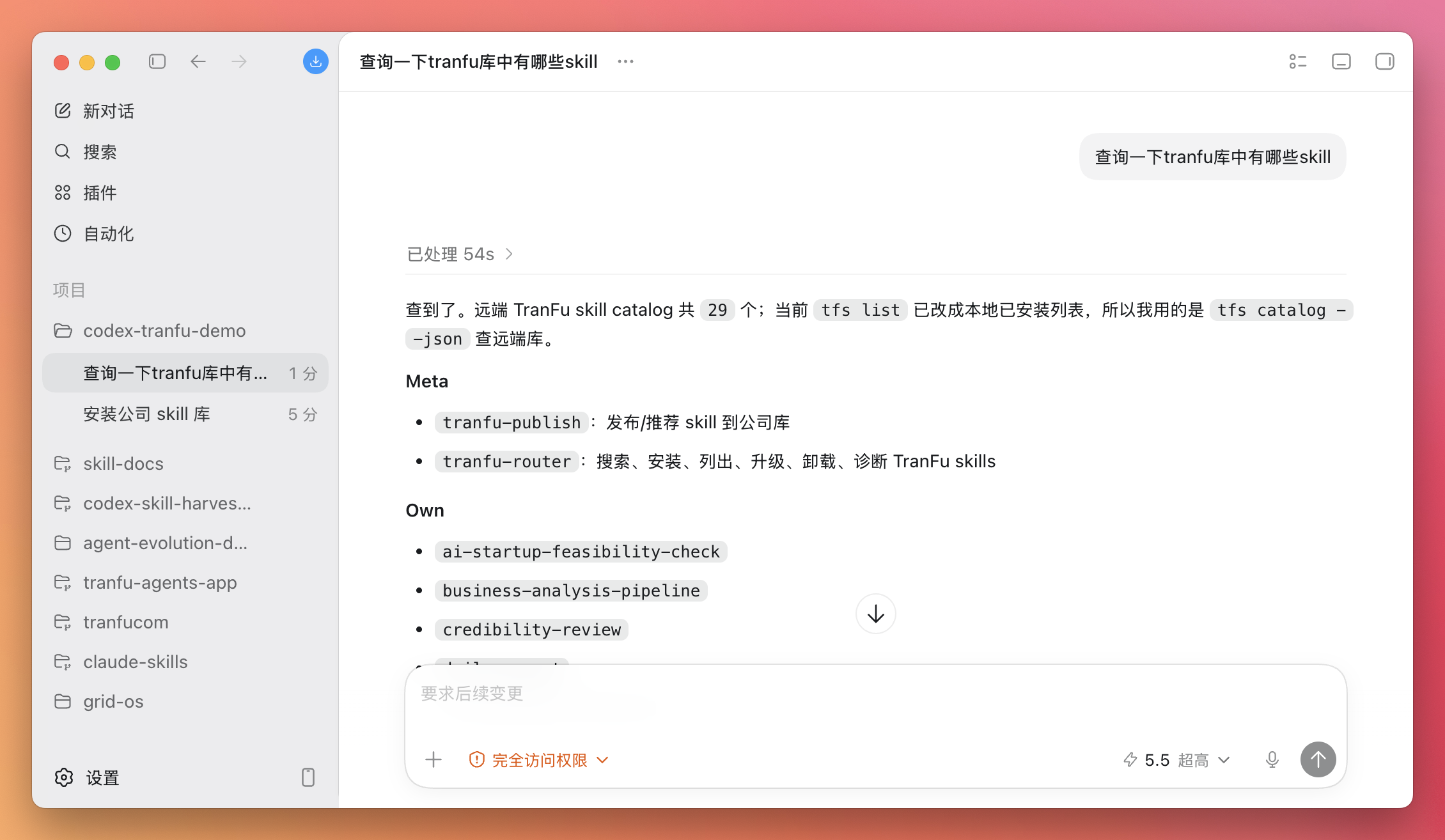
四、通过 Claude 完成飞书操作(双重能力)
4.1 关键原理
当 Claude 被 OpenClaw 通过 ACP 启动后,Claude 并不直接拥有飞书 tools 。飞书操作由 OpenClaw 的 main agent 或内置 skills 执行。
但你可以这样配合:
用 OpenClaw 直接发送 飞书消息、创建文档用 ACP 的 Claude 处理代码、生成内容再把结果交给 OpenClaw 写入飞书
4.2 实战:让 Claude 生成日报,OpenClaw 发到飞书
步骤 1 :在 Telegram 里绑定 Claude
/acp spawn claude --bind here 步骤 2 :给 Claude 派活
帮我写一份今天的研发进度日报,包含: - 已完成:修复了登录 bug - 进行中:重构订单模块 - 阻塞项:等待设计稿 Claude 生成内容后返回给你。
步骤 3 :把内容发给 OpenClaw 的 main agent
把下面这份日报发到飞书群 oc_xxxxxx: [粘贴 Claude 生成的内容] OpenClaw(main agent)会调用飞书工具完成发送。
五、Bot 身份详解
5.1 什么是 Bot 身份?
OpenClaw 连接的飞书应用是 Clawdbot (appId: cli_a94a4198e6385eef)。所有通过 OpenClaw 或 lark-cli 执行的飞书操作,默认都以这个 Bot 的租户身份 进行。
5.2 Bot 身份的优势
✅ 无需人工登录 :没有 user 会话过期问题
✅ 24小时在线 :可以自动跑定时任务
✅ 操作权限稳定 :已配置好 scopes,可读写文档、Base、IM
5.3 身份验证结果
{ "appId": "cli_a94a4198e6385eef", "brand": "feishu", "defaultAs": "bot", "identity": "bot" } 测试命令结果:
lark-cli im +chat-search --query test --as bot --page-size 1 # -> { "ok": true, "identity": "bot" } 六、Bot 身份下可执行的飞书操作类别
6.1 即时通讯(IM)
操作
示例命令/指令
发送文本消息
@bot 发送消息到群 oc_xxx:今天进度更新
发送 Markdown
@bot 用 markdown 发飞书消息...
搜索群聊
lark-cli im +chat-search --query xxx --as bot
查看历史消息
lark-cli im +chat-messages-list --chat-id oc_xxx
6.2 云文档(Docs)
操作
示例命令/指令
创建文档
@bot 在飞书里创建一个文档,标题是 xxx
更新文档
@bot 在飞书文档 doc_xxx 里追加一段内容
搜索文档
@bot 搜索飞书里标题包含 xxx 的文档
6.3 多维表格(Base)
操作
示例命令/指令
创建记录
@bot 在 Base xxx 的表 yyy 里添加一条记录
查询记录
@bot 列出 Base xxx 中状态为待办的所有记录
更新记录
@bot 把记录 zzz 的状态改成已完成
6.4 日历与任务
操作
示例命令/指令
创建日程
@bot 帮我创建一个明天下午的会议
查看日程
@bot 查看我今天的日程
创建任务
@bot 创建一个任务:周五前提交报告
七、三种典型工作流
工作流 A:纯 OpenClaw(快速操作)
适合:发消息、查日程、改 Base 记录
[你] -> Telegram message ↓ OpenClaw main agent ↓ lark-cli --as bot ↓ 飞书 API 工作流 B:纯 ACP Claude(编程任务)
适合:写代码、debug、跑测试
[你] -> /acp spawn claude --bind here ↓ Claude Code CLI ↓ 本地代码仓库 工作流 C:Claude + OpenClaw 组合(复杂自动化)
适合:Claude 生成内容 -> OpenClaw 写入飞书
[你] -> /acp spawn claude --bind here ↓ Claude 生成报告 / 分析数据 / 写脚本 ↓ [你@OpenClaw] 把结果发到飞书 ↓ OpenClaw main agent -> lark-cli bot -> 飞书 八、命令速查表
启动 Claude ACP
/acp spawn claude --bind here /acp spawn claude --mode persistent --thread auto /acp spawn claude --mode oneshot ACP 管理
/acp status /acp cancel /acp close /acp doctor 直接调用 lark-cli(Bot 身份)
lark-cli im +chat-search --query 关键词 --as bot lark-cli im +messages-send --chat-id oc_xxx --content "hello" lark-cli docs +search --query 关键词 --as bot lark-cli base +list-bases --as bot lark-cli calendar +agenda --as bot lark-cli task +get-my-tasks --as bot 九、注意事项
Bot 身份不能执行所有 user-only 操作 。例如某些通讯录搜索命令仅限 user 身份。WebChat(Control UI)不支持 thread binding ,所以 /acp spawn claude --thread auto 在 Web 控制台里会失败。
十、状态确认(2026-04-10)
检查项
状态
OpenClaw Gateway
运行中 (127.0.0.1:18789)
Telegram 渠道
已连接 (@duoer02_bot)
Feishu 渠道
已连接 (Clawdbot)
Claude Code CLI
可用 (v2.1.79)
acpx -> Claude Code
已验证通
OpenClaw ACP -> Claude
已验证通
lark-cli bot 身份
已验证通
更新时间:2026-06-01
项目状态卡
字段
内容
当前阶段
重构方向 / ready_for_scoring
优先级
P2
当前评分
54 / 100
话题发起人
罗文印([已脱敏])
当前推进人
默认同话题发起人;若后续聚焦到具体场景,再指定样例负责人
最近更新时间
2026-06-01
当前判断
这个方向有交互形态想象力,但“通用 AI Notion”过宽,且存在 thin UI 与平台替代风险。更适合收敛到一个高频工作流,例如会议纪要、团队进展、投资资讯或个人信息看板,验证卡片是否真正提升信息处理效率。
下一步
选择一个具体场景做 3-5 张可运行卡片样例,验证用户是否愿意持续使用,而不只是觉得界面新颖。
维护策略
中频更新:只有当场景收敛、样例进展、用户反馈、竞品资料或评分变化时更新。
最新进展
2026-06-01:从未建档话题中筛选为新增项目档案。该话题已有 16 条消息、13 条人类消息、3 个资源,状态为 ready_for_scoring;当前先作为“重构方向 / P2”项目沉淀,不直接进入高优先级验证。
2026-06-02:完成 01 项目档案受控区块维护:同步当前 project_key / thread_id / Base record_id / Wiki 文档链接,并按最新话题数据校验项目状态、负责人、证据链接与下一步维护边界。
执行摘要
AI 卡片式工作台 / AI Notion 的核心设想是:用“AI 输入框 + 可编程卡片 + AI 生成 HTML 模板 + 定时或 Hook 数据更新”构建通用型信息处理软件。用户可以通过对话创建股票、资讯、会议纪要、团队进展等卡片,卡片的数据来源可以是用户提示词,也可以是 AI 定时执行代码后的结果。
该方向的吸引力在于新的交互范式:AI 不只生成文本,而是生成可视化、可更新、可组合的信息单元。但当前最大问题是范围过大,容易变成“漂亮 UI 层”,被 Notion、飞书、ChatGPT、Claude Artifacts 或浏览器 Agent 吸收。
目标用户
核心痛点
AI 对话输出容易散落,缺少持续更新的结构化界面。
Notion/飞书等工具可定制,但配置成本高,普通用户难以做动态卡片。
团队信息、会议纪要、资讯流等内容需要被压缩成可扫读、可追踪的状态块。
当前证据
Lark 话题已有 16 条消息、13 条人类消息、3 个资源。
话题中已出现卡片、AI 输入框、HTML 模板、定时执行代码、会议纪要文件树、团队进展卡片、股票资讯卡片等产品元素。
已有外部参考资源,包括 kepo.ai 与 Lark 白板/文档链接。
评分与判断
当前正式评分 54 / 100,判断为“重构方向”。主要扣分来自:方向过宽、平台风险高、差异化不清、可能停留在 UI 层。加分项是交互形态清晰、可做样例、内部讨论密度较高。
MVP / 验证计划
不要先做通用平台,先选择一个场景。
做 3-5 张真实可用卡片,例如“每日投资信息卡”“项目进展卡”“会议纪要索引卡”。
验证用户是否连续 7 天打开、编辑、订阅或分享这些卡片。
验证 AI 生成卡片是否比人工配置 Notion/飞书明显省时间。
风险与反证
数据链接
字段
内容
project_key
[已脱敏]:[已脱敏]
chat_id
[已脱敏]
thread_id
[已脱敏]
Base record_id
[已脱敏]
数据口径
16 条消息 / 13 条人类消息 / 3 条 AI 分析 / 3 个资源。
项目增强分析(2026-06-02)
口径:基于最新项目维护报告、Lark 话题真实数据与可复核公开资料整理;web_search 当前不可用,因此未二次核验的市场判断均按“趋势/假设”保守处理。
project_id: ai_card_workspace
一句话机会
做一个“AI 输入框 + 可组合卡片”的个人/团队信息工作台,让用户用自然语言生成、更新和调度信息卡片,把分散的资讯、会议、项目、数据和提醒变成可操作的动态页面。
目标用户
小团队负责人、产品经理、投资/研究人员、运营负责人。
日常需要处理多来源信息:聊天、会议纪要、网页、任务、市场数据、项目进展。
已经使用 Notion、飞书、多维表格、Slack/飞书群、Tana/Heptabase/Obsidian,但信息仍然分散的人。
核心痛点
Notion/飞书等通用工作台强在结构化,但用户仍需手动建库、维护字段、同步信息。
聊天式 AI 强在生成,但结果难以长期沉淀成可复用视图。
项目/研究/运营信息不是一篇文档,而是一组不断变化的状态卡片。
用户想要“我说一句话,系统自动生成卡片、更新卡片、提醒我下一步”。
当前证据
内部话题数据
project_id:ai_card_workspace
current_status:重构方向 / ready_for_scoring;优先级 P2;更新策略 medium。
Wiki:JwBBwB3JAilGjskAQNFlOXxegEg;Doc:Vb4YdJitXoWgeXxtDNCltmkxgVi。
话题负责人:罗文印。
消息/资源:16 / 3。
最近内部摘要:项目定位为“AI Native 信息处理软件”,用“卡片 + AI 输入框”创建和展示股票、资讯、会议纪要、团队进展等信息;数据来源既可以是用户提示词,也可以是 AI 定时执行代办。
维护报告提示:当前只拿到本地沉淀/日报/评分记录,未拿到完整逐条聊天原文,需要 best-effort。
外部资料与趋势
Notion AI 官网定位为“Search, generate, analyze, and chat—right inside Notion”,说明 AI 工作台正在从文档生成走向工作空间级搜索、分析和对话。
ClickUp Brain² 官网定位为“One AI to Replace them All”,强调工作上下文聚合和跨任务 AI。
市场趋势是“AI 嵌入现有工作台”与“Agent 执行任务”并行,纯新工作台必须有强差异化:更低建模成本、更强动态卡片、更适合移动端/群聊入口。
竞品 / 替代方案
工作空间:Notion AI、Coda AI、Airtable AI、飞书多维表格/飞书妙记/知识库。
项目管理 AI:ClickUp Brain、Asana AI、Monday AI。
知识管理:Tana、Mem、Reflect、Heptabase、Obsidian + 插件。
AI 搜索/研究:Perplexity Spaces、Genspark、You.com、Kimi/豆包资料整理。
内部替代:直接用飞书 Base + Wiki + 小满 bot 做项目雷达。
MVP 切口
推荐切“项目/机会雷达卡片工作台”,先服务现有 Opportunity Hub 场景:
用户在群里发一个想法,AI 自动生成项目卡片。
卡片包含:一句话机会、状态、评分、证据、下一步、风险、来源链接。
卡片可被自然语言更新:“把这个项目改成 P1”“补一个竞品”“今天有什么新信号”。
先不做完整 Notion,做“动态项目卡片 + 每日更新 + 评分流转”。
验证方式
用现有 Opportunity Hub 做 dogfood,替代当前人工维护项目档案的部分流程。
指标:创建卡片耗时、项目状态更新准确率、团队查看/引用次数、每周被动维护减少时间。
找 3 个外部小团队试用:投资研究、产品工作室、内容团队。
观察用户是否愿意把真实项目数据放入卡片,而不是只当 demo 玩具。
风险与反证
与 Notion/飞书/ClickUp 正面竞争,独立产品壁垒不足。
“卡片”是交互形态,不是需求本身;如果没有明确任务流,容易变成视觉包装。
数据接入和权限管理复杂,MVP 不能一开始就追求全连接。
若用户最终仍回到 Notion/飞书,只把产品当生成器,则应转向插件/工作流,而不是独立工作台。
下一步
进入 ready_for_scoring 的正式评分,但评分对象应是“Opportunity Hub 项目卡片工作台”,不是泛 AI Notion。
画 5 张核心卡片模板:项目档案、信号、竞品、实验、日报。
用本 workspace 的项目档案维护流程做第一个 MVP 数据源。
参考来源链接
维护边界:本章节为 2026-06-02 增强分析受控块;后续若有新客户验证、竞品变化或 Lark 话题进展,可替换本章节,不覆盖原始档案正文。
项目质量升级(2026-06-03)
口径:本章节用于替换昨日偏模板化的增强稿表达;基于 Lark 话题真实数据、项目 mapping、既有维护报告与公开竞品格局,强调判断、边界、验证和反证。不覆盖原文其它章节。
project_id: ai_card_workspace
当前判断
这个项目需要重构叙事。若叫“AI Notion”,会天然进入 Notion、飞书、ClickUp、Airtable 的正面战场,风险很高。更合理的判断是:卡片不是产品本身,卡片必须绑定具体任务流。
当前最好的 MVP 不是泛工作台,而是复用团队内部已有 Opportunity Hub 场景,做 项目/机会雷达卡片工作台 :让群聊中的想法自动沉淀成项目卡片,持续更新证据、评分、风险和下一步。
当前状态应保持为:P2,重构方向 / ready_for_scoring;先评分“项目卡片工作台”,不要评分“泛 AI Notion”。
真实内部话题数据
项目名:AI 卡片式工作台 / AI Notion
project_id:ai_card_workspace
Wiki / Doc:JwBBwB3JAilGjskAQNFlOXxegEg / Vb4YdJitXoWgeXxtDNCltmkxgVi
Lark thread:[已脱敏]
阶段 / 优先级:重构方向 / ready_for_scoring;P2
更新策略:medium
负责人:罗文印
数据来源:snapshot
消息 / 资源:16 条消息 / 3 个资源
维护门禁:PASS
最近话题脉络:用户要求小满检查本话题讨论并总结分析;小满说明当前只拿到本地沉淀/日报/评分记录,未拿到完整逐条聊天原文,best-effort 总结为“AI Native 信息处理软件”:用卡片 + AI 输入框创建股票、资讯、会议纪要、团队进展等信息;数据来源可来自用户提示词或 AI 定时执行代办。
证据等级:L2(有内部连续讨论和概念沉淀,但原始逐条证据不完整,尚未有外部用户/付费验证)
外部竞品 / 替代方案
Notion AI :强在文档、数据库、知识库和 AI 搜索/生成;用户心智强,是最大正面竞品。
Coda AI / Airtable AI :强在结构化数据、自动化和团队工作流。
飞书多维表格 / Wiki / 妙记 :对国内团队是天然替代,尤其已经在飞书内办公的组织。
ClickUp Brain / Asana AI / Monday AI :项目管理上下文强,AI 能围绕任务、文档、进展工作。
Tana / Mem / Reflect / Heptabase / Obsidian 插件 :知识管理和个人信息结构化替代。
Perplexity Spaces / Genspark / Kimi / 豆包资料整理 :研究、搜索、资料问答替代。
内部替代 :当前 Opportunity Hub 已经由 Lark 群 + 小满 bot + Wiki + Base + 项目档案维护脚本组合实现。新产品必须证明比这套拼装流程更省维护、更易查看。
MVP 做什么
MVP:Opportunity Hub 项目卡片工作台。
围绕一个具体任务:从群聊机会到项目卡片,再到状态更新和下一步行动。
首版卡片类型只做 5 种:
项目档案卡:一句话机会、状态、负责人、优先级、评分。
信号卡:内部消息、外部资源、用户反馈、竞品变化。
竞品卡:竞品名称、定位、差异点、来源链接。
实验卡:7/14 天验证计划、指标、结果。
日报卡:今日新增、状态变化、阻塞、建议。
交互:用户在群里说“把这个想法建卡”“补一个竞品”“今天有什么新信号”“把它改成 P1 待验证”,系统更新卡片并保留来源。
MVP 不做什么
不做泛 Notion 替代品。
不做完整数据库搭建器。
不做全类型卡片市场。
不接所有外部数据源;首版只接当前 workspace / Lark 话题 / 本地报告。
不做复杂权限体系;先在内部 dogfood。
不做移动端精美 UI 优先,先验证卡片是否减少维护成本。
不让“卡片视觉”掩盖任务流;每张卡必须能回答“谁下一步做什么”。
7 天验证计划
Day 1:画出 5 张核心卡片模板:项目档案、信号、竞品、实验、日报。
Day 2:选 4 个现有项目作为样例:GEO/AEO、AI 招聘工具、交互式知识书、AI 卡片工作台自身。
Day 3:用本地 Markdown/JSON 生成静态卡片页面或报告,不做完整前端。
Day 4:让团队用自然语言提出 10 条更新指令,例如“补竞品”“改状态”“生成 7 天计划”。
Day 5:测试系统是否能正确定位卡片、保留来源、更新字段。
Day 6:对比当前人工维护项目档案流程,记录建卡和更新耗时。
Day 7:团队评审:是否比 Wiki 长文更适合日常项目查看。
7 天通过门槛 :建一张项目卡耗时减少 ≥ 50%;10 条更新指令中 ≥ 8 条能正确落到对应卡片;团队至少 2 人认为它比当前 Wiki/报告更适合日常跟进。
14 天验证计划
Week 2 前 3 天:接入每日项目维护 dry-run 输出,把状态、消息/资源数、门禁、最新摘要自动转成卡片。
Week 2 第 4-5 天:让团队连续 3 天用卡片看项目进展,而不是只看长文报告。
Week 2 第 6 天:邀请 1-2 个外部小团队看 demo,尤其是投资研究、产品工作室、内容团队。
Week 2 第 7 天:判断产品形态:独立工作台、飞书插件、还是 Opportunity Hub 内部能力。
14 天通过门槛 :内部团队真实引用卡片做决策;项目维护时间明显下降;外部团队能理解“群聊想法 → 动态卡片”的价值,而不是只觉得 UI 好看。
风险反证
如果用户说“这就是 Notion/飞书多维表格换皮”,说明差异化不足。
如果卡片只能展示信息,不能推动更新和下一步行动,就只是可视化包装。
如果自然语言更新经常改错项目或丢失来源,用户会回到人工维护。
如果内部 Opportunity Hub 都无法形成高频使用,外部商业化更不应推进。
如果真正价值来自小满 bot 的分析能力,而不是卡片工作台,应把它做成 bot + Wiki/Base 的增强模块,不做独立产品。
下一步
将评分对象改名为“Opportunity Hub 项目卡片工作台”。
先用本地报告生成 5 类卡片,不做外部写入。
用 4 个现有项目 dogfood,测建卡和更新耗时。
14 天后决定:独立产品、飞书插件、还是内部运营系统能力。
维护边界:本章节为 2026-06-03 质量升级受控块;后续新证据出现时可整体替换本章节。
维护说明
更新时间:2026-06-01
项目状态卡
字段
内容
当前阶段
继续收集场景
优先级
P3
当前评分
待正式评分
话题发起人
待从 Lark 话题 root sender 回填
当前推进人
待补上下文;默认同话题发起人
最近更新时间
2026-06-01
当前判断
该方向目前在优先项目看板中存在记录,但本地 recent topic snapshot 暂未拿到对应消息。先建“待补上下文”项目档案,防止看板有项目但 Wiki 无档案。
下一步
补拉 Lark thread 完整消息,确认原始需求、发起人、目标用户、治理场景、国产模型适配范围和可验证 MVP。
维护策略
低频更新:先补齐 thread 原文、owner 和证据;未补齐前不进入自动写入。
最新进展
执行摘要
该方向目前在优先项目看板中存在记录,但本地 recent topic snapshot 暂未拿到对应消息。先建“待补上下文”项目档案,防止看板有项目但 Wiki 无档案。
本档案的首要价值是打通“看板记录 → Wiki 项目档案 → 后续维护”的链路,而不是替代完整研究报告。后续补齐原始话题后,应按项目档案标准补充目标用户、核心痛点、当前证据、MVP / 验证计划、风险与反证。
目标用户
待补:需从 Lark thread 原文和后续讨论中确认。
核心痛点
待补:需从原始需求、用户场景和替代方案中提炼。
当前证据
评分与判断
当前优先级:P3;正式评分:待正式评分。该评分来自优先项目看板,后续如有更新,应先进入 Score History 或看板,再回写项目档案。
MVP / 验证计划
补拉 Lark thread 完整消息,确认原始需求、发起人、目标用户、治理场景、国产模型适配范围和可验证 MVP。
风险与反证
缺少 thread 原文时,不能把看板标题误认为完整项目定义。
若补拉后发现只是单条灵感且无连续讨论,应保持低优先级观察。
若无法定义目标用户、痛点和验证动作,不应进入正式验证阶段。
数据链接
字段
内容
project_key
[已脱敏]:[已脱敏]
thread_id
[已脱敏]
Base record_id
[已脱敏]
数据口径
来自优先项目看板;thread 原文待补拉。
项目增强分析(2026-06-02)
口径:基于最新项目维护报告、Lark 话题真实数据与可复核公开资料整理;web_search 当前不可用,因此未二次核验的市场判断均按“趋势/假设”保守处理。
project_id: ai_copilot_model_governance
基础信息
project_id:ai_copilot_model_governance
Wiki node:PmVywvIQviFNqPkIbbFlNE45g7b
Doc token:D2WJdRDifo0lBlxhHLjlaaPrgcf
Base record:[已脱敏]
Lark thread:[已脱敏]:[已脱敏]
current_status:继续收集场景 / P3
负责人:亚洲詹姆斯([已脱敏])
内部话题数据:最新维护报告显示数据来源为 mapping,消息/资源 0 / 0;当前本地 snapshot 未拿到对应 thread 原文。
一句话机会
为使用国产大模型和多模型 Copilot 的团队提供一层“治理型 Copilot 控制台”:统一标注 API、工具、数据、权限、审计、成本与安全状态,让 AI 应用从“能跑”升级为“可观测、可追责、可治理”。
目标用户
已经在内部使用国产大模型/私有化模型/多模型 API 的中小技术团队。
有合规、审计、安全要求的企业 AI 应用负责人、IT 管理员、数据安全负责人。
正在把 AI Copilot 接入业务系统、知识库、工具调用、RAG、Agent 的产品/工程团队。
核心痛点
模型与工具调用黑盒化 :谁调用了哪个模型、用了什么工具、访问了哪些数据、输出是否有风险,缺少统一记录。
国产模型/多模型治理分散 :不同供应商 API、私有模型、开源模型、代理网关各自有日志和权限,难以形成统一视图。
安全与审计后置 :许多团队先把 Copilot 跑起来,再补审计、权限、脱敏、合规,后期改造成本高。
业务负责人看不懂技术日志 :工程日志多,但缺少面向管理/安全/业务的状态标注和风险说明。
当前证据
内部话题数据
外部资料与趋势
LLM Observability / LLMOps 已形成明确工具层:Langfuse、Arize Phoenix、Helicone 等围绕 tracing、prompt/response 记录、评测、成本与质量监控切入。
LLM Gateway / AI Gateway 正在承担模型路由、成本控制、访问控制、日志与缓存能力,LiteLLM、Portkey、Cloudflare AI Gateway 是典型方向。
企业 AI 安全治理工具在 prompt injection、防泄漏、内容安全、PII 识别、审计方面增强,Lakera Guard、NVIDIA NeMo Guardrails、Guardrails AI 等代表“护栏”路线。
国内模型生态碎片化更强:通义千问、文心、豆包、智谱、DeepSeek、MiniMax、Moonshot 以及本地化部署并存,给统一治理层留下空间。
竞品/替代方案
LLM 可观测 / tracing :Langfuse、Arize Phoenix、Helicone。优势是开发者友好;短板是更偏技术监控,不一定覆盖国产模型、企业审计和管理视图。
LLM Gateway :LiteLLM、Portkey、Cloudflare AI Gateway。优势是路由/成本/日志;短板是“治理解释层”和业务安全状态不一定完整。
AI 安全护栏 :Lakera Guard、NVIDIA NeMo Guardrails、Guardrails AI。优势是安全策略;短板是与企业内部工具/API/数据资产状态联动不足。
企业内部自建日志 + 权限系统 :成本低但难维护,容易只解决局部日志,无法形成标准化项目档案和审计报告。
MVP 切口
建议不要一开始做“完整 AI 治理平台”,先切 国产模型 Copilot 治理看板 + 审计报告生成器 :
接入 2-3 个模型供应商或代理网关,记录请求、模型、应用、用户、token、费用、响应摘要。
对每次 Copilot 调用标注:是否调用工具、是否访问数据源、是否命中敏感词/PII、是否需要人工复核。
输出面向管理者的日报/周报:异常调用、敏感调用、成本峰值、失败率、高风险 prompt、模型使用分布。
支持国产模型标签:供应商、模型版本、是否私有化、数据出境风险、合规备注。
验证方式
找 3 个已接入大模型 API 的小团队做访谈:是否有“谁用了什么模型/工具/数据”的审计痛点。
用现有内部 bot / agent 流量做 dogfood:先接入 OpenClaw/Lark bot 的 LLM 调用日志,生成治理周报。
验证指标:一周内是否能发现至少 3 类真实问题(异常成本、敏感内容、失败调用、工具误用);安全/管理负责人是否愿意每周查看报告。
风险与反证
如果目标团队只有少量 AI 调用,Excel/日志已够用,则平台化价值不足。
如果用户真正需要的是“模型网关”而非“治理看板”,会直接转向 LiteLLM/Portkey 等成熟工具。
企业合规采购周期长,P3 状态合理;需要先用内部工具/开源插件方式验证。
国产模型适配若只做 API 包装,壁垒较低;必须沉淀治理语义、审计模板和安全工作流。
下一步
补拉 Lark thread 原文,确认具体发起语境、目标用户和“国产模型”的范围。
用内部 AI 调用链路做一个只读审计看板样例。
输出一版“AI Copilot 治理周报”模板,拿给潜在用户判断是否有价值。
参考来源链接
维护边界:本章节为 2026-06-02 增强分析受控块;后续若有新客户验证、竞品变化或 Lark 话题进展,可替换本章节,不覆盖原始档案正文。
项目质量升级(2026-06-03)
口径:本章节用于替换昨日偏模板化的增强稿表达;基于 Lark 话题真实数据、项目 mapping、既有维护报告与公开竞品格局,强调判断、边界、验证和反证。不覆盖原文其它章节。
project_id: ai_copilot_model_governance
当前判断
这个项目的方向听起来专业且可能真实,但当前证据不足。看板里有项目、标题里有需求线索:“治理国产模型 + 治理层 co-pilot 方案,标注 API/工具/数据/审计状态。安全可观测”;但维护报告显示消息/资源为 0/0,数据来源为 mapping,未拿到 thread 原文。
所以它不应该被包装成已验证企业治理机会。当前更合适的状态是:P3,继续收集场景;先内部 dogfood,不商业立项。
如果要保留,应把它定义为“AI 调用治理周报 / 审计看板”,而不是完整治理平台。用内部 OpenClaw / Lark bot 的调用链路先验证:能不能发现真实异常、成本浪费、敏感调用、工具误用。
真实内部数据
标题:AI copilot 治理国产模型 + 治理层 co-pilot 方案,标注 API/工具/数据/审计状态。安全可观测
project_id:ai_copilot_model_governance
Wiki / Doc:PmVywvIQviFNqPkIbbFlNE45g7b / D2WJdRDifo0lBlxhHLjlaaPrgcf
Lark thread:[已脱敏]
阶段 / 优先级:继续收集场景;P3
更新策略:low
负责人:亚洲詹姆斯
数据来源:mapping
消息 / 资源:0 条消息 / 0 个资源
证据等级:L0/L1(只有看板标题,无可复核话题原文)
为什么暂缓
暂缓不是因为方向不重要,而是因为现在无法回答三个关键问题:
目标用户是谁:CTO、安全负责人、AI 平台负责人、业务负责人,还是开发者?
真实痛点是什么:成本、合规、国产模型适配、工具调用审计、数据出境、还是 prompt 风险?
采购/使用形态是什么:开源插件、内部看板、网关、审计报告,还是企业平台?
没有这些答案,直接做会变成“LLMOps / Gateway / Guardrails / BI 看板”的混合体。
竞品 / 替代
LLM Observability :Langfuse、Arize Phoenix、Helicone。强在 tracing、prompt/response、成本、质量评估。
LLM Gateway :LiteLLM、Portkey、Cloudflare AI Gateway。强在路由、缓存、日志、限流、成本控制。
AI 安全护栏 :Lakera Guard、NVIDIA NeMo Guardrails、Guardrails AI。强在注入攻击、防泄漏、结构化输出和安全策略。
企业自建日志/权限系统 :低成本但碎片化,通常缺管理视图和审计解释。
国内云/模型平台控制台 :通义、火山、百度、智谱等平台的用量/安全能力,会覆盖一部分基础治理。
MVP 边界
推荐 MVP:AI Copilot 治理周报 + 只读审计看板 。
只做:
接入一条内部 AI 调用链路,记录应用、用户、模型、token、费用、失败率。
标注是否调用工具、访问数据源、出现敏感词/PII、触发人工复核。
输出周报:成本峰值、异常失败、敏感调用、工具误用、模型分布、Top prompt 类型。
支持国产模型标签:供应商、模型版本、是否私有化、数据出境/合规备注。
明确不做:
验证计划
内部 dogfood 7 天
外部访谈 5 个团队
问他们是否有多模型使用、国产模型适配、日志审计、安全复核需求。
要求对方展示当前怎么查“谁用了哪个模型、访问了什么数据、花了多少钱”。
判断他们愿意买的是网关、审计报告、治理看板,还是安全护栏。
风险反证
如果内部 dogfood 一周发现不了真实问题,说明当前团队规模下不需要独立治理工具。
如果用户更想要 LiteLLM/Portkey 的 gateway,而不是治理报告,应转向集成/模板,不做独立产品。
如果安全负责人只认可已有企业安全平台,独立小工具很难进入采购。
如果国产模型差异只是 API 适配问题,壁垒低。
如果必须处理敏感业务数据才能产生价值,早期落地成本会显著上升。
下一步
补拉 Lark thread 原文;没有原文前不升级状态。
用内部 bot 日志做一版“AI Copilot 治理周报”样例。
和 team_api_key_management 合并评估:二者可能同属“团队 AI 使用治理”大方向。
若 5 个团队访谈都无明确治理痛点,降级为技术组件观察。
维护边界:本章节为 2026-06-03 质量升级受控块;后续新证据出现时可整体替换本章节。
维护说明
更新时间:2026-06-01
项目状态卡
字段
内容
当前阶段
待轻量研究
优先级
P2
当前评分
待正式评分
话题发起人
待从 Lark 话题 root sender 回填
当前推进人
待补上下文;默认同话题发起人
最近更新时间
2026-06-01
当前判断
团队 API Key 管理已进入优先项目看板,属于内部工具/治理方向候选。当前需要补齐原始话题证据,避免与其他话题串题。
下一步
补拉 Lark thread 完整消息,确认需求是否为团队大模型 Key 治理、授权分发、审计和成本控制,并补竞品/替代方案。
维护策略
低频更新:先补齐 thread 原文、owner 和证据;未补齐前不进入自动写入。
最新进展
执行摘要
团队 API Key 管理已进入优先项目看板,属于内部工具/治理方向候选。当前需要补齐原始话题证据,避免与其他话题串题。
本档案的首要价值是打通“看板记录 → Wiki 项目档案 → 后续维护”的链路,而不是替代完整研究报告。后续补齐原始话题后,应按项目档案标准补充目标用户、核心痛点、当前证据、MVP / 验证计划、风险与反证。
目标用户
待补:需从 Lark thread 原文和后续讨论中确认。
核心痛点
待补:需从原始需求、用户场景和替代方案中提炼。
当前证据
评分与判断
当前优先级:P2;正式评分:待正式评分。该评分来自优先项目看板,后续如有更新,应先进入 Score History 或看板,再回写项目档案。
MVP / 验证计划
补拉 Lark thread 完整消息,确认需求是否为团队大模型 Key 治理、授权分发、审计和成本控制,并补竞品/替代方案。
风险与反证
缺少 thread 原文时,不能把看板标题误认为完整项目定义。
若补拉后发现只是单条灵感且无连续讨论,应保持低优先级观察。
若无法定义目标用户、痛点和验证动作,不应进入正式验证阶段。
数据链接
字段
内容
project_key
[已脱敏]:[已脱敏]
thread_id
[已脱敏]
Base record_id
[已脱敏]
数据口径
来自优先项目看板;thread 原文待补拉。
项目增强分析(2026-06-02)
口径:基于最新项目维护报告、Lark 话题真实数据与可复核公开资料整理;web_search 当前不可用,因此未二次核验的市场判断均按“趋势/假设”保守处理。
project_id: team_api_key_management
基础信息
project_id:team_api_key_management
Wiki node:JHEownWgeihCtukWz8jluxuAgth
Doc token:VubOdWQLYoiWZ0xY2khl5Efxgfd
Base record:[已脱敏]
Lark thread:[已脱敏]:[已脱敏]
current_status:待轻量研究 / P2
负责人:[已脱敏]
内部话题数据:最新维护报告显示数据来源为 mapping,消息/资源 0 / 0;但其他维护报告中捕获到一次相关市场研究摘要。
一句话机会
为小团队提供“团队大模型 API Key 治理 + 订阅授权分发 + 成本审计”工具,让成员不用共享主 Key,也能按人、项目、模型、预算安全使用 AI 服务。
目标用户
10-200 人的 AI 创业团队、外包开发团队、产品/运营团队。
已经购买 OpenAI/Claude/Gemini/DeepSeek/通义/豆包等多模型 API 或订阅额度,但内部共享混乱的团队。
需要控制成本、权限、供应商切换和滥用风险的 CTO、技术负责人、财务/运营负责人。
核心痛点
Key 共享风险 :主 Key 在群里、文档里、代码里流转,离职成员、外包、临时账号都可能继续使用。
成本不可控 :不知道哪个人、哪个项目、哪个模型烧钱;月底账单才发现异常。
权限粗糙 :无法给不同成员配置模型白名单、预算上限、速率限制、有效期。
多供应商管理复杂 :OpenAI、Anthropic、Google、DeepSeek、通义、豆包等 Key 和额度分散。
团队订阅无法细粒度分发 :很多团队有共享订阅/额度,但缺少“内部虚拟 Key + 审计”的管理层。
当前证据
内部话题数据
外部资料与趋势
LiteLLM 已提供 virtual keys、budgets、rate limits、团队管理、模型路由等能力,说明“虚拟 Key + 预算 + 网关”是成熟需求。
Portkey、Helicone、Cloudflare AI Gateway 等在网关、日志、缓存、成本和可观测方向竞争激烈。
传统 secret 管理工具如 1Password、Doppler、HashiCorp Vault 更偏密钥存储和 DevOps,不直接解决 LLM 调用成本/模型路由/成员预算。
AI 应用团队从“个人 API Key”进入“团队额度管理”阶段,尤其多模型并用后,统一管理需求增强。
竞品/替代方案
LiteLLM Proxy :强竞品,覆盖模型代理、virtual keys、预算、日志、路由,适合技术团队自建。
Portkey :AI Gateway + observability + guardrails,偏企业级多模型治理。
Helicone :LLM observability + gateway,适合监控成本和请求。
OpenRouter / 各模型平台控制台 :可做模型聚合或平台级 Key 管理,但团队内部授权、预算和审计深度有限。
1Password / Vault / Doppler :能管 secret,但不理解 LLM 费用、模型、token、prompt 风险。
自建反向代理 :成本低但维护、统计、权限和审计容易做不完整。
MVP 切口
建议切 “小团队 AI Key 分账与临时授权” ,避免与完整 LLM Gateway 正面竞争:
管理员录入上游 API Key,系统生成成员/项目级 virtual key。
每个 virtual key 可设置:模型白名单、每日/月预算、过期时间、速率限制、用途备注。
提供成本看板:按人、项目、模型、供应商统计 token 和费用。
支持一键禁用/轮换/导出审计记录。
优先支持 OpenAI-compatible API + DeepSeek/通义/豆包等国内常见接口。
验证方式
先做无代码/半自动原型:用 LiteLLM Proxy + 自建简易 UI,验证团队是否需要中文化管理和预算视图。
找 5 个团队访谈:过去 30 天是否出现 Key 共享、费用异常、离职未回收、模型供应商切换困难。
付费验证:若团队愿意为“每月节省/避免滥用/分账清晰”支付 99-499 元/月,才值得继续。
行为指标:管理员是否每周查看成本看板;是否主动创建项目级 Key;是否设置预算上限。
风险与反证
技术团队可能直接用 LiteLLM/Portkey,自建成本低,独立产品壁垒不足。
非技术团队不一定有 API 使用习惯,更可能购买 ChatGPT Team/Claude Team,而不是 API Key 平台。
只做密钥管理会被 1Password/Vault/Doppler 覆盖;必须聚焦 LLM 成本与授权。
若模型供应商原生团队管理能力快速补齐,独立平台空间会收窄。
下一步
补拉原始 thread,确认是否偏“API Key 管理”还是“大模型订阅授权分发”。
用 LiteLLM Proxy 快速搭一个内部可用 Demo,避免从零造网关。
输出竞品矩阵:LiteLLM / Portkey / Helicone / Cloudflare AI Gateway / 1Password / Vault。
做 5 个目标团队访谈,优先问真实事故和账单痛点。
参考来源链接
维护边界:本章节为 2026-06-02 增强分析受控块;后续若有新客户验证、竞品变化或 Lark 话题进展,可替换本章节,不覆盖原始档案正文。
项目质量升级(2026-06-03)
口径:本章节用于替换昨日偏模板化的增强稿表达;基于 Lark 话题真实数据、项目 mapping、既有维护报告与公开竞品格局,强调判断、边界、验证和反证。不覆盖原文其它章节。
project_id: team_api_key_management
当前判断
这个方向比前几个低证据项目更接近真实技术需求,因为行业里已经有 LiteLLM、Portkey、Helicone、Cloudflare AI Gateway 等成熟玩家,说明“多模型 API 使用、成本、权限、日志”确实是问题。但这也意味着它不适合泛泛做成“又一个 LLM Gateway”。
内部数据当前仍薄:mapping 有项目,维护报告显示 thread 原文 0/0;但 final 增强稿提到历史维护报告曾捕获相关市场研究摘要,结论是“真需求,但强竞品;更适合切团队内部大模型 Key 治理 + 订阅授权分发 + 成本控制”。
当前建议:P2 待轻量研究;用 LiteLLM Proxy + 简易 UI 做验证,不从零造网关。
真实内部数据
标题:团队 API Key 管理
project_id:team_api_key_management
Wiki / Doc:JHEownWgeihCtukWz8jluxuAgth / VubOdWQLYoiWZ0xY2khl5Efxgfd
Lark thread:[已脱敏]
阶段 / 优先级:待轻量研究;P2
更新策略:low
负责人:[已脱敏]
数据来源:mapping
消息 / 资源:0 条消息 / 0 个资源
补充线索:既有增强稿记录“历史维护报告中已有市场研究摘要”,但当前 snapshot 未拿到原文。
证据等级:L1+(看板记录 + 历史摘要线索;缺原始 thread 和真实用户访谈)
竞品 / 替代
LiteLLM Proxy :强竞品,已覆盖 virtual keys、预算、速率限制、模型路由、日志、团队管理。
Portkey :AI Gateway、observability、guardrails,偏企业和多模型治理。
Helicone :LLM observability + gateway,适合成本和请求监控。
Cloudflare AI Gateway :基础设施能力强,适合已有 Cloudflare 用户。
OpenRouter / 模型平台控制台 :聚合模型或平台级 Key 管理,但团队内部预算分发不一定细。
1Password / HashiCorp Vault / Doppler :管理 secret 强,但不理解 token、模型、prompt、费用和项目分账。
自建反向代理 :技术团队可低成本搭建,但可视化、审计、轮换和预算管理容易粗糙。
MVP 边界
推荐 MVP:小团队 AI Key 分账与临时授权 。
只做:
管理员录入上游 API Key,生成成员级/项目级 virtual key。
每个 virtual key 设置模型白名单、每日/月预算、过期时间、速率限制、用途备注。
成本看板按人、项目、模型、供应商统计 token 和费用。
支持一键禁用、轮换提醒、导出审计记录。
优先支持 OpenAI-compatible API,再补 DeepSeek、通义、豆包等常见接口。
明确不做:
验证计划
5 个团队访谈
重点不问“你要不要 Key 管理工具”,而问真实事故:
半自动 Demo
通过门槛 :5 个团队中至少 3 个有真实 Key/费用/权限事故;至少 2 个愿意试用;至少 1 个愿意为 99-499 元/月或私有部署服务继续报价。
风险反证
如果目标用户都是技术团队,且能直接用 LiteLLM/Portkey,自建产品壁垒不足。
如果非技术团队主要买 ChatGPT Team/Claude Team,不使用 API,则目标用户缩小。
如果用户只想“安全存 Key”,会被 1Password/Vault/Doppler 覆盖。
如果模型平台原生团队预算/子 key 管理快速补齐,独立空间会变窄。
如果用户不愿把上游 Key 放进第三方平台,必须转向私有部署/开源插件。
可能合并方向
与 ai_copilot_model_governance 合并为“团队 AI 使用治理”:Key、预算、模型、调用日志、安全审计一体化。
如果用户只需要成本看板,可并入 LLM observability 方向。
如果用户更关心密钥轮换和权限,可作为 DevOps secret 管理插件,而不是独立产品。
下一步
补拉原始 thread,确认最初需求到底是 API Key、订阅授权、成本审计,还是模型网关。
做竞品矩阵:LiteLLM / Portkey / Helicone / Cloudflare AI Gateway / 1Password / Vault。
用 LiteLLM Proxy 搭 1 天 Demo,不从零开发。
访谈 5 个团队,拿真实事故和预算意愿决定是否升级。
维护边界:本章节为 2026-06-03 质量升级受控块;后续新证据出现时可整体替换本章节。
维护说明
更新时间:2026年05月22日 16:55(北京时间)
项目状态卡
字段
内容
当前阶段
小步立项候选 / 验证中
优先级
P0/P1
当前评分
79 / 100
话题发起人
亚洲詹姆斯([已脱敏])
当前推进人
默认同话题发起人;若后续有明确接手人,再人工更新
最近更新时间
2026-06-01
当前判断
GEO/AEO 已具备明确内部需求、成熟工具线索和外部趋势,适合从“AI 可见性审计报告”切入做客户验证;第一阶段不建议直接做完整 SaaS。
下一步
用 7-14 天为 3 个品牌做样例审计,验证客户是否愿意为 AI 答案中的品牌存在感、引用来源、竞品对比和优化建议付费。
维护策略
高频更新:有相关 Lark 进展、外部工具/竞品、客户验证信号时更新。
最新进展
2026-06-01:完成项目档案维护结构试点。当前保留原正文和研究判断,只新增项目状态卡、最新进展、数据链接和维护说明;后续每日根据 Lark 话题进展、外部信号和 Score History 增量更新。
2026-06-01:工程化维护流程验证完成。update_project_archives.py 已支持单篇受控写入,默认仍为 dry-run;write 模式必须指定 project-id,只追加“最新进展”受控区块,不开放全量写入。
2026-06-02:完成 01 项目档案受控区块维护:同步当前 project_key / thread_id / Base record_id / Wiki 文档链接,并按最新话题数据校验项目状态、负责人、证据链接与下一步维护边界。
执行摘要
GEO/AEO 是搜索入口从“网页列表”迁移到“AI 直接答案”后产生的新型品牌可见性赛道。它解决的不是传统 SEO 排名问题,而是:当用户在 ChatGPT、Perplexity、Gemini、Google AI Overviews、Claude、Copilot、豆包、DeepSeek、Kimi、元宝、文心一言、夸克 AI、通义等 AI 搜索/问答入口询问“哪个产品更好”“某公司怎么样”“某领域推荐谁”时,品牌是否出现、是否被正确描述、是否被引用、是否被推荐。
按新版 elite-market-project-research 规则,本项目以 Lark 话题数据为 P0 核心证据:该话题由用户明确提出,已经有 6 条话题消息、4 条人类消息、2 条 AI 分析,以及 Profound、Scrunch、AthenaHQ、Peec、Promptwatch、Otterly、Goodie、Writesonic 等 8 个去重资源。外部 Brave Search 资料进一步验证:GEO / AI Visibility 已有专门平台、SEO 平台入场、行业文章和学术研究支持。
本项目建议进入 小步立项候选 ,但第一阶段不建议直接做完整 SaaS 平台。更优路径是从 AI 可见性审计报告 切入:用半自动方式为 3 个品牌做样例审计,验证客户是否愿意为“AI 答案中的品牌存在感、引用来源、竞品对比和优化建议”付费。
综合评分:79 / 100 。当前状态:小步立项候选,先做 7-14 天样例验证 。
一、Lark 话题证据摘要
字段
内容
话题群
Tranfu AI机会
chat_id
[已脱敏]
thread_id
[已脱敏]
项目标题
生成式引擎优化,GEO/AEO
当前阶段
discussing
消息规模
6 条消息 / 4 条人类消息 / 2 条 App 分析
资源规模
去重资源 8 个;项目表统计 resource_count=30,主要来自同一分析卡片中的 URL 重复展开
Base record_id
[已脱敏]
项目档案
[内部链接已脱敏]
原始需求
【事实】用户在 Lark 话题中明确提出:
生成式引擎优化,GEO/AEO。
通过技术 + 内容手段,让品牌/产品在生成式 AI 搜索/对话产品(豆包、DeepSeek、Kimi、元宝、文心一言、夸克 AI、百度 AI 搜索、通义、ChatGPT 等)回答用户问题时,被引用、被推荐、被排在显著位置的一整套优化服务。
包含:AI 可见性监测工具、AI 答案优化代运营服务、为 GEO 服务的内容生产、为 AI 模型抓取做的网站/数据结构改造。
【事实】用户随后追问:
现在 geo 有什么成熟的工具和平台?
这说明 Lark 内部需求不是泛泛“市场调研”,而是已经指向:
是否存在成熟工具和平台;
这个方向能否产品化或服务化;
应该如何理解 GEO/AEO 的市场阶段。
群内共识
【事实】话题内 AI 初步分析已经形成几个判断:
GEO 是真实的新兴市场,处于 0 到 1 早期;
本质是 SEO、品牌监测、内容营销、PR、AI 搜索可见性的交叉;
短期机会在监控和诊断,中期机会在内容优化工作流,长期机会在“AI 搜索时代的 Semrush / Ahrefs”;
已出现专门做 AI Search Visibility / GEO 的平台。
群内分歧
【事实】当前 Lark 话题没有明确反对意见或分歧。
【推断】缺少分歧不代表需求强验证完成,只说明话题还处在早期研究阶段。下一步应主动引入客户视角和反例:SEO/品牌团队是否愿意付费、是否信任 AI visibility 指标、是否认为传统 SEO 工具已经足够。
已提供资料
【事实】话题中已提供/提及的去重资源包括:
已形成判断
【推断】Lark 证据已经足以证明:团队内部对 GEO/AEO 有明确需求描述、工具调研意图和资源线索;但尚不足以证明:客户愿意付费、国内市场已经成熟、某个产品形态一定成立。
待验证问题
AI 工具/B2B SaaS/品牌团队是否真的在意“AI 答案里有没有我”;
客户愿意为一次性审计报告付多少钱;
客户是否需要月度监测,还是只需要一次诊断;
中文 AI 搜索/豆包/Kimi/DeepSeek/夸克等入口是否已经影响真实购买决策;
Semrush、Ahrefs、HubSpot、SE Ranking 等大平台入场后,独立小团队还能切哪一段。
Lark 证据等级
Lark 证据:L3-
原因:有明确用户发起、多轮追问、多个外部工具资源和 AI 分析,但还没有客户访谈、试用、付费、负责人和执行资源。
二、研究边界与方法论
2.1 市场定义
本报告中的 GEO/AEO 包含:
Generative Engine Optimization:生成式引擎优化;
Answer Engine Optimization:答案引擎优化;
AI Search Visibility:AI 搜索可见性;
LLM Visibility / LLM SEO:大模型答案可见性;
Brand Visibility in AI Answers:品牌在 AI 答案中的提及、引用、推荐、语义位置;
AI Overviews / Perplexity / ChatGPT / Gemini 等答案入口中的品牌监测和优化。
不包含:
2.2 决策场景
这是 AI Opportunity Radar 的项目机会评估,目标不是写一篇 SEO 科普文,而是判断:
这个方向是否值得现在投入验证?
应该切哪个细分场景?
MVP 应该怎么做?
哪些风险会让项目失败?
2.3 本次补充资料来源
本次使用 Brave Search 补充检索,重点覆盖:
Search Engine Land: What is Generative Engine Optimization;
Semrush: Generative Engine Optimization / AI Visibility Toolkit / AI Overviews study;
Profound: AI Search visibility platform;
Peec AI: AI search analytics for marketing teams;
Otterly.AI: AI search monitoring across ChatGPT、Perplexity、Google AI Overviews、Gemini、Copilot;
Scrunch AI: brand presence / AI customer experience / AI search visibility;
arXiv: GEO 相关论文与测量框架;
eMarketer / Search Engine Land / GoodFirms / SEO 工具文章关于 AEO/GEO 与 zero-click、AI Overviews 的资料。
二、第一性原理:为什么这个市场会出现
传统搜索链路是:
用户搜索关键词 → 搜索引擎返回网页列表 → 用户点击网站 → 品牌获得流量
AI 搜索链路正在变成:
用户直接提问 → AI 综合多个来源生成答案 → 用户在答案中完成认知/比较/决策
这改变了品牌增长的核心问题。
过去企业问:
我的网页在 Google 第几名?
现在企业还必须问:
AI 回答里有没有我?
AI 有没有正确描述我?
AI 推荐竞品时为什么没有我?
AI 引用了哪些来源?
我的官网/文档/内容能不能被 AI 理解和引用?
所以 GEO/AEO 的本质不是“SEO 新名词”,而是一个新的品牌分发与信任入口。
三、GEO / AEO / AI Visibility 的定义
3.1 GEO:Generative Engine Optimization
GEO 关注如何提升内容和品牌在生成式 AI 引擎中的可见性。
核心指标包括:
Brand mention rate:品牌出现率;
Citation share:引用占比;
Recommendation share:推荐占比;
Sentiment / framing:AI 如何描述品牌;
Competitor comparison:与竞品相比谁被推荐;
Source attribution:AI 引用了哪些页面或资料;
Query coverage:哪些用户问题能触发品牌出现。
3.2 AEO:Answer Engine Optimization
AEO 关注让内容更容易成为答案引擎的可引用材料。
典型优化动作:
FAQ / 问答化结构;
清晰的实体描述;
schema markup;
引用、数据、定义、对比表;
专家观点和权威来源;
内容更新和事实一致性;
页面结构更适合被 AI 摘要。
3.3 AI Visibility:更适合作为产品命名的概念
从产品角度,“GEO/AEO”是行业方法论,“AI Visibility”更适合做用户价值表达。
客户更容易理解:
你的品牌在 AI 答案里是否可见?
而不是:
你需要做生成式引擎优化。
四、市场拐点信号
拐点 1:AI Answer 入口正在真实改变搜索行为
Google AI Overviews、Perplexity、ChatGPT Search、Gemini、Copilot 等入口把搜索结果从“链接集合”变成“答案集合”。Semrush 等 SEO 平台已经开始追踪 AI Overviews、AI Visibility Toolkit 等指标,说明传统 SEO 工具也在将 AI 搜索纳入核心工作流。
判断:上升趋势,强度高。
拐点 2:Zero-click 进一步放大品牌可见性的价值
当用户不点击网页也能得到答案时,传统流量指标会变弱。企业即使自然排名不错,也可能在 AI 答案里不可见;反过来,被 AI Overview / Perplexity / ChatGPT 引用或推荐,可能成为新的品牌曝光和信任入口。
判断:上升趋势,强度高。
拐点 3:工具生态已经从概念进入产品竞争
Brave 检索显示,AI Visibility / GEO 工具已出现多个玩家:
Profound:企业级 AI 搜索可见性与需求洞察;
Peec AI:面向营销团队的 ChatGPT、Perplexity、Gemini 品牌表现分析;
Otterly.AI:跨 Google AI Overviews、ChatGPT、Perplexity、Gemini、Copilot 的自动监测;
Scrunch AI:品牌在 AI 搜索/AI customer journey 中的表现和内容缺口;
Semrush AI Visibility Toolkit:传统 SEO 平台进入 AI 可见性工具;
SE Ranking / Writesonic / Gauge / Evertune 等也在布局。
判断:市场教育加速,竞争升温,强度中高。
拐点 4:学术研究开始定义 GEO 方法和测量框架
arXiv 和 KDD 相关论文已经围绕 GEO、citation selection、citation absorption、GEO benchmark、AI search visibility 等进行研究。这说明该方向不是单纯营销包装,而是信息检索范式变化后的真实问题。
判断:早期标准化信号,强度中。
五、目标用户与购买动机
5.1 第一优先级用户
用户
购买动机
预算来源
B2B SaaS / AI 工具公司
用户问 AI“推荐哪个工具”时希望被提及
增长 / SEO / 内容营销
SEO / 内容营销团队
传统 SEO 指标不足,需要 AI visibility 指标
SEO 工具 / 内容预算
品牌 / PR 团队
关心 AI 如何描述品牌、是否误读、是否推荐竞品
品牌 / 公关预算
数字营销代理商
需要向客户提供新型服务包
客户项目预算
创业公司 / 独立产品
需要知道 AI 是否理解自己的定位
增长实验预算
5.2 第二优先级用户
投资机构研究团队;
垂直行业咨询公司;
电商/消费品牌;
教育、医疗、金融等高信任行业;
跨境品牌和出海 SaaS。
5.3 最强购买触发
用户不是为了“学习 GEO”付钱,而是为了回答这几个问题付钱:
当用户问 AI 推荐某类产品时,有没有我?
竞品为什么出现,我为什么没有出现?
AI 有没有错误描述我的产品?
我应该改哪些官网/文档/内容,才能提高被引用概率?
一个月后我的 AI 可见性有没有提升?
六、竞争格局
6.1 竞争梯队
第一梯队:企业级 AI Visibility 平台
代表:Profound、Evertune、Scrunch AI。
特点:
优势:企业客户、数据产品化、监测体系完整。
弱点:价格高、复杂度高、对小品牌/中文市场不一定友好。
第二梯队:中小团队 / 自助式监测工具
代表:Peec AI、Otterly.AI、Promptmonitor、SE Visible 等。
特点:
优势:上手快、价格低、教育成本低。
弱点:容易同质化;报告深度和优化建议可能不足。
第三梯队:传统 SEO 平台扩展
代表:Semrush、Ahrefs、SE Ranking。
特点:
优势:已有客户、已有预算、已有工作流。
弱点:AI 原生体验可能不如新创公司;中文/垂直场景可能滞后。
第四梯队:Agency / 服务商
特点:
优势:适合早期客户教育,能卖高客单服务。
弱点:交付重,规模化差。
6.2 竞争强度评分
维度
强度
判断
新进入者
高
LLM + 搜索 API 让初版监测工具门槛不高
替代品
中高
SEO 平台、内容平台、代理商都可扩展
买方议价
中
客户愿意试,但预算归属仍在形成
供应商议价
中
模型和搜索接口成本可控,但采样稳定性重要
行业内竞争
中高
2025-2026 年产品会快速变多
结论:这是一个“有机会但必须快切细分”的市场。不能做泛泛的 GEO 平台,必须选择差异化入口。
七、用户痛点与机会矩阵
7.1 Top 5 真痛点
不知道自己是否被 AI 提及 :AI answer 入口不可见;
不知道竞品为什么被推荐 :缺竞品对比;
不知道 AI 是否错误描述自己 :品牌事实不一致;
不知道该优化什么内容 :缺行动建议;
无法证明 GEO/AEO 投入有效 :缺前后对比指标。
7.2 非对称机会矩阵
机会
痛点强度
AI 解决难度
判断
AI 可见性审计报告
高
中
黄金切入点
竞品 AI 推荐份额监测
高
中
高价值,可做成订阅
官网/文档 AEO 改造建议
中高
中
适合服务化交付
全自动 GEO SaaS 平台
高
高
长期方向,不适合第一步
面向所有行业的泛 GEO 内容生成
中
低
同质化风险高
八、产品机会
机会 1:AI 可见性审计报告
产品定义
为一个品牌生成 AI 搜索可见性审计:
品牌名 + 官网 + 竞品 + 目标 query
→ 多 AI 引擎采样
→ 品牌/竞品出现率
→ 引用来源
→ AI 描述准确性
→ 内容缺口
→ 30 天优化建议
为什么优先做
不需要一开始做复杂 SaaS;
可手动/半自动交付;
客户容易理解;
能验证付费意愿;
结果适合展示样例。
适合客户
AI 工具;
B2B SaaS;
出海工具;
SEO agency;
正在做内容营销的创业公司。
机会 2:AI Visibility Tracker
产品定义
按周/按月监测固定 query 下的品牌表现。
核心指标:
mention rate;
[已脱敏] share;
citation share;
sentiment;
competitor rank;
source changes;
query coverage。
适合阶段
在审计报告验证有客户愿意持续关注后,再做订阅看板。
机会 3:AEO 内容改造服务
产品定义
把客户现有官网、文档、博客改造成 AI 更容易引用的内容结构。
输出:
风险
效果归因难,需要与监测指标绑定。
九、商业模式
9.1 一次性审计报告
适合早期验证。
可能价格:
轻量版:¥999 - ¥2999
专业版:¥5000 - ¥20000
企业版:定制报价
交付物:
AI 可见性评分;
竞品对比;
query 列表;
引用来源;
错误描述;
内容缺口;
30 天行动计划。
9.2 月度监测订阅
适合中期产品化。
按以下维度收费:
品牌数;
query 数;
竞品数;
AI 引擎数;
采样频率;
报告深度。
9.3 Agency enablement
卖给代理商:
让 SEO/内容/品牌代理商用我们的模板和工具,为客户交付 GEO/AEO 报告。
优点:分发更快。
缺点:需要模板化和白标能力。
十、反共识观点
共识 1:GEO/AEO 是 SEO 的新版本
反共识判断:GEO/AEO 不是 SEO 的子集,而是品牌信任入口变化。
SEO 关注排名和点击,GEO/AEO 关注 AI 答案中的存在感、引用、语义位置和推荐权重。即使网站排名第一,也可能在 AI 答案中不可见。
置信度:高。
共识 2:做 GEO 最重要的是多写内容
反共识判断:内容数量不是关键,AI 可引用性和实体可信度才是关键。
AI 更需要清晰的事实、结构化描述、比较信息、权威引用、数据和一致性。低质量内容堆量可能无效,甚至让 AI 对品牌产生错误理解。
置信度:中高。
共识 3:最佳产品形态是 SaaS 看板
反共识判断:早期最佳形态可能是“审计报告 + 咨询服务”,不是 SaaS。
因为客户还在形成问题意识。先用报告教育市场、验证付费、沉淀指标,再抽象成产品,比直接做 SaaS 更稳。
置信度:高。
十一、Project Scoring
项目类型:commercial_product + research_probe + internal_initiative。
证据等级:L1+。已有公开竞品、SEO 平台入场、学术研究、用户问题,但尚缺真实客户访谈和付费验证。
11.1 证据融合表
结论
Lark 证据
外部证据
类型
置信度
备注
GEO/AEO 是真实新兴方向
用户明确提出完整定义,并追问成熟工具
Search Engine Land、Semrush、eMarketer、GEO 论文均在讨论
事实+推断
高
不是凭空概念
已有可对标工具
Lark 资源包含 Profound、Scrunch、Peec、Otterly 等
Brave Search 进一步发现 Evertune、SE Ranking、HubSpot AEO Grader 等
事实
高
工具生态早期但已商业化
最佳切口不是直接做 SaaS
Lark 需求是“调研工具/平台”,还不是购买软件
外部工具多,竞争升温,客户教育仍早
推断
高
先做审计报告更稳
中文市场机会存在但未验证
原始需求点名豆包、DeepSeek、Kimi、元宝、夸克等
外部资料多偏英文/海外平台
推断
中
需要中文品牌样例测试
可以进入小步立项候选
Lark 有多轮需求+资源+分析
外部市场、竞品、SEO 平台入场支持
观点
中高
仍需付费验证
11.2 证据等级
Lark 证据等级:L3-
外部证据等级:L2
综合证据等级:L2+/L3-
说明:
Lark 层面强于普通观察:有明确需求定义、多轮追问、工具资源和初步分析;
外部层面强于概念:已有多个产品化平台和传统 SEO 平台入场;
但尚缺客户访谈、试用行为和付费信号,所以不能判为 L4。
11.3 评分表
维度
权重
分数
依据
Demand reality
16
80
Lark 原始需求明确且有多轮追问;外部品牌/SEO/内容团队痛点明确,但仍需访谈验证预算
AI workflow fit
12
84
多模型答案采样、引用分析、内容缺口总结高度适合 AI 工作流
Technical feasibility
10
78
可先半自动采样和报告生成,复杂点在稳定监测与反爬/成本
Validation feasibility
10
82
7-14 天可做 3 个品牌样例报告验证
Distribution reachability
10
72
Lark 已点名 AI 产品/品牌场景;AI 工具/B2B SaaS/SEO agency 可作为第一批对象
Business/value recovery
10
74
审计报告和月度监测均有付费路径,但价格需验证
Reuse and retention
8
78
月度监测、竞品对比、内容改造有复购逻辑
Cost structure
8
70
模型/API 成本可控,但多引擎采样需要成本管理
Risk and responsibility
8
72
风险中等,主要是数据准确性、夸大承诺、平台波动
Tranfu fit
8
88
与 AI Opportunity Radar、研究报告、AI 工具生态高度匹配
11.4 最终评分
项目质量分:79 / 100
Lark 证据等级:L3-
外部证据等级:L2
综合证据等级:L2+/L3-
状态:小步立项候选,先做 7-14 天样例验证
11.5 硬门槛检查
Gate
结果
User gate
通过:B2B SaaS / AI 工具 / SEO 团队 / agency
Demand gate
部分通过:痛点明确,但付费意愿需验证
AI-fit gate
通过:AI 适合采样、归纳、对比、建议生成
Responsibility gate
通过:不涉及高危专业决策,但需避免夸大“保证排名”
十二、7-14 天验证计划
Day 1:选样例品牌
选择 3 个品牌:
一个 AI 工具;
一个 B2B SaaS;
一个中文/出海产品。
每个品牌准备:
官网;
3-5 个竞品;
20 个目标 query;
目标市场/语言。
Day 2-3:多引擎采样
覆盖:
ChatGPT;
Perplexity;
Gemini;
Google AI Overviews;
Claude / Copilot 可选。
采集:
品牌是否出现;
出现位置;
是否推荐;
是否引用;
引用来源;
描述是否准确;
竞品出现情况。
Day 4-5:生成报告
输出:
Day 6-7:客户反馈
找 5-10 个潜在客户/朋友公司看样例报告。
验证问题:
是否理解这个报告价值;
是否愿意每月看;
是否愿意为一次性报告付费;
最想看哪 3 个指标;
是否愿意提供官网/竞品/query 做测试。
Day 8-14:迭代成模板
如果反馈积极:
固化报告模板;
制作 landing page;
形成第一个可销售服务包。
十三、MVP 设计
13.1 输入
品牌名
官网 URL
产品一句话
竞品列表
目标用户
目标 query 列表
目标 AI 引擎
目标市场/语言
13.2 输出
AI Visibility Score
品牌出现率
竞品推荐份额
引用来源
错误描述
内容缺口
AEO 改造建议
30 天行动计划
13.3 最小系统模块
Query 管理;
多 AI 引擎采样;
答案解析;
品牌/竞品识别;
引用来源提取;
报告生成;
历史对比。
第一版可以半自动,不需要全自动平台。
十四、事前验尸
假设 2 年后项目失败,最可能原因:
直接做 SaaS,看板没人持续用;
客户只觉得“有趣”,但不愿付费;
Semrush / Ahrefs / SEO 平台快速覆盖主流需求;
采样波动大,客户不信数据;
无法证明优化动作带来可见性提升;
只做监测,没有行动建议;
中文/国内场景 AI 搜索习惯不足,需求释放慢。
我会改变看法的触发条件:
十五、最终建议
GEO/AEO 是当前三个项目中最适合先做样例验证的方向之一。它的优势是 Lark 话题证据相对最完整:有明确需求定义、多轮追问、资源列表和 AI 初步分析;短板是还没有客户访谈和付费验证。
推荐路线:
AI 可见性审计报告
→ 3 个品牌样例测试
→ 5-10 个客户访谈
→ 标准化报告模板
→ 月度监测服务
→ 轻量 SaaS 看板
不建议路线:
一开始做大而全 GEO 平台
一开始承诺提高排名
一开始只做内容生成
一开始不做竞品对比和引用来源
唯一主线下一步:
选 3 个品牌,做 AI Visibility Audit 样例报告,并把结果回填到 Lark 话题:每个品牌至少记录 20 个 query、3-5 个竞品、5 个 AI 入口、客户反馈和是否愿意付费。
参考来源
Search Engine Land: Generative engine optimization: How to win AI mentions
Semrush: Generative Engine Optimization practical guide
Semrush: AI Visibility Toolkit / AI Overviews study
Profound: Optimize Your Brand's Visibility in AI Search
Peec AI: AI Search Analytics for Marketing Teams
Otterly.AI: AI Search Monitoring and LLM Monitoring
Scrunch AI: Boost Brand Presence in AI Search
arXiv: Generative Engine Optimization and GEO measurement research
eMarketer: GEO and AEO in AI search
SE Ranking / Gauge / Evertune / Writesonic industry comparisons
数据链接
类型
内容
Base record_id
[已脱敏]
Lark 话题群
Tranfu AI机会([已脱敏])
Lark thread_id
[已脱敏]
Wiki 节点
ULPiwYwHSimAQTkryHGlTCpDg6d
文档 token
OnlxdylUNoG8Q1xZVFHl1R0Mgcb
相关 Signals / Evidence Links
后续由 03 数据看板同步补齐
项目增强分析(2026-06-02)
口径:基于最新项目维护报告、Lark 话题真实数据与可复核公开资料整理;web_search 当前不可用,因此未二次核验的市场判断均按“趋势/假设”保守处理。
project_id: geo_aeo
📌 一句话机会
让品牌/产品在 ChatGPT、Perplexity、Gemini、Google AI Overviews、豆包、DeepSeek、Kimi 等 AI 答案引擎中——被提及、被引用、被推荐——的可见性监测与内容优化服务 ,优先从"AI 可见性审计报告"切入客户验证市场。
🎯 目标用户
| 优先级 | 用户 | 购买动机 | 预算来源 |
|--------|------|----------|----------|
| P1 | B2B SaaS / AI 工具公司 | 用户问 AI "推荐哪个工具"时希望被提及 | 增长/SEO/内容营销 |
| P1 | SEO / 内容营销团队 | 传统 SEO 指标不足,需要 AI visibility 指标 | SEO 工具/内容预算 |
| P1 | 品牌 / PR 团队 | 关心 AI 如何描述品牌、是否误读、是否推荐竞品 | 品牌/公关预算 |
| P2 | 数字营销代理商 | 需要向客户提供新型服务包 | 客户项目预算 |
| P2 | 创业公司 / 独立产品 | 需要知道 AI 是否理解自己的定位 | 增长实验预算 |
| P2 | 出海中国品牌 | AI 搜索(Perplexity/ChatGPT/Gemini)在海外影响买决策 | 出海营销预算 |
🔥 核心痛点
不知道自己是否被 AI 提及 :AI answer 入口不可见,传统 SEO 监控无法覆盖
不知道竞品为什么被推荐 :缺 AI 答案中的竞品对比数据
不知道 AI 是否错误描述自己 :品牌事实不一致,影响信任
不知道该优化什么内容 :官网/文档/博客的结构、引用、schema 是否被 AI 理解
无法证明 GEO/AEO 投入有效 :缺前后对比指标和行业基准
📊 当前证据
内部话题数据
"通过技术 + 内容手段,让品牌/产品在生成式 AI 搜索/对话产品回答用户问题时,被引用、被推荐、被排在显著位置的一整套优化服务。包含:AI 可见性监测工具、AI 答案优化代运营服务、为 GEO 服务的内容生产、为 AI 模型抓取做的网站/数据结构改造。"
后续追问 :"现在 geo 有什么成熟的工具和平台?"
话题证据等级 :L3-(有明确需求定义、多轮追问、工具资源、AI 分析,但缺客户访谈和付费验证)
项目评分 :79/100
当前状态 :验证中 / 小步立项候选
去重资源 :Profound、Scrunch、AthenaHQ、Peec AI、Promptwatch、Otterly、Goodie GEO、Writesonic GEO
外部资料/行业趋势
GEO / AI Visibility 已不是概念,Search Engine Land、Semrush、eMarketer 等主流 SEO/营销媒体持续覆盖
传统 SEO 平台正入场:Semrush AI Visibility Toolkit、SE Ranking AI Overviews
多个独立平台已产品化:Profound(企业级)、Peec AI(营销团队版)、Otterly.AI(多引擎自动监测)
arXiv 已出现 GEO 论文、测量框架和 benchmark(citation selection、citation absorption)
AI Overviews、Perplexity、ChatGPT Search 正在改变搜索行为,zero-click 模式放大品牌可见性价值
中文市场 :豆包/DeepSeek/Kimi/元宝/夸克/百度AI搜索等入口增长快,但外部资料多偏英文
竞争格局
| 梯队 | 代表 | 特点 |
|------|------|------|
| 第一梯队:企业级 AI Visibility 平台 | Profound、Evertune、Scrunch AI | 多模型、多 prompt、企业客户 |
| 第二梯队:自助式监测工具 | Peec AI、Otterly.AI、SE Visible | 低价、易上手,适合小团队 |
| 第三梯队:传统 SEO 平台扩展 | Semrush、SE Ranking、Ahrefs | 已有客户和预算,AI 原生体验可能不足 |
| 第四梯队:Agency/服务商 | 各类 SEO 代理 | 交付重,规模化差,但能卖高客单服务 |
🏗️ MVP 切口
推荐路径:AI 可见性审计报告
不要 直接做完整 SaaS;先 为人品牌做 7-14 天样例验证。
输入 :
输出 :
第一版可半自动交付 ,不需要全自动平台。
✅ 验证方式
选 3 个品牌 (一个 AI 工具、一个 B2B SaaS、一个中文/出海产品)
7 天完成多引擎采样 + 报告生成
找 5-10 个潜在客户看样例报告 ,验证:
是否理解报告价值
是否愿意每月看更新
是否愿意为一次性报告付费
最想看哪 3 个指标
关键指标 :客户理解率 ≥ 70%,愿意付费比例 ≥ 30%
⚠️ 风险与反证
| 风险 | 可能性 | 影响 | 缓解 |
|------|--------|------|------|
| 客户觉得"有趣但不付费" | 中高 | 致命 | 先做样例后再收费 |
| Semrush/Ahrefs 快速覆盖 | 中 | 严重 | 聚焦中文/出海差异化 |
| 采样波动大,数据不可信 | 中 | 严重 | 固定 prompt 模板 + 多轮采样 |
| 只做监测没有行动建议 | 中低 | 中 | 审计报告天然包含优化建议 |
| 中文 AI 搜索需求释放慢 | 中 | 中 | 优先英文市场验证,再回归中文 |
我会改变看法的触发条件 :
10 个潜在客户看完样例报告后无人愿意继续试用
客户只关心传统 SEO,不关心 AI 答案
采样结果高度不稳定,无法形成可信指标
📋 下一步
第 1 步(7 天):选 3 个品牌 → 多引擎采样 → 出样例审计报告
第 2 步(7 天):找 5-10 个潜在客户验证付费意愿
第 3 步:根据反馈固化报告模板 → 制作 landing page → 形成可销售服务包
第 4 步(中期):月度监测订阅 → 轻量 SaaS 看板
不建议 的路线:一开始做大而全 GEO 平台 / 承诺提高排名 / 只做内容生成不做竞品对比
🔗 参考来源链接
Search Engine Land: "Generative engine optimization: How to win AI mentions"
Semrush: "Generative Engine Optimization practical guide" / "AI Visibility Toolkit"
Profound: https://www.tryprofound.com/
Peec AI: https://www.peec.ai/
Otterly.AI: https://otterly.ai/
Scrunch AI: https://scrunch.com/
arXiv: GEO measurement research / citation selection papers
eMarketer: GEO/AEO in AI search trends
SE Ranking / Gauge / Evertune / Writesonic 行业对比
维护边界:本章节为 2026-06-02 增强分析受控块;后续若有新客户验证、竞品变化或 Lark 话题进展,可替换本章节,不覆盖原始档案正文。
项目质量升级(2026-06-03)
口径:本章节用于替换昨日偏模板化的增强稿表达;基于 Lark 话题真实数据、项目 mapping、既有维护报告与公开竞品格局,强调判断、边界、验证和反证。不覆盖原文其它章节。
project_id: geo_aeo
当前判断
这是 Batch A 里最接近“可以小步立项验证”的方向。理由不是“GEO 概念新”,而是内部话题已经同时出现了:明确需求定义、二次追问、工具/平台资源、以及可半自动交付的服务切口。当前更适合定义为 AI 搜索可见性审计服务 ,不是先做 SaaS 平台。
我对它的判断是:P0/P1 验证中,可用 14 天验证是否从“有趣报告”升级为“愿意付费的增长/品牌预算”。 如果验证失败,多半不是技术问题,而是客户还没把 AI 答案可见性纳入预算。
真实内部话题数据
项目名:生成式引擎优化,GEO/AEO
project_id:geo_aeo
Wiki / Doc:ULPiwYwHSimAQTkryHGlTCpDg6d / OnlxdylUNoG8Q1xZVFHl1R0Mgcb
Lark thread:[已脱敏]
阶段 / 优先级:验证中 / 小步立项候选;P0/P1
更新策略:high
负责人:亚洲詹姆斯
数据来源:snapshot
消息 / 资源:6 条消息 / 30 个资源
维护门禁:PASS
最近话题脉络:先由小满解释 GEO = Generative Engine Optimization,即让品牌、产品、网站在 ChatGPT、Perplexity、Gemini、Google AI Overview 等 AI 答案里更容易被提到、引用、推荐;随后用户追问“现在 geo 有什么成熟的工具和平台”,并沉淀出 Profound、Peec AI、Otterly、Scrunch 等工具链。
既有评分:79/100
证据等级:L3-(有需求定义、多轮追问、工具资源和 AI 分析;仍缺客户访谈、真实审计样例和付费验证)
外部竞品 / 替代方案
企业级 AI Visibility 平台 :Profound、Scrunch、Evertune、AthenaHQ。优势是多模型、多 prompt、企业销售;劣势是对中文/出海中国品牌的本地化语境未必充分。
自助式监测工具 :Peec AI、Otterly.AI、Promptwatch、Goodie GEO、Writesonic GEO。优势是上手快、价格低;劣势是很容易停留在 dashboard,缺少“我下一步改什么”的服务闭环。
传统 SEO 平台扩展 :Semrush AI Visibility Toolkit、SE Ranking AI Overviews、Ahrefs 潜在扩展。优势是已有 SEO 客户和预算;劣势是 AI 答案监测会被当成 SEO 附属模块,不一定能覆盖中文 AI 入口。
Agency / 咨询替代 :SEO 代理商、内容营销顾问、公关公司。它们会把 GEO 包进服务里,但交付质量和数据采样方法不稳定。
客户自助替代 :市场团队手工用 ChatGPT / Perplexity / Gemini 搜索品牌和竞品,再整理表格。低成本,但不可重复、不可监测、不可形成前后对比。
MVP 做什么
MVP:AI 可见性审计报告。
输入保持极窄:品牌名、官网、产品一句话、3-5 个竞品、20 个目标 query、目标语言/市场、3-5 个 AI 引擎。
输出只交付一份可读报告:出现率、推荐份额、竞品对比、引用来源、品牌误读、内容缺口、30 天优化建议。
第一版可以半自动,不需要实时看板。核心不是“抓更多模型”,而是让客户看到:AI 正在如何描述我、推荐谁、为什么推荐竞品、我应该改哪些公开内容。
MVP 不做什么
不做完整 SaaS dashboard。
不承诺“提高 AI 排名”或“保证被 ChatGPT 推荐”。
不先做内容代运营团队。
不做全行业泛化模板,先选 B2B SaaS / AI 工具 / 出海品牌。
不把中文和英文市场混在同一套指标里,避免样本口径混乱。
不做需要大量浏览器自动化和账号池的重型采样系统;先用固定 prompt、固定模型、固定轮次。
7 天验证计划
Day 1:选 3 个样例品牌:1 个 AI 工具、1 个 B2B SaaS、1 个中文/出海产品;每个品牌列 3-5 个竞品。
Day 2:设计 20 个 query 模板,覆盖“推荐工具”“替代方案”“对比”“某场景最佳选择”“品牌是什么”。
Day 3-4:在 ChatGPT、Perplexity、Gemini / Google AI Overviews、以及 1-2 个中文入口中采样;每个 query 至少跑 3 轮,记录品牌出现、竞品出现、引用来源。
Day 5:产出 3 份审计样例,每份控制在 8-12 页或等效文档长度。
Day 6:找 5 位营销/增长/SEO/创始人角色看报告,访谈他们最关心的指标。
Day 7:复盘是否有继续试用意愿、付费意愿、愿意提供真实品牌数据的客户。
7 天通过门槛 :5 位访谈对象中至少 3 位能在 5 分钟内理解报告价值;至少 2 位愿意提供自己品牌做真实审计;至少 1 位愿意为一次性审计或月度监测报价继续聊。
14 天验证计划
Week 2 前 3 天:把样例报告改成可复用模板,固定指标口径:出现率、推荐份额、引用域名、品牌描述准确性、竞品理由、行动建议。
Week 2 第 4-5 天:对 2 个真实客户/朋友品牌做 concierge 审计,要求对方提供官网、竞品、目标市场。
Week 2 第 6 天:给出 30 天优化建议,并区分“立刻改官网/文档/FAQ”“新增内容”“外部引用建设”。
Week 2 第 7 天:确认是否愿意付费购买第二次复测或月度订阅。
14 天通过门槛 :至少 1 个真实品牌愿意付费或明确进入报价流程;客户能指出 3 条以上报告中“以前不知道、但有行动价值”的发现。
风险反证
如果 10 个潜在客户看完样例后都说“有意思,但不值得付费”,应降级为内容营销服务插件,而不是独立项目。
如果同一 query 多轮采样波动过大,导致品牌出现率不可解释,应暂缓 dashboard 化,只保留定性审计。
如果客户只关心 Google SEO 排名,不关心 AI 答案推荐,应把目标用户从 SEO 团队转向品牌/PR/创始人。
如果 Semrush/Ahrefs 等快速推出足够好、足够便宜的同类功能,应转向中文 AI 入口、出海品牌、以及“审计 + 行动建议”服务差异化。
如果样例报告需要大量人工判断且无法模板化,说明短期更像咨询业务,不适合做高频 SaaS。
下一步
立即做 3 个品牌的样例审计,不再继续扩大竞品列表。
固定 query 与采样模板,避免每次报告口径变化。
把报告命名为“AI Search Visibility Audit”,面向增长/品牌预算测试报价。
14 天后根据付费/试用结果决定:升级为月度监测服务,还是降级为机会池。
维护边界:本章节为 2026-06-03 质量升级受控块;后续新证据出现时可整体替换本章节。
维护说明
本文档主体内容保留原有人工/研究判断,不做自动覆盖。
每日自动维护只更新:项目状态卡、最新进展、数据链接。
评分与判断仅在 Base / Score History 发生变化时更新。
项目定义、MVP、风险判断如需大幅调整,需要人工确认。
更新时间:2026年05月22日 16:45(北京时间)
项目状态卡
字段
内容
当前阶段
观察 / 重构方向
优先级
P2
当前评分
58 / 100
话题发起人
空空([已脱敏])
当前推进人
默认同话题发起人;当前暂无明确推进人
最近更新时间
2026-06-01
当前判断
AI生活助手方向过宽,现阶段不能当作已验证项目推进。它更适合作为需求收集池,先从家庭事务、老人提醒陪伴、健康饮食执行等垂直生活场景里筛选一个高频刚需切口。
下一步
先收集 3-5 个真实生活场景样本,记录用户、频率、现有替代方案、AI 可节省的时间/焦虑和付费可能性;样本不足前不进入产品验证。
维护策略
低频更新:只在出现明确生活场景、真实用户样本、使用频次、付费线索或可验证 MVP 切口时更新。
最新进展
2026-06-01:完成观察型项目档案结构化试点。当前保留原正文“证据弱、方向宽、需重构”的判断,只新增项目状态卡、最新进展、数据链接和维护说明;该项目后续不做高频维护,只在出现真实场景样本时更新。
2026-05-22:Lark 话题创建,原始需求为“AI生活助手,AI帮你解决日常生活的问题”。目前只有 1 条人类消息、0 个外部资源,证据等级较低。
2026-06-02:完成 01 项目档案受控区块维护:同步当前 project_key / thread_id / Base record_id / Wiki 文档链接,并按最新话题数据校验项目状态、负责人、证据链接与下一步维护边界。
执行摘要
AI生活助手不是一个可以直接立项的“泛助手”项目,而是一个需要从 Lark 话题中继续收集真实生活场景、再筛选垂直切口的早期机会。
当前 Lark 核心证据很弱:只有 1 条用户根消息,主题是“AI生活助手 AI帮你解决日常生活的问题”,缺少具体场景、用户画像、频率、现有替代方案、付费意愿和后续讨论。因此本报告不能把它判断为已验证需求,只能判断为 值得观察和结构化收集需求的方向 。
外部市场证据显示,AI personal assistant / intelligent virtual assistant / AI companion / family AI assistant / elderly care AI / AI health coach 等方向都在增长,且大厂和创业公司都在布局。但这也意味着泛化竞争极强。第三项目最优策略不是做“万能生活助手”,而是通过 7-14 天验证,从 3 个垂直场景中选一个:
家庭事务协调助手
老人提醒与陪伴助手
健康饮食执行助手
综合评分:58 / 100 。当前状态:重构方向 / 继续收集需求 。
一、Lark 话题证据摘要
字段
内容
话题群
Tranfu AI机会
chat_id
[已脱敏]
thread_id
[已脱敏]
项目标题
AI生活助手AI帮你解决日常生活的问题
当前阶段
new
已有信号
1 条消息 / 用户 1 条 / AI 分析 0 条 / 资源 0 个
Base record_id
[已脱敏]
项目档案
[内部链接已脱敏]
原始需求
【事实】Lark 话题中目前只有一个非常宽泛的项目根消息:
AI生活助手,AI帮你解决日常生活的问题。
群内共识
【事实】目前没有多轮群内讨论,也没有形成具体共识。
群内分歧
【事实】目前没有可记录分歧。
已提供资料
【事实】资源数为 0,暂无链接、附件、竞品、截图或用户案例。
已形成判断
【推断】从内部前台总览和已有项目卡片看,团队已初步判断:
AI生活助手方向太宽,需要先收集 3-5 个高频生活场景,再筛选切入点。
待验证问题
具体用户是谁:家庭主理人、老人子女、高压职场人、育儿家庭,还是普通消费者?
高频场景是什么:家庭任务、饮食健康、老人照护、消费决策、日程管理?
用户现在怎么解决:微信、备忘录、日历、外卖/买菜 App、智能音箱、家庭群?
AI 能不能明显节省时间或降低焦虑?
用户是否愿意付费,还是只把它当免费大模型功能?
Lark 证据等级
Lark 证据:L1/L2 边界
原因:有真实话题根消息,但缺少多轮讨论、样本、行为信号或付费/负责人证据。
二、研究边界与方法论
本报告按 elite-market-project-research 执行:
Lark Topic Evidence Core :以 Lark 话题为核心证据,明确当前内部证据不足;
Elite Market Researcher :做第一性原理、拐点、反共识、事前验尸;
Market Analysis :补充外部市场、竞品、用户痛点和政策风险;
Project Scoring :按 10 维度评分,并结合 Lark 证据等级降级。
数据来源
Lark / 内部来源
外部来源
本次使用 Brave Search 补充检索,覆盖:
AI personal assistant market;
intelligent virtual assistant market;
consumer AI assistant products;
AI companion apps;
family AI assistant / household management;
AI health coach / personalized nutrition;
AI elderly care assistant;
AI agent startup funding。
三、第一性原理
“AI生活助手”这个词本身没有商业含义。它必须还原成一个更具体的问题:
谁,在什么生活场景里,反复遇到什么麻烦;
这个麻烦现在怎么解决;
AI 能不能以更低成本、更低心智负担、更高可靠性解决;
用户是否愿意为这个结果付费或持续使用。
日常生活问题有三个特点:
高频但碎片化 :买菜、做饭、日程、家庭沟通、健康、育儿、老人照护都很高频,但彼此差异大;
强上下文依赖 :生活助手必须知道家庭成员、习惯、预算、健康状况、日程和偏好;
信任门槛高 :健康、老人、孩子、财务、隐私都不是简单聊天能解决的。
所以泛化 AI 生活助手的问题是:
场景太多 → 数据太杂 → 价值不清 → 用户不付费 → 被 ChatGPT/Siri/Gemini/Alexa 替代。
更好的路径是:
先找一个高频、强痛、低风险、可验证的生活场景。
四、市场/赛道定义
AI生活助手可以拆成 6 个子赛道:
子赛道
代表方向
机会判断
通用个人助手
ChatGPT、Gemini、Copilot、Siri、Alexa
大厂入口,创业难度高
家庭事务助手
日程、任务、饭菜、购物、家务协同
有垂直机会,适合验证
老人照护助手
陪伴、提醒、健康打卡、异常通知
痛点强,但责任风险高
健康饮食助手
饮食计划、运动、营养、体重管理
需求大,但合规和信任要求高
AI Companion
陪伴、情绪、聊天、角色互动
C 端已有收入,但风险和同质化高
消费决策助手
买什么、怎么选、比价、避坑
容易做 demo,但留存和商业模式需验证
五、市场拐点信号
拐点 1:通用 AI 助手正在进入日常生活入口
【事实】外部资料显示,AI Assistant / Intelligent Virtual Assistant 市场在 2025-2032/2035 年有高增长预期,不同报告给出 20%+ 到 40%+ 的 CAGR。ChatGPT、Gemini、Copilot、Siri、Alexa 等正在成为个人任务、问答、日程、搜索、内容生成入口。
【推断】这说明用户接受 AI 助手的教育成本在下降,但也意味着泛助手入口已经被大厂占据。
趋势:上升。强度:高。
拐点 2:硬件型“万能 AI 助手”试错失败,软件/垂直场景更现实
【事实】外部资料和产品复盘中,Rabbit R1、Humane AI Pin 等硬件型 AI 助手受挫,而 Limitless、家庭管理、AI companion、AI health coach 等更垂直的场景仍在探索。
【推断】用户不是不需要 AI 助手,而是不需要一个没有明确场景的“AI 盒子”。
趋势:从泛硬件转向软件和垂直场景。强度:中高。
拐点 3:AI Companion 已证明 C 端愿意为“陪伴”付费,但与生活执行不是同一类需求
【事实】TechCrunch 等资料显示,AI companion apps 在 2025 年移动端收入可达约 1.2 亿美元量级,Replika、Character.AI、Chai 等产品有明确用户群。
【推断】C 端确实会为 AI 互动付费,但陪伴/情绪价值与“帮我解决生活问题”的执行价值不同,不能直接等同。
趋势:上升。强度:中。
拐点 4:家庭 AI 助手开始出现垂直创业产品
【事实】Brave 检索中出现 Nori、familymind、Honeydew 等家庭 AI assistant,聚焦 shared calendar、tasks、meal planning、chores、shopping lists 等家庭协同任务。
【推断】家庭事务协调可能比泛个人助手更适合创业切入,因为它有明确的多人协作、重复任务和碎片信息整合需求。
趋势:早期上升。强度:中。
六、目标用户与购买动机
6.1 可能用户分层
用户
高频痛点
是否适合第一阶段
家庭主理人 / 父母
日程、购物、吃饭、孩子活动、家务分配
高
成年子女 / 老人照护者
提醒吃药、健康打卡、陪伴、异常通知
中高,但风险高
高压职场人
日程、任务、饮食、运动、自我管理
中
育儿家庭
教育安排、活动、作业、沟通、资料整理
中高
普通消费者
买东西、选服务、比价、避坑
中
银发用户本人
陪伴、提醒、语音交互
中,但交互和硬件门槛高
6.2 购买动机
用户不会为“AI生活助手”付费,但可能为这些结果付费:
家里少吵架、少漏事;
老人按时吃药、子女放心;
每周买菜做饭更省心;
育儿信息和活动安排不混乱;
健康饮食有持续执行;
复杂消费决策少踩坑。
七、竞争格局
7.1 第一梯队:系统级和大模型助手
代表:ChatGPT、Gemini、Claude、Copilot、Siri、Google Assistant、Alexa。
优势:
用户入口强;
模型能力强;
与系统、搜索、日历、邮件、智能家居整合;
泛问答成本低。
弱点:
不一定懂家庭长期上下文;
不一定能稳定执行生活流程;
多人家庭协作能力仍弱;
垂直场景体验不够深。
7.2 第二梯队:AI Companion
代表:Replika、Character.AI、Chai、PolyBuzz 等。
优势:
陪伴和情绪价值明确;
C 端付费已有验证;
使用频率高。
弱点:
与生活事务执行关系弱;
伦理和心理依赖风险;
同质化强。
7.3 第三梯队:家庭管理工具
代表:Nori、familymind、Honeydew、Cozi、shared calendar / meal planning / chore apps。
优势:
具体场景;
高频重复;
家庭多人协作;
AI 可处理自然语言、图片、邮件、学校通知。
弱点:
家庭协作产品留存难;
需要成员共同使用;
付费意愿需验证。
7.4 第四梯队:健康/营养/老人照护 AI
代表:AI health coach、nutrition AI、ElliQ、Alexa for Seniors、Google Nest Hub 等。
优势:
痛点强;
愿付费人群更明确;
可与硬件/医疗/保险/养老渠道结合。
弱点:
隐私、健康建议、责任边界要求高;
需要可信数据和人类审核;
老年用户交互门槛高。
八、用户痛点与机会矩阵
Top 5 用户痛点
家庭信息碎片化 :学校通知、工作日程、老人需求、购物清单散落在微信/短信/日历;
生活执行断点多 :知道要做,但没人持续提醒、分配、跟进;
照护焦虑 :老人、孩子、健康相关问题让家庭成员持续担心;
决策成本高 :买什么、吃什么、去哪儿、怎么安排,需要反复比较;
泛助手没有上下文 :ChatGPT 能回答,但不了解“我家”的真实情况。
非对称机会矩阵
机会
痛点强度
AI 解决难度
风险
判断
家庭事务协调助手
高
中
中
最推荐验证
老人提醒与陪伴助手
高
中高
高
可验证,但需责任边界
健康饮食执行助手
中高
中
高
有需求,但不能做医疗建议
消费决策助手
中
低
低
demo 容易,留存弱
泛个人助手
不确定
高
中
不建议切入
九、产品机会
机会 1:家庭事务协调助手
定义
一个面向家庭主理人/父母的 AI 家庭运营助手。
输入:
家庭成员日程;
学校/兴趣班通知;
菜谱/购物需求;
家务任务;
微信/短信/邮件截图或文本。
输出:
本周家庭计划;
购物清单;
家务分配;
提醒事项;
冲突检测;
每日家庭简报。
为什么最适合第一阶段
MVP
用户每晚发一段/几张截图:明天家庭事项。
AI 输出:明日家庭安排 + 购物/提醒/分工清单。
机会 2:老人提醒与陪伴助手
定义
面向成年子女,为老人提供提醒、陪伴、健康打卡和异常通知。
核心功能:
吃药提醒;
喝水/运动提醒;
每日问候;
情绪/异常状态提示;
子女简报。
优点
风险
健康和安全责任高;
老人使用门槛;
需要硬件/语音/微信生态;
不能替代医疗或护理。
机会 3:健康饮食执行助手
定义
面向想减脂、控糖、改善饮食的人,帮助做菜谱、购物、打卡和执行。
核心功能:
每周饮食计划;
购物清单;
外卖选择建议;
饮食记录;
运动提醒;
执行复盘。
优点
风险
健康建议合规风险;
需要数据准确;
用户容易三分钟热度。
十、商业模式
10.1 C 端订阅
适合家庭事务和健康饮食助手。
价格假设:
¥19 - ¥49 / 月
但必须证明高频留存,否则订阅难成立。
10.2 B2B2C / 渠道合作
适合老人照护和健康助手。
渠道:
养老机构;
社区服务;
保险公司;
健康管理机构;
企业员工福利。
10.3 服务包 / Concierge
早期最适合:
7 天家庭生活助理试用
先人工 + AI 交付,不急着做 App。
十一、反共识观点
共识 1:AI生活助手市场很大,所以值得做
反共识判断:市场大不代表项目好,泛生活助手是最危险的切法。
因为通用助手已经被 ChatGPT、Gemini、Siri、Alexa 等占据。创业团队做泛助手,会被入口、模型、系统权限和数据上下文同时压制。
置信度:高。
共识 2:AI 越像真人陪伴,用户越愿意付费
反共识判断:陪伴付费成立,但生活助手不一定要做陪伴。
家庭任务、老人照护、饮食执行需要的是可靠、可控、可审计的执行辅助,不是拟人聊天。过度拟人反而可能增加信任和责任风险。
置信度:中高。
共识 3:做 App 是自然选择
反共识判断:第一阶段不应该做 App,而应该做微信/飞书/表格/日历上的 concierge test。
生活助手的难点不是界面,而是是否有真实高频场景和持续使用动机。
置信度:高。
十二、Project Scoring
项目类型:research_probe + commercial_product 早期观察。
证据等级
证据类型
等级
说明
Lark 证据
L1/L2 边界
有真实话题根消息,但只有 1 条,缺少多轮讨论和样本
外部证据
L1
市场和竞品资料丰富,但不能替代内部真实需求
综合证据
L1+
可做研究和场景收集,不足以立项
评分表
维度
权重
分数
证据
备注
Demand reality
16
42
Lark 只有 1 条宽泛需求
具体用户和场景不清晰
AI workflow fit
12
70
外部竞品和场景支持
AI 适合计划、总结、提醒、推荐
Technical feasibility
10
72
MVP 可用现有工具完成
不建议先做 App
Validation feasibility
10
66
可做 7 天 concierge test
需要找到真实家庭/用户样本
Distribution reachability
10
45
暂无明确第一批用户
可从团队身边家庭样本开始
Business/value recovery
10
45
C 端付费待验证
老人/健康可能有付费方
Reuse and retention
8
58
家庭/健康场景有复用
泛助手留存不确定
Cost structure
8
68
模型成本低,人工服务成本可控
早期人工介入可接受
Risk and responsibility
8
48
老人/健康/隐私风险较高
必须限定非医疗/非安全决策
Tranfu fit
8
70
符合 AI Agent + 生活工作流探索
需收敛场景
最终评分
项目质量分:58 / 100
状态:重构方向 / 继续收集需求
证据等级:L1+
硬门槛检查
Gate
结果
User gate
未完全通过:目标用户太泛
Demand gate
未完全通过:缺频率、损失和当前替代方案
AI-fit gate
部分通过:垂直场景 AI fit 好,泛助手 AI fit 不清晰
Responsibility gate
条件通过:必须排除医疗诊断、心理干预、安全承诺
十三、7-14 天验证计划
唯一主线下一步
不要立刻做产品;先用 Lark 话题补采 3 个真实生活场景,并选 1 个做 7 天 concierge test。
Day 1-2:补拉 Lark 原始话题和内部样本
每个样本必须记录:
用户是谁
场景是什么
频率多高
现在怎么解决
哪里痛
是否愿意试用
是否愿意付费
Day 3:选择 3 个候选场景
建议候选:
家庭事务协调;
老人提醒与陪伴;
健康饮食执行。
Day 4-10:做 7 天 concierge test
优先选择“家庭事务协调”:
用户每天晚上发明天家庭事项;
AI 输出明日安排、提醒、购物清单、分工建议;
第二天收集是否有用、是否减少漏事。
Day 11-14:复盘和评分
通过标准:
至少 3 个用户完成 5 天以上试用;
用户每天愿意主动发信息;
至少 2 个用户认为“明显省心”;
至少 1 个用户愿意继续用或付费;
没有明显隐私/责任风险。
十四、MVP 设计
MVP:家庭事务协调助手
输入
明天/本周家庭事项;
学校/活动通知截图;
购物/做饭需求;
家庭成员时间限制;
重要提醒。
输出
明日家庭简报;
待办清单;
购物清单;
时间冲突提醒;
家务/任务分配建议;
晚间复盘问题。
交互方式
第一阶段不用 App:
Telegram / 微信 / Lark 群聊 + 表格记录 + AI 总结
边界
不做医疗诊断;
不做安全承诺;
不处理高敏隐私;
不自动决策,只做提醒和建议;
所有家庭成员数据最小化保存。
十五、事前验尸
假设 2 年后这个项目失败,最可能原因:
一开始做成泛生活助手,没有具体场景;
用户觉得 ChatGPT / Siri / Gemini 已经够用;
家庭协作需要多人使用,推广困难;
用户不愿持续输入生活数据;
隐私和信任问题阻碍留存;
健康/老人场景责任风险过高;
C 端订阅付费意愿不足。
我会改变看法的触发条件:
十六、最终建议
AI生活助手当前不应进入正式立项。
建议状态:
重构方向 / 继续收集需求
推荐方向:
从“AI生活助手”重构为“家庭事务协调助手”做小样本验证。
唯一主线下一步:
补拉 Lark 原始话题 + 收集 5 个真实生活样本 + 选家庭事务协调做 7 天 concierge test。
如果验证通过,再升级为:
先验证 / 小步立项候选
如果验证失败,继续观察,不投入产品开发。
参考来源
Lark / 内部来源
AI生活助手项目档案;
机会雷达前台总览;
Lark Topic Project Phase 1 Verification;
Lark topic ingestion fix 20260522;
Lark topic project workflow。
外部来源
Technavio: Personal AI Assistant Market Growth Analysis 2025-2029;
Precedence Research: Intelligent Virtual Assistant Market;
Market Research Future: Intelligent Personal Assistant Market;
a16z: State of Consumer AI 2025;
TechCrunch: AI companion apps revenue trend 2025;
Nori / familymind / Honeydew family AI assistant product materials;
Mordor Intelligence / healthcare market reports on AI personalized nutrition;
AI elderly care / companion robot market materials;
Crunchbase / TechCrunch AI agent startup funding materials。
数据链接
字段
内容
project_key
[已脱敏]:[已脱敏]
chat_id
[已脱敏]
thread_id
[已脱敏]
Base record_id
[已脱敏]
Wiki node
TY7Fwvaprib9FikQTHTluMHpgSP
Doc token
QBT4dtnC0oeuTPxqRV0letHXgUh
当前数据口径
1 条话题消息 / 1 条人类消息 / 0 条 AI 分析 / 0 个外部资源;后续需补真实生活场景样本。
项目增强分析(2026-06-02)
口径:基于最新项目维护报告、Lark 话题真实数据与可复核公开资料整理;web_search 当前不可用,因此未二次核验的市场判断均按“趋势/假设”保守处理。
project_id: ai_life_assistant
一句话机会
把“AI生活助手”从宽泛个人助理重构为一个高频、可验证的垂直生活场景助手,例如“家庭事务/本地生活决策/个人日程与消费执行”的轻量 Agent。
目标用户
一线/新一线城市中高压知识工作者、年轻家庭、独居人群。
有大量碎片化生活事务:购物、出行、缴费、预约、家庭日程、亲友提醒、账单和生活决策。
已使用 ChatGPT、豆包、Kimi、通义等通用助手,但缺少“持续记忆 + 场景执行 + 本地生活整合”的用户。
核心痛点
当前证据
内部话题数据
project_id:ai_life_assistant
current_status:观察 / 重构方向;优先级 P2;更新策略 low。
Wiki:TY7Fwvaprib9FikQTHTluMHpgSP;Doc:QBT4dtnC0oeuTPxqRV0letHXgUh。
话题负责人:空空。
消息/资源:1 / 0。
最近内部摘要仅有一句:“AI生活助手 AI帮你解决日常生活的问题”。
维护报告判断:只有出现明确生活场景、用户群、使用频次或付费线索时才更新。
外部资料与趋势
大模型厂商正在把聊天机器人升级为可执行任务的助手/Agent,说明“个人助理”是长期方向,但通用入口竞争极强。
可访问资料显示,Notion AI 的定位已从写作助手扩展为“Search, generate, analyze, and chat—right inside Notion”,反映 AI 助手价值正在嵌入用户已有工作/生活信息容器,而非单独泛问答。
Perplexity、OpenAI、Google Gemini、Apple Intelligence 等均在推进个人助理、手机入口、跨应用上下文和任务执行能力,独立创业项目需要避开“泛个人助理”正面竞争。
竞品 / 替代方案
通用 AI 助手:ChatGPT、Gemini、Claude、豆包、Kimi、通义千问。
手机系统助手:Siri/Apple Intelligence、Google Assistant/Gemini、荣耀/小米/OPPO/vivo 手机 AI 助手。
本地生活平台:美团、饿了么、携程、高德、滴滴、支付宝/微信服务入口。
垂直管理工具:日历、待办、记账、家庭共享清单、智能家居 App。
MVP 切口
建议不要做“万能生活助手”,先选一个可复用场景:
家庭生活运营 Copilot :家庭成员日程、购物清单、缴费、维修、旅行准备、孩子事务提醒。
本地生活决策助手 :基于预算/口味/距离/时间限制,帮用户筛选餐厅、亲子活动、周末安排。
个人事务 Inbox :用户把生活消息、截图、账单、提醒丢进一个入口,AI 自动分类、提醒和生成下一步。
推荐 MVP:家庭生活运营 Copilot。因为它更容易形成持续记忆与复购价值,也更适合后续和育儿/教育方向联动。
验证方式
找 10 个年轻家庭或高压职场用户,收集一周生活事务清单,统计高频任务与愿意外包的任务。
用飞书/Notion/微信机器人做 Wizard-of-Oz 原型:用户转发生活信息,人工+AI 生成提醒、清单、建议。
核心指标:每周主动提交事务数、提醒采纳率、节省时间主观评分、连续使用 2 周留存、愿意支付价格。
风险与反证
泛生活助手容易被手机系统级 AI 和大模型 App 吞掉。
本地生活执行依赖平台 API/生态合作,创业团队很难直接闭环。
用户对隐私敏感:家庭成员、账单、位置、日程属于高敏数据。
若用户每周生活事务提交少于 3 次,说明频次不足,不适合独立产品化。
下一步
把项目状态维持为“观察 / 重构方向”,不要进入开发。
补 10 个用户访谈,优先验证“家庭生活运营”是否有高频、强记忆、愿付费。
若两周内无法找到明确高频场景,建议合并到“育儿教育类产品”或“AI 卡片式工作台”的生活卡片模块。
参考来源链接
维护边界:本章节为 2026-06-02 增强分析受控块;后续若有新客户验证、竞品变化或 Lark 话题进展,可替换本章节,不覆盖原始档案正文。
项目质量升级(2026-06-03)
口径:本章节用于替换昨日偏模板化的增强稿表达;基于 Lark 话题真实数据、项目 mapping、既有维护报告与公开竞品格局,强调判断、边界、验证和反证。不覆盖原文其它章节。
project_id: ai_life_assistant
当前判断
这个项目现在不应该被理解成“做一个 AI personal assistant”。这个叙事太宽,正面撞上 ChatGPT、Gemini、豆包、Kimi、手机系统助手和本地生活超级 App。内部证据也很薄:只有一句“AI生活助手 AI帮你解决日常生活的问题”。
更合理的处理方式是:保留为 P2 观察 / 重构方向,等待它被一个具体生活场景重新命名。 目前最有希望的不是“回答日常问题”,而是“记住家庭上下文并持续处理小事务”:缴费、维修、购物、旅行准备、孩子事务、亲友提醒、周末安排。
如果两周内不能找到高频、强记忆、可重复提交的任务,应暂缓独立项目化,并考虑合并到 parenting_education_product 的家庭模块,或 ai_card_workspace 的个人/家庭卡片模块。
真实内部数据
标题:AI生活助手
project_id:ai_life_assistant
Wiki / Doc:TY7Fwvaprib9FikQTHTluMHpgSP / QBT4dtnC0oeuTPxqRV0letHXgUh
Lark thread:[已脱敏]
阶段 / 优先级:观察 / 重构方向;P2
更新策略:low
负责人:空空
数据来源:snapshot
消息 / 资源:1 条消息 / 0 个资源
最近消息摘要:AI生活助手 AI帮你解决日常生活的问题
证据等级:L1(只有概念句,无具体用户、场景、频次、替代方案、付费线索)
竞品 / 替代
通用 AI 助手 :ChatGPT、Gemini、Claude、豆包、Kimi、通义。它们覆盖问答、规划、写作和轻量建议,是泛助手方向的最大替代。
手机系统助手 :Siri / Apple Intelligence、Google Gemini、各国产手机 AI 助手。优势是系统权限、通知、日历、位置和跨 App 上下文。
本地生活平台 :美团、高德、携程、滴滴、支付宝、微信服务。真实执行能力强,独立助手很难绕过它们闭环。
家庭/个人管理工具 :日历、待办、记账、家庭共享清单、Notion/飞书/备忘录。它们不智能,但用户已有习惯。
MVP 边界
推荐 MVP:家庭生活运营 Copilot ,而不是万能生活助手。
只做:
用户把生活事务丢进一个入口:截图、语音、文字、账单、学校通知、维修事项。
AI 自动归类为:待办、提醒、购物、家庭成员事项、费用、出行、家政维修。
输出下一步:什么时候做、谁负责、需要准备什么、可选方案。
每周生成一页家庭生活复盘:未完成事项、下周提醒、可节省的钱/时间。
明确不做:
验证计划
7 天验证:生活事务日志
找 10 个目标用户:年轻家庭、高压职场用户、独居但事务多的人。
让他们连续 7 天记录生活待办和临时事务,不要求使用产品。
统计:每人每周事务数、重复事务占比、需要记忆上下文的事务占比、愿意外包给 AI 的事务。
访谈问题:哪 3 类最烦?如果 AI 提醒/整理/给方案,愿不愿意每周用?愿不愿意付费?
14 天验证:Wizard-of-Oz 家庭 inbox
风险反证
如果用户每周主动提交生活事务少于 3 次,频次不足,不适合独立产品。
如果用户只把它当通用问答,不愿交给它记忆家庭信息,则无法形成差异化。
如果任务最终都要跳到美团/高德/微信/支付宝手动完成,产品价值可能只是“提醒工具”。
如果用户对家庭隐私明显不放心,应降级为本地/私密模板工具。
如果育儿、家务、出行三个场景都能跑,但没有一个强,应合并到更具体项目,不保留泛生活助手。
下一步
暂不开发,先补 10 个用户的一周生活事务样本。
把候选切口限定在“家庭生活运营”“个人事务 inbox”“本地生活决策”三选一。
与 parenting_education_product 联动:如果父母端高频需求更强,就把生活助手降级为育儿家庭助手的基础设施。
两周后仍无高频场景,建议从项目看板降级为观察标签。
维护边界:本章节为 2026-06-03 质量升级受控块;后续新证据出现时可整体替换本章节。
维护说明
本档案是观察型项目主页,不是正式验证项目;不要因为“AI生活助手”概念大就自动提高优先级。
负责人默认取 Lark 话题 root message 的 sender;本项目话题发起人为“空空”,Lark 原始显示名为“杨林昆”。
自动维护只允许更新项目状态卡、最新进展、数据链接和维护说明;原有研究正文默认不覆盖。
只有出现明确生活场景样本、用户访谈、使用频次、付费线索或 MVP 切口时,才应更新项目判断或评分。
进入自动写入前,必须先通过 scripts/update_project_archives.py --project-id ai_life_assistant --fetch-docs 的 dry-run 门禁。
更新时间:2026-06-01
项目状态卡
字段
内容
当前阶段
机会池 / 今日新增
优先级
P2
当前评分
待正式评分
话题发起人
空空([已脱敏])
当前推进人
默认同话题发起人,待确认
最近更新时间
2026-06-01
当前判断
这是“金融市场可视化 + AI 研究 Agent / 金融领域 Cursor”的方向。价值空间较大,但合规、数据源、实时性和可信度要求高,不能一开始做泛金融全市场,应先选一个窄场景验证。
下一步
先选择一个细分市场(如美股财报/加密项目/宏观事件)做研究 Agent 原型:输入标的或问题,输出数据图表、关键变量、引用来源和可追踪研究结论。
维护策略
今日新增话题:先建立轻量项目档案和数据链接,后续根据讨论、资源、评分结果升级为正式档案。
最新进展
执行摘要
这是“金融市场可视化 + AI 研究 Agent / 金融领域 Cursor”的方向。价值空间较大,但合规、数据源、实时性和可信度要求高,不能一开始做泛金融全市场,应先选一个窄场景验证。
原始话题内容:AI金融分析工具,例如 TradingView 给各个金融领域、市场提供可视化,我们给各个金融领域提供更专业的 AI 分析。第二个定位是金融领域的 Cursor,可以持续进行金融领域的研究得到结果,并且 Cursor 现在可以通过 API 提供服务,软件不是必须的产品形态。
目标用户
待补:需通过后续讨论确认具体目标用户和购买/使用场景。
核心痛点
待补:当前只有初始机会描述,尚需提炼强痛点、现有替代方案和高频工作流。
当前证据
评分与判断
当前暂列 P2,待正式评分。评分前需要补充需求强度、AI 工作流适配、技术可行性、验证成本、分发路径和风险反证。
MVP / 验证计划
先选择一个细分市场(如美股财报/加密项目/宏观事件)做研究 Agent 原型:输入标的或问题,输出数据图表、关键变量、引用来源和可追踪研究结论。
风险与反证
数据链接
字段
内容
project_key
[已脱敏]:[已脱敏]
thread_id
[已脱敏]
Base record_id
[已脱敏]
数据口径
来自 2026-06-01 当天 Lark topic fresh fetch。
项目增强分析(2026-06-02)
口径:基于最新项目维护报告、Lark 话题真实数据与可复核公开资料整理;web_search 当前不可用,因此未二次核验的市场判断均按“趋势/假设”保守处理。
project_id: ai_financial_analysis_tool
基础信息
project_id:ai_financial_analysis_tool
Wiki node:DClywLz22ioXfykBph9lHZDAgve
Doc token:SNAwdGoYmoA1GMxW9gKlKn7ggOd
Base record:[已脱敏]
Lark thread:[已脱敏]:[已脱敏]
current_status:机会池 / 今日新增 / P2
负责人:空空([已脱敏])
内部话题数据:最新维护报告显示数据来源为 mapping,消息/资源 0 / 0;历史报告保留原始话题内容。
一句话机会
做一个“金融领域 Cursor / AI 研究 Agent”:面向特定金融市场,把数据可视化、事件追踪、资料阅读、假设验证和引用式研究报告串成可持续工作的 AI 分析流。
目标用户
加密/美股/港股/宏观方向的个人投资者、研究员、交易员。
小型投研团队、VC/二级基金、加密项目研究团队。
金融内容创作者、财经自媒体、策略社区运营者。
需要快速整理市场、财报、链上数据、新闻、研报的非机构专业用户。
核心痛点
信息过载 :行情、公告、新闻、社媒、研报、财报、链上数据分散,人工持续跟踪成本高。
工具割裂 :TradingView 做图表,Bloomberg/AlphaSense 做数据和搜索,ChatGPT 做文本,但无法持续记忆研究上下文。
AI 输出不可信 :金融场景需要引用来源、数据口径、时间戳、反证和风险提示,普通聊天机器人容易幻觉。
专业工作流缺位 :用户需要的是“持续研究某个标的/主题”,而不是一次性问答。
当前证据
内部话题数据
外部资料与趋势
TradingView 证明图表和社区化金融分析有广泛需求,但核心仍偏行情图表与指标。
Bloomberg Terminal、FactSet、Refinitiv/LSEG Workspace 等机构级产品强在数据源和工作流,但价格高、面向专业机构。
AlphaSense、Tegus、Fiscal.ai 等工具强化 AI 搜索、财报/电话会/研报摘要与企业情报分析。
Perplexity Finance、ChatGPT/Claude + 数据插件等降低了自然语言金融研究门槛,但专业可信、持续追踪和特定市场深度仍有缺口。
加密市场存在 Kaito、Token Terminal、DefiLlama、Nansen、Arkham 等数据/研究工具,说明“垂直市场 + 数据源 + AI 解读”更可行。
竞品/替代方案
TradingView :图表、指标、社区最强;AI 深度研究和多源资料整合不是核心。
Bloomberg Terminal / FactSet / LSEG Workspace :机构级全能工具;价格高、进入门槛高,不适合轻量用户。
AlphaSense / Fiscal.ai / Quartr :聚焦企业研究、财报电话会、文件搜索;适合美股/企业情报,但未必覆盖加密和中文用户。
Perplexity Finance / ChatGPT / Claude :自然语言研究入口强;弱点是数据源、实时性、可追踪研究流程和合规边界。
Kaito / Nansen / Token Terminal / DefiLlama / Arkham :加密数据和情报工具;AI 研究 Agent 仍有可组合空间。
MVP 切口
建议先切 “单一市场的引用式研究 Agent” ,推荐优先二选一:
方案 A:加密项目研究 Agent
输入项目名/Token/主题,自动汇总价格、TVL、链上指标、融资、团队、竞品、新闻、社媒和风险。
输出“投资研究卡片”:核心观点、数据图表、引用来源、风险反证、下一步观察指标。
优点:数据 API 相对开放,用户对 AI 研究接受度高;缺点:噪音和投机风险大。
方案 B:美股财报/电话会研究 Agent
输入股票代码,自动读取最新财报、earnings call、股价反应、分析师关注点。
输出“财报速读 + 关键变量追踪 + 下次验证点”。
优点:需求明确、付费能力较好;缺点:数据版权、机构竞品更强。
验证方式
先选 20 个标的做固定输出:例如 10 个加密项目或 10 只美股,连续 2 周每日/每周生成研究卡片。
邀请 5-10 个目标用户盲测:是否比他们自己用 TradingView + ChatGPT + 新闻源更省时间。
核心指标:用户是否收藏/转发研究卡片;是否追问同一标的;是否愿意订阅某个 watchlist;是否指出明显错误。
可信度验证:每条结论必须带来源链接、数据时间戳和反证;人工抽查事实错误率。
风险与反证
金融建议合规风险高,产品必须定位为研究辅助/信息整理,不给直接买卖建议。
数据源版权和实时性是硬门槛;如果无法稳定拿到可信数据,只能做低价值摘要。
泛金融范围过大,容易做成“会聊天的金融搜索”,难以形成差异化。
专业用户对错误容忍度极低;AI 幻觉会直接破坏信任。
如果用户只是要图表,TradingView 已足够;如果只是要问答,通用 AI 已足够。
下一步
在加密项目研究 Agent 与美股财报 Agent 中选一个 MVP 场景。
明确数据源清单和版权边界:行情、公告、财报、新闻、链上、社媒。
做 10 篇带引用的样例研究卡片,给目标用户评估“是否省时间/是否可信”。
建立金融免责声明与输出规范:不构成投资建议、标注来源、标注时间戳、列出反证。
参考来源链接
维护边界:本章节为 2026-06-02 增强分析受控块;后续若有新客户验证、竞品变化或 Lark 话题进展,可替换本章节,不覆盖原始档案正文。
项目质量升级(2026-06-03)
口径:本章节用于替换昨日偏模板化的增强稿表达;基于 Lark 话题真实数据、项目 mapping、既有维护报告与公开竞品格局,强调判断、边界、验证和反证。不覆盖原文其它章节。
project_id: ai_financial_analysis_tool
project_id :ai_financial_analysis_tool
标题 :AI 金融分析工具
Doc / Wiki :SNAwdGoYmoA1GMxW9gKlKn7ggOd / DClywLz22ioXfykBph9lHZDAgve
阶段 / 优先级 :机会池 / 今日新增 / P2
话题负责人 :空空
内部数据 :2026-06-03 维护报告中 topic_messages 为 0,但档案保留原始话题:类似 TradingView 为各金融市场提供可视化,本项目提供更专业的 AI 分析;另一个定位是金融领域 Cursor,可持续进行金融研究得到结果,且 Cursor 可通过 API 提供服务,软件不是必须形态。
当前判断
市场空间大,但不能做泛金融分析,也不能做“AI 荐股”。正确切口应是 有数据、有引用、有可复盘结论的金融研究 Agent 。
金融用户对“快”和“准”都敏感,但更重要的是可信度:数据源、引用、计算逻辑、假设、更新时间必须透明。MVP 应选择窄市场,例如美股财报、加密项目基本面、宏观事件影响,而不是覆盖股票、加密、外汇、期货全市场。
当前建议保持 P2,先做研究助手,不做投资建议产品。
用户 / 痛点
个人投资者 / 高阶散户 :信息多、时间少,希望快速理解标的和事件,但又不信黑箱结论。
加密/美股研究者 :需要聚合财报、公告、链上数据、新闻、价格图表。
投研团队助理 / 分析师 :大量重复资料整理、数据图表、纪要摘要、同业对比。
财经内容创作者 :需要快速形成可引用、可解释的研究素材。
痛点:
TradingView 等工具提供图表强,但用户仍需自己解释变量、事件和逻辑。
研究资料分散在财报、公告、新闻、社媒、数据库、研报。
ChatGPT 可解释概念,但实时数据、引用、计算和可追踪性不足。
金融结论一旦不透明,用户不敢使用。
竞品 / 替代
TradingView :图表、指标、社区成熟;AI 研究解释不是核心。
Bloomberg Terminal / FactSet / Refinitiv / Koyfin :专业数据和工作流强;价格高、面向专业机构。
Yahoo Finance / Seeking Alpha / Stock Analysis 等 :资讯和基础数据易用;研究自动化有限。
Perplexity / ChatGPT / Claude :适合问答和摘要;金融数据实时性、引用质量和计算稳定性需要额外约束。
加密分析工具如 Dune / Token Terminal / DefiLlama / Nansen :链上和协议数据强;跨源研究和自然语言假设验证仍有空间。
MVP 边界
推荐 MVP:单标的研究包生成器 。
优先从两个方向二选一:
MVP 必须包含:
数据来源和更新时间。
图表或表格。
关键结论对应引用。
假设与反证。
“这不是投资建议”的边界。
不做:
不做买卖点推荐。
不做自动交易。
不覆盖所有市场。
不做无引用的观点总结。
不做监管敏感的收益承诺。
验证计划
选择 10 个标的:5 个美股或 5 个加密项目,先人工 + 半自动生成研究包。
找 5 位真实研究/投资用户评估:是否节省时间、是否可信、是否愿意复用。
与 TradingView + ChatGPT + 手工搜索流程对比耗时。
核心指标:
研究包是否能节省 ≥ 50% 初筛时间。
用户是否能指出引用链可信。
结论错误率/引用错误率是否低于可接受阈值。
是否愿意为单份报告或月度监测付费。
风险反证
下一步
先选一个市场,不要同时做美股和加密。
定义标准报告模板:数据、图表、结论、引用、反证。
用 3 个真实标的手工跑通质量上限。
明确产品文案:研究助手,不是投资建议。
维护边界:本章节为 2026-06-03 质量升级受控块;后续新证据出现时可整体替换本章节。
维护说明
更新时间:2026-06-01
项目状态卡
字段
内容
当前阶段
机会池 / 今日新增
优先级
P2
当前评分
待正式评分
话题发起人
罗文印([已脱敏])
当前推进人
默认同话题发起人,待确认
最近更新时间
2026-06-01
当前判断
这是一个把“产品想法 → 需求澄清 → 市场/用户/竞品/趋势分析 → 产品运营动作”串成 AI 工作流的平台方向。方向有需求,但容易泛化成“AI 产品经理套壳”,需要先收敛到创业者/内部创新团队的早期产品定义场景。
下一步
先做一个 30 分钟 MVP:输入想法后,AI 追问 5 个边界问题,并输出一页 PRD 草案、目标用户、竞品列表和验证任务。
维护策略
今日新增话题:先建立轻量项目档案和数据链接,后续根据讨论、资源、评分结果升级为正式档案。
最新进展
执行摘要
这是一个把“产品想法 → 需求澄清 → 市场/用户/竞品/趋势分析 → 产品运营动作”串成 AI 工作流的平台方向。方向有需求,但容易泛化成“AI 产品经理套壳”,需要先收敛到创业者/内部创新团队的早期产品定义场景。
原始话题内容:AI 产品经理平台,用户只需要输入想法,网页上会帮它通过简短的提问明确需求和边界,然后分阶段输出市场分析、目标受众、竞争格局、行业趋势。第一版可以大概做这些,后面可以接管产品运营全流程。上线之后用户行为分析、用户画像绘制等等
目标用户
待补:需通过后续讨论确认具体目标用户和购买/使用场景。
核心痛点
待补:当前只有初始机会描述,尚需提炼强痛点、现有替代方案和高频工作流。
当前证据
评分与判断
当前暂列 P2,待正式评分。评分前需要补充需求强度、AI 工作流适配、技术可行性、验证成本、分发路径和风险反证。
MVP / 验证计划
先做一个 30 分钟 MVP:输入想法后,AI 追问 5 个边界问题,并输出一页 PRD 草案、目标用户、竞品列表和验证任务。
风险与反证
数据链接
字段
内容
project_key
[已脱敏]:[已脱敏]
thread_id
[已脱敏]
Base record_id
[已脱敏]
数据口径
来自 2026-06-01 当天 Lark topic fresh fetch。
项目增强分析(2026-06-02)
口径:基于最新项目维护报告、Lark 话题真实数据与可复核公开资料整理;web_search 当前不可用,因此未二次核验的市场判断均按“趋势/假设”保守处理。
project_id: ai_product_manager_platform
📌 一句话机会
把"产品想法 → 需求澄清 → 市场/用户/竞品/趋势分析 → 产品运营动作"串成 AI 工作流的平台,优先收敛到创业者/内部创新团队的早期产品定义场景 ——输入一句话想法,AI 追问边界后输出一页 PRD 草案、目标用户和验证任务。
🎯 目标用户
| 优先级 | 用户 | 痛点 |
|--------|------|------|
| P1 | 创业者 / 独立开发者 | 有想法但不确定怎么做产品定义,缺市场分析和竞品研究能力 |
| P1 | 公司内部创新团队 | 快速验证新想法,AI 辅助输出 PRD 草稿和验证任务 |
| P2 | 初级/转型产品经理 | 学习产品定义方法论,用 AI 模板启动产品文档 |
| P2 | 已有 PM 但需求积压的团队 | 加速想法→PRD→验证的流转,减少分析师耗时 |
🔥 核心痛点
从想法到 PRD 门槛高 :很多好想法缺结构化的产品定义流程
市场/竞品分析重复且耗时长 :每个新想法都要重新做
产品定义不严谨导致方向偏差 :缺少"边界追问"来验证假设
验证任务不清晰 :PRD 写完后不知道下一步该验证什么
运营阶段的工作流分散 :用户分析、画像绘制、行为分析需要多个工具切换
📊 当前证据
内部话题数据
"AI 产品经理平台,用户只需要输入想法,网页上会帮它通过简短的提问明确需求和边界,然后分阶段输出市场分析、目标受众、竞争格局、行业趋势。第一版可以大概做这些,后面可以接管产品运营全流程。上线之后用户行为分析、用户画像绘制等等。"
外部资料/行业趋势(基于已有档案推理)
市场上已有"AI PRD 生成"类工具(如 Vondy、Figma AI、Productboard AI 等),但多为单项功能而非全流程平台
创业者/独立开发者的"想法→产品"问题是 AI 应用层共识方向(Y Combinator、ProductHunt 热门标签)
竞品多为单点工具:AI 需求分析(craft.io)、AI 竞品分析(Exploding Topics、Similarweb AI)、AI 用户画像
"完整产品运营全流程"的产品形态在市场上尚无明确赢家,说明有机会但需要高度收敛
内部已有相关沉淀:Product Demand Automation 项目(群聊需求自动识别/沉淀)、AI Interview 项目(求职者面试辅助)
竞争格局(间接推断)
| 类型 | 代表 | 特点 |
|------|------|------|
| AI PRD 生成 | Vondy AI、Figma AI、Productboard AI | 单点功能,非全流程 |
| AI 竞品/市场分析 | Exploding Topics、Similarweb AI、G2 | 分析报告为主,不连接产品定义流程 |
| AI 产品需求管理 | Notion AI、Linear AI、Craft AI | 偏向协同和文档,非产品定义引擎 |
| 全流程产品平台 | 目前无明显赢家 | 机会最大,但产品复杂度最高 |
🏗️ MVP 切口
推荐路径:30 分钟轻量验证
不 做完整全流程平台;先 做"想法→PRD 草稿"单点验证。
MVP 功能(可 30 分钟内完成) :
交付形态 :
✅ 验证方式
找 3-5 位目标用户 (创业者、公司内创新团队、初级 PM)
让每人输入一个真实想法 ,观察:
关键指标 :
用户愿意继续用 ≥ 60%
用户愿意把输出给团队讨论 ≥ 50%
"我学到了新东西"反馈率 ≥ 40%
⚠️ 风险与反证
| 风险 | 可能性 | 影响 | 缓解 |
|------|--------|------|------|
| 泛化成"AI PM 套壳" | 高 | 致命 | 严格收敛到"想法→PRD 草稿"单点 |
| 竞品快速出现(ChatGPT 等通用 AI 已能回答类似问题) | 高 | 严重 | 差异化不是生成内容,而是追问边界+结构化输出+验证任务 |
| 输出质量不稳定导致用户不信任 | 中 | 中 | 固定模板 + 人工校对 |
| 用户痛点不够强:有多少人"想做产品定义但缺方法" | 中 | 中 | 通过用户访谈验证 |
| 同类话题内部沟通未形成连续讨论 | 中低 | 中 | 需要推动话题讨论 |
我会改变看法的触发条件 :
📋 下一步
第 1 步(30 分钟):搭建追问+PRD 草稿输出 MVP 原型
第 2 步(7 天):找 3-5 位目标用户做 concierge test
第 3 步(通过后):固定追问模板和输出格式,制作简单 landing page
第 4 步(中期):考虑是否集成市场分析/竞品分析/用户行为分析模块
不建议 的路线:一开始做完整全流程产品运营平台 / 用户行为分析 / AI 画像绘制 = 过早泛化
🔗 参考来源链接
内部产品需求自动化项目:docs/memory/projects/product-demand-automation/
内部 AI 面试产品项目:docs/memory/projects/ai-interview/
ProductHunt / Y Combinator 共识:AI 应用层"想法→产品"方向
竞品参考:Vondy AI、Productboard AI、Craft AI、Notion AI
行业报告:Gartner "AI in Product Management" (2025) — 待补充公开来源
维护边界:本章节为 2026-06-02 增强分析受控块;后续若有新客户验证、竞品变化或 Lark 话题进展,可替换本章节,不覆盖原始档案正文。
项目质量升级(2026-06-03)
口径:本章节用于替换昨日偏模板化的增强稿表达;基于 Lark 话题真实数据、项目 mapping、既有维护报告与公开竞品格局,强调判断、边界、验证和反证。不覆盖原文其它章节。
project_id: ai_product_manager_platform
project_id :ai_product_manager_platform
标题 :AI 产品经理平台
Doc / Wiki :S8uPd237voLE3QxAP5clDlk3g6c / AcC8w8p0fiOdQqkLoMFlVW4KgBg
阶段 / 优先级 :机会池 / 今日新增 / P2
话题负责人 :罗文印
内部数据 :2026-06-03 维护报告中该项目来自 mapping,topic_messages 为 0;档案 plain 文本保留原始话题:用户输入想法,网页通过简短提问明确需求和边界,然后分阶段输出市场分析、目标受众、竞争格局、行业趋势,后续可接管产品运营、用户行为分析、画像绘制等。
当前判断
方向成立,但最大风险是过宽:如果从一开始就说“AI 产品经理平台”,很容易滑向模板化 PRD 生成器、市场分析生成器、Notion AI 页面或通用 Agent 套壳。
更好的切法是:服务早期产品机会验证,把模糊想法压缩成可执行的 MVP 假设、验证计划和下一步任务 。它不应该替代完整产品经理,而是帮助创业者/小团队把“我有个想法”推进到“本周可以验证什么”。
当前建议保持 P2,先做“30 分钟产品定义工作流”。
用户 / 痛点
独立开发者 / AI 小工具创业者 :点子多、开发快,但需求边界、用户定义、验证任务混乱。
2-10 人早期团队 :没有专职产品经理,需要把想法整理成可开发、可验证的任务。
内部创新 / 机会雷达团队 :需要把机会话题转成项目档案、评分、MVP、验证记录。
Agency / 产品顾问 :需要更快地产出需求澄清、竞品初筛和方案草案。
痛点:
想法容易停留在一句话,没有目标用户、痛点、替代方案、验证指标。
ChatGPT 能生成 PRD,但经常不追问关键边界,输出“看起来完整但不可执行”。
市场分析、竞品、用户画像、MVP、埋点、反馈复盘分散在不同工具。
产品上线后,AI 代码工具不知道此前的商业假设和用户反馈。
竞品 / 替代
ChatGPT / Claude / Gemini :最强通用替代;弱点是缺固定工作流、项目记忆和验证闭环。
Notion AI / Coda AI / 飞书妙记/多维表格 AI :适合文档协作和知识整理;不专门围绕产品机会推进。
Productboard / Aha! / Jira Product Discovery / Linear :成熟需求和路线图工具;更偏已有产品团队,不解决“从想法到验证”的早期混沌。
Miro / FigJam / Whimsical :适合头脑风暴和流程图;AI 只能辅助,不承担验证推进。
各类 PRD 生成器 :输出快,但往往模板化、缺真实用户和后续执行。
MVP 边界
推荐 MVP:产品想法澄清器 + 验证任务生成器 。
输入:一句产品想法。
流程:AI 只追问 5 个关键问题:
谁最痛?
现在怎么解决?
为什么现在会换?
第一版只做哪一个场景?
用什么证据判断继续/停止?
输出:
不做:
不做完整 PM SaaS。
不做研发项目管理、排期、绩效。
不自动生成长 PRD。
不声称能接管产品运营全流程。
不做泛市场报告生成。
验证计划
选 10 个真实机会话题,使用该流程生成机会卡。
让 3 类用户评估:独立开发者、早期团队负责人、产品经理。
和“直接问 ChatGPT 生成 PRD”对比,看哪一个更能推动下一步行动。
核心指标:
用户是否认为输出减少了澄清时间。
是否愿意按输出执行 7 天验证。
生成内容中多少需要人工重写。
是否愿意每月为机会库/验证闭环付费。
风险反证
下一步
把当前 Opportunity Hub 的项目档案结构抽象成第一个 demo。
用 5 个内部机会跑一遍,记录人工修改点。
先做网页表单 + Markdown 输出,不做账号系统。
如果内部连续使用 2 周仍有价值,再考虑外部访谈。
维护边界:本章节为 2026-06-03 质量升级受控块;后续新证据出现时可整体替换本章节。
维护说明
项目档案|交互式知识书 / AI 教材
更新时间:2026年05月26日 11:36(北京时间)
项目状态卡
字段
内容
当前阶段
先验证
优先级
P1
当前评分
68 / 100(正式评分);看板分 88
话题发起人
亚洲詹姆斯([已脱敏])
当前推进人
默认同话题发起人;若后续有明确样例负责人,再人工更新
最近更新时间
2026-06-01
当前判断
交互式知识书 / AI 教材值得进入先验证阶段,但不能只停留在“AI 教材有前景”的概念判断。第一阶段必须收敛到一个具体用户、一个具体主题和一个可被真实用户体验的样例。
下一步
用 7-14 天做一个最小交互式知识书样例,验证用户是否能更快理解、更愿意完成学习,并收集留存、反馈和付费意愿;通过后再决定是否进入 Demo 开发。
维护策略
中频更新:重点更新样例验证、目标用户、内容主题、产品形态、留存反馈和付费反馈。
最新进展
2026-06-01:补齐项目档案维护结构,并将项目映射到 Lark 话题 thread_id:[已脱敏]。当前保留原正文“正式评分 68 / 100、先验证”的判断,只新增项目状态卡、最新进展、数据链接和维护说明。
2026-05-24 至 2026-05-26:话题内已累计 23 条消息、13 条人类消息、10 条 AI/App 分析、8 个资源,说明该方向已有较多内部讨论,适合进入样例验证,而不是只停留在研究报告。
2026-06-02:完成 01 项目档案受控区块维护:同步当前 project_key / thread_id / Base record_id / Wiki 文档链接,并按最新话题数据校验项目状态、负责人、证据链接与下一步维护边界。
执行摘要
交互式知识书 / AI 教材是一个值得进入 先验证 阶段的项目方向。它不是简单的“把教材搬到线上”,也不是普通 AI 问答工具,而是把知识内容升级为 可互动、可追问、可测验、可反馈、可个性化推进 的学习产品。
当前在 AI机会雷达中的最新正式口径应统一为:
这意味着它值得继续推进,但还不适合直接重投入开发。当前最重要的不是泛泛讨论“AI 教材很有前景”,而是尽快收敛:
第一版到底服务谁;
第一版到底教什么;
第一版到底是一本交互式知识书、一个 AI 导学产品,还是一个学习工作流工具;
用户是否愿意持续使用,而不是只体验一次。
我的综合判断是:
这个方向很适合作为 AI Agent 养成记 / AI 公司养成记 体系中的内容型 + 产品型项目,但必须先选一个最小切口,用 7-14 天做出可以被真实用户使用和反馈的样例。
一、项目定义
项目名称
交互式知识书 / AI 教材
项目类型
commercial_product(可兼容内容产品 / 教育工具 / 企业知识产品)
一句话定义
把传统静态知识内容升级为 可互动、可提问、可测验、可个性化引导的 AI 学习产品 。
核心价值
不是“提供知识”,而是:
降低理解门槛
缩短学习路径
提高完成率
增强反馈感
让知识从“读过”变成“学会”
它不是什么
为了避免定义过宽,先明确它不等于 :
普通电子书
纯 AI 问答机器人
传统录播课平台
泛教育大平台
一个什么都能学的“万能 tutor”
它更像是:
把某一类知识内容做成一个可互动的学习体验层,让用户边读、边问、边练、边反馈,而不是被动阅读。
二、当前正式结论
当前统一评分口径
项目 │ 分数 │ 说明
─────────┼─────────────────────┼─────────────────────────
看板分 │ 88 │ 用于机会排序、热度判断
正式评分 │ 68 │ 用于正式评审、立项判断
正式结论 │ 先验证 │ 不是立即立项,也不是暂停
当前阶段 │ 待轻量研究 / 待验证 │ 应尽快进入样例验证
评分唯一性说明
如果其他文档里出现:
更高的概念性判断
更宽泛的“值得做”结论
没有区分看板分和正式评分
则应以本次统一口径为准:
正式评分 = 68 / 100,正式结论 = 先验证。
后续如果分数变化,应先更新 Score History,再回写项目档案。
三、为什么值得看
这个项目值得看,不是因为“教育一直很大”,而是因为它处在一个明确变化点上:
1. 静态知识内容的体验已经落后
传统知识产品的问题很明显:
读者不知道从哪里开始
看不懂时没有即时反馈
不知道自己学没学会
内容与个人水平不匹配
学习过程难以持续
2. AI 能真正改善学习过程,而不只是生成内容
AI 在这个方向上的价值,不是再写一份教材,而是:
把知识点解释成不同难度版本
根据用户提问即时补充案例
自动生成练习和测试
判断用户卡在哪
给出下一步学习建议
3. 内容 + 工作流 + 反馈,比“泛 AI 教育”更适合切小场景
大平台做的是通用教育入口,但小团队更适合做:
一类人群
一类知识
一种学习目标
一套交互式学习体验
这使它更适合作为机会雷达里的一个可验证、可沉淀项目,而不是大而全叙事。
四、当前项目的关键问题
虽然值得看,但这个方向现在还没收得足够窄。
当前最核心的 4 个问题
1)目标用户还不够清晰
目前可能的用户包括:
想系统学 AI 工具的普通用户
想提升某项能力的职场人
企业内部培训场景
考试/证书学习用户
专业知识学习用户
这些用户的动机和付费方式差异很大,不能混在一起。
2)首个内容主题还没定
如果第一本“知识书”是什么都没定,产品就会一直停留在概念层。
必须先选一个:
AI 工具入门
产品经理 AI 工作流
商业分析方法
某类考试/培训内容
某个行业的标准知识模块
3)产品形态还没定
当前至少有三种可能形态:
交互式知识书 :偏内容产品
AI 教材 / 导学工具 :偏学习工具
学习工作台 :偏系统化学习体验
如果不先选一个最小形态,就容易做得过重。
4)留存和付费还没验证
很多人会愿意体验,但不一定愿意持续使用。
所以第一阶段要验证的不是“大家觉得不错”,而是:
是否愿意认真学完
是否愿意回来继续用
是否觉得比普通文档/课程更有效
是否愿意付费或推荐给别人
五、目标用户建议
我建议先不要做“面向所有人的 AI 教材”,而是先选一个最容易验证的用户群。
推荐优先级
优先级 1:职场型知识学习用户
例如:
想系统学习 AI 工具的人
想学 AI 工作流的人
想快速掌握某个新方向的人
优势:
场景明确
愿意自驱学习
更容易接受交互式内容
也更适合内容传播
优先级 2:企业内部培训场景
例如:
优势:
难点:
优先级 3:考试/标准课程人群
优势:
难点:
当前建议
第一阶段优先建议:
从“职场型 AI 知识学习”切入。
因为它最适合与当前“AI Agent 养成记 / AI 公司养成记”主线结合,也最容易做出第一本样例。
六、首个切口建议
这是当前最重要的部分。
我建议第一版不要做“通用 AI 教材”
而要做:
一个聚焦的交互式知识书样例
例如:
方案 A:AI 工具与工作流入门
适合人群:想系统理解 AI 工具和工作流的职场人
可做内容:
什么是 AI 工作流
常见 AI 工具怎么分层
怎么选择工具
怎么设计最小工作流
常见误区和案例
优点:
与当前团队主线一致
更容易产出第一版样例
适合传播
方案 B:AI 项目评审入门知识书
适合人群:想理解“怎么找项目、怎么打分、怎么判断方向”的人
优点:
和机会雷达主线强绑定
可以直接服务当前团队方法论沉淀
适合内部 + 外部双重使用
方案 C:某个垂直能力主题
例如:
产品经理如何用 AI
招聘流程里的 AI 应用
GEO/AEO 入门导学
优点:
当前推荐
如果要快速启动,我最推荐:
先做《AI 项目评审 / AI 工作流入门》的交互式知识书样例。
原因:
与你现在手头机会雷达最贴近
可直接复用已有文档和研究
最容易在短时间内做出 demo
也最符合“AI 公司养成记”的公开过程叙事
七、评分细则(正式版)
当前正式评分
68 / 100
正式结论
先验证
评分维度拆解
维度 │ 权重 │ 分数 │ 判断
──────────────┼──────┼──────┼────────────────────────────────────────────
需求真实性 │ 16 │ 82 │ 学习反馈、个性化引导、完成率提升是明确需求
AI 工作流适配 │ 12 │ 78 │ AI 很适合做解释、追问、练习、反馈
技术可行性 │ 10 │ 72 │ 样例级产品容易做,但完整系统要更复杂
验证可行性 │ 10 │ 86 │ 7 天内可做一个样例给真实用户试用
分发可达性 │ 10 │ 66 │ 传播可做,但首批精准用户仍要定义
商业/价值回收 │ 10 │ 66 │ 用户价值明确,但付费模式还需验证
复用与留存 │ 8 │ 86 │ 如果内容/路径设计得好,复用和持续学习潜力强
成本结构 │ 8 │ 70 │ 内容生产与交互设计有成本,但可控
风险与责任 │ 8 │ 72 │ 教育效果、内容准确性和版权要关注
Tranfu 适配度 │ 8 │ 76 │ 适合当前团队方法论沉淀与公开叙事
总结
这个分数说明:
这个方向值得做样例验证 ;
但还没有到“可以重投入、直接做大产品”的程度;
最关键的是先验证:
用户是否愿意持续使用
学习效果是否比普通文档更好
一个小主题能否形成明确价值
八、核心风险与反证
风险 1:看起来很有价值,但其实只是“更炫的文档”
如果最终用户体验只是“AI 帮你解释一下内容”,那它很可能被通用大模型直接替代。
风险 2:内容制作成本太高
如果每一本“知识书”都要重度定制,规模化会很难。
风险 3:学习效果无法明显优于传统内容
如果用户觉得:
看普通文档也行
看视频也行
直接问 ChatGPT 也行
那产品价值不成立。
风险 4:用户会体验,但不会留存
学习产品常见问题不是首用,而是复用。必须验证用户是否愿意第二次、第三次回来继续使用。
九、会议讨论建议
如果下午会议讨论这个项目,我建议重点围绕下面几个问题:
1. 我们第一版到底服务谁?
普通职场用户
AI 初学者
企业培训场景
某个垂直专业学习场景
2. 第一版做哪本书?
建议必须现场定一个具体主题,不要散。
3. 我们要验证的到底是什么?
不是验证“这个方向有没有想象力”,而是验证:
是否有人认真使用
是否觉得更高效
是否愿意继续学
是否值得沉淀更多内容
4. 我们当前更像内容产品,还是工具产品?
这个需要统一,不然团队后续会做散。
十、7-14 天验证计划
验证目标
验证“交互式知识书 / AI 教材”是否能在一个小主题上显著提升学习体验和完成意愿。
验证对象
建议选:
验证样例
先做一本最小样例:
主题:AI 项目评审 / AI 工作流入门
结构:5-8 个知识模块
每模块包含:
核心概念
例子
可追问解释
小测验
学习建议
验证动作
做出第一版交互式知识书样例
找 5 位用户完整体验
收集:
完成率
提问次数
哪一部分最有价值
哪一部分最容易流失
是否愿意继续学下一章
对比普通文档阅读体验
成功标准
满足其中 3 条即可视为验证通过:
超过 60% 用户愿意完整体验主要模块
超过 60% 用户认为比普通文档更易理解
超过 40% 用户愿意继续使用第二次
明确出现“这个方式更适合我学习”的反馈
产生明确的后续主题需求
停止标准
若出现以下情况,应停止扩大投入并重构:
大多数用户只觉得新鲜,但不愿继续使用
学习效果没有明显优于普通文档
内容制作成本远高于预期
主题过宽导致样例迟迟无法做完
十一、当前建议动作
当前结论
这个项目值得保留,而且值得进入小样例验证 。
当前最优动作
不是继续抽象讨论“AI 教材是不是机会”,而是:
立刻确定一个最小主题,做一本交互式知识书样例。
我建议的唯一主线下一步
先做《AI 项目评审 / AI 工作流入门》交互式知识书 Demo,用 5 位目标用户做 7 天验证,再决定是否升级为正式产品方向。
十二、需要同步到 Lark 的字段建议
如果后续把这份项目档案写回 Lark,建议同步以下内容:
项目档案页
正式评分:68
正式结论:先验证
当前阶段:待轻量研究 / 待验证
下一步动作:做交互式知识书样例并完成 5 人验证
Score History
新增一条正式评分记录:68 / 先验证
标注当前验证主题和验证计划
Opportunities
保留看板分 88
明确区分“看板分”和“正式评分”
更新当前阶段与下一步动作
Daily Briefs / 每日更新
数据链接
字段
内容
project_key
[已脱敏]:[已脱敏]
chat_id
[已脱敏]
thread_id
[已脱敏]
Base record_id
[已脱敏]
Wiki node
LgyAw8JRci185okJC83lrNTzgLf
Doc token
GZmhdfbE5oWDsnxLhf2lSMFFgpc
当前数据口径
23 条消息 / 13 条人类消息 / 10 条 AI 分析 / 8 个资源;来源为 recent topic snapshot 与项目档案正文。
项目增强分析(2026-06-02)
口径:基于最新项目维护报告、Lark 话题真实数据与可复核公开资料整理;web_search 当前不可用,因此未二次核验的市场判断均按“趋势/假设”保守处理。
project_id: interactive_ai_textbook
project_id :interactive_ai_textbook
Wiki / Doc :LgyAw8JRci185okJC83lrNTzgLf / GZmhdfbE5oWDsnxLhf2lSMFFgpc
阶段 / 优先级 :先验证 / P1
更新策略 :medium
话题负责人 :亚洲詹姆斯
内部话题数据 :23 条消息 / 8 个资源;最近摘要显示此前处理链路出现超时与回写失败,话题中提到“15 分钟太久”“2 分钟”“PPT 应该是没了”,说明团队关注点已经从概念转向“内容生成/交互产物的速度、交付物形态与可发送正文”。
一句话机会
把静态知识内容升级为“可对话、可练习、可生成讲解/测验/课件”的 AI 知识书,优先切入创作者、培训师、老师和知识型团队的轻量课程生产,而不是一开始做完整 K12 学习平台。
目标用户
知识创作者 / 课程作者 :有长文、PPT、资料包,希望快速变成交互式课程或训练营内容。
企业培训 / 内训负责人 :需要把 SOP、产品文档、销售话术变成可问答、可测验的学习材料。
老师 / 教研人员 :需要备课、生成讲义、练习题、讲解脚本,降低重复备课成本。
自学者 / 学习社群运营者 :希望围绕一本书、一组资料形成持续学习陪跑。
核心痛点
静态资料“不好学”:读者容易只收藏不学习,缺少即时答疑、练习和反馈。
课程生产成本高:从资料到大纲、讲义、测验、PPT、案例,需要大量人工整理。
AI 学习工具常偏“泛聊天”:缺少围绕指定资料的结构化学习路径、题目、复盘和进度。
交付链路敏感:内部话题已暴露“15 分钟太久、回写正文失败”等问题,说明用户对速度与稳定交付很敏感。
当前证据
内部证据
维护报告显示该话题已有 23 条消息 / 8 个资源 ,是 Batch B 中内部沉淀最多的项目。
阶段为 先验证 / P1 ,不是纯机会池,说明已有较明确验证价值。
最近消息聚焦在“处理结果已收到但回写链路没拿到正文”“15 分钟太久”等,反映真实验证中首先卡在生成时长、输出形态、可靠交付,而不仅是概念讨论。
外部资料
Khan Academy 的 Khanmigo 定位为 “AI-powered teaching assistant & tutor”,说明 AI 助教/导师已被头部教育机构产品化,但更偏学校/老师/学生场景。
Google NotebookLM 定位为 “AI research tool and thinking partner”,可分析用户资料、把复杂内容变清晰,证明“基于资料的 AI 学习/研究伙伴”需求已被大厂验证。
MagicSchool 定位为面向 school districts 的 AI 平台,主打教师和学校工作流,说明教育 AI 的机构端工具市场正在形成。
竞品 / 替代方案
Khanmigo :AI tutor + teaching assistant,强教育品牌,但更偏正式教育体系。
Google NotebookLM :资料问答、摘要、Audio Overview 等能力强,适合研究和学习,但不天然是“可发布的互动教材产品”。
MagicSchool :教师工作流工具集合,覆盖备课、生成教学材料、学校管理场景。
替代方案 :Notion/飞书文档 + ChatGPT/Claude、Gamma/Canva 做课件、Quizizz/Kahoot 做测验;用户可以拼工具完成,但流程割裂。
MVP 切口
建议先做 “资料 → 交互式知识书”生成器 ,避开完整教育平台:
上传/粘贴一份资料:文章、PPT、课程大纲、产品文档。
2 分钟内生成:章节大纲、每章一句话解释、3-5 个关键问题、随堂测验、可对话问答入口。
输出一个可分享页面:读者可按章节学习、问问题、做小测、查看复盘。
首批主题建议:AI 工具课、产品方法论、销售培训、投资研究入门,优先成人学习/企业培训,降低 K12 合规风险。
验证方式
速度验证 :从资料上传到可分享知识书,P95 小于 2-3 分钟;超时则先流式生成章节。
留存验证 :读者是否完成至少 2 个章节、是否完成测验、是否二次提问。
付费验证 :创作者/培训师是否愿意为“生成 + 发布 + 学员数据”按月付费。
替代验证 :让 5-10 位老师/培训师用 NotebookLM + Notion/Gamma 自行拼流程,对比本产品节省时间和交付质量。
风险与反证
大厂资料问答工具快速覆盖基础能力,单纯“上传资料问答”没有壁垒。
教育场景合规要求高,尤其涉及未成年人、学习评价、隐私和内容准确性。
如果用户只需要一次性总结/PPT,而不是持续学习,产品会退化成低频生成工具。
内部已经出现链路超时和回写失败,若不能稳定交付,会直接影响验证。
下一步
选 3 个真实资料包做 demo:产品文档、AI 工具教程、销售培训材料。
固定输出形态:可分享页面 + 章节卡片 + 问答 + 小测,不先做复杂 PPT。
招募 5 位创作者/培训师试用,观察是否愿意把成品发给真实学员。
记录生成耗时、完成率、二次提问率、用户手动修改点,作为 P1 是否升级依据。
参考来源链接
维护边界:本章节为 2026-06-02 增强分析受控块;后续若有新客户验证、竞品变化或 Lark 话题进展,可替换本章节,不覆盖原始档案正文。
项目质量升级(2026-06-03)
口径:本章节用于替换昨日偏模板化的增强稿表达;基于 Lark 话题真实数据、项目 mapping、既有维护报告与公开竞品格局,强调判断、边界、验证和反证。不覆盖原文其它章节。
project_id: interactive_ai_textbook
当前判断
这个方向的内部热度高于普通 P1 项目:23 条消息、8 个资源,并且讨论已经暴露出真实产品问题——不是“AI 能不能生成教材”,而是 生成速度、交付形态、回写稳定性、2 分钟内能不能给出可用正文 。
当前判断:P1,先验证;优先做资料到交互式知识书的生成器,而不是完整教育平台。 最适合先服务成人学习、企业培训、创作者课程,不要一开始进入 K12 和未成年人学习评价。
真实内部话题数据
项目名:交互式知识书 / AI 教材
project_id:interactive_ai_textbook
Wiki / Doc:LgyAw8JRci185okJC83lrNTzgLf / GZmhdfbE5oWDsnxLhf2lSMFFgpc
Lark thread:[已脱敏]
阶段 / 优先级:先验证;P1
更新策略:medium
负责人:亚洲詹姆斯
数据来源:snapshot
消息 / 资源:23 条消息 / 8 个资源
维护门禁:PASS
最近话题脉络:话题中出现过 bridge 收到消息但本地 agent 超时、回写链路未拿到可直接发送正文;用户反馈“15 分钟太久”“2 分钟”“PPT 应该是没了”。这说明团队已经在用真实任务压力测试“内容生成 + 交付”链路。
证据等级:L3-(内部互动密集、有真实链路问题;仍缺外部用户验证、真实学习完成率和付费信号)
外部竞品 / 替代方案
Khanmigo :AI tutor + teaching assistant,教育品牌强,适合正式学习和老师/学生场景,但不是“创作者一键发布互动教材”的工具。
Google NotebookLM :资料理解、问答、摘要、Audio Overview 很强,是最直接替代。弱点是更像研究/学习伙伴,不天然提供课程发布、测验、学员进度和创作者商业化。
MagicSchool :教师工作流工具,适合学校和老师,覆盖备课、题目、课堂材料;但更偏教育机构,不一定服务企业培训/知识创作者。
Gamma / Canva / Tome :能从资料生成演示文稿,但交互学习、测验和持续问答不足。
Notion/飞书文档 + ChatGPT/Claude :用户可以手工拼出大纲、题目、讲义,但流程割裂、交付形态不统一。
Kahoot / Quizizz :测验互动强,但不是完整知识书生成器。
MVP 做什么
MVP:资料 → 交互式知识书。
用户上传或粘贴一份资料,例如文章、PPT、课程大纲、销售手册、产品文档。系统在 2-3 分钟内生成:
章节大纲;
每章一句话解释;
每章 3-5 个关键问题;
随堂小测;
可对话问答入口;
一个可分享页面。
首批主题建议:AI 工具课、产品方法论、销售培训、投资研究入门、内部 SOP 培训。先服务成人学习,避免儿童教育合规复杂度。
MVP 不做什么
不做 K12 全学科 AI 教材平台。
不做复杂 PPT 生成器;内部已有信号表明 PPT 形态可能太慢、太重。
不做学习管理系统 LMS:班级、排课、作业批改、成绩管理都暂缓。
不做视频课程生成。
不做开放社区和学生社交。
不承诺知识完全正确,必须保留来源引用和人工校对入口。
不做所有资料类型,首版优先纯文本/PDF/网页/简单 PPT 内容。
7 天验证计划
Day 1:选 3 个真实资料包:一份产品文档、一份 AI 工具教程、一份销售/培训资料。
Day 2:定义固定输出结构:章节卡片、关键问题、小测、问答入口、复盘建议。
Day 3:用现有模型/API 生成 3 个 demo,不做前端也可以先用静态页面或 Markdown + 简单交互。
Day 4:压测生成耗时,目标 P95 小于 3 分钟;如果超过,改成先出大纲,再逐章流式补全。
Day 5:找 5 位创作者/培训/老师角色试读,让他们判断是否愿意发给真实学员。
Day 6:让 5-10 位学习者体验至少 1 个章节,记录完成率、提问数、小测完成率。
Day 7:复盘创作者修改点和学习者卡点。
7 天通过门槛 :创作者愿意发布率 ≥ 40%;学习者至少完成 2 个章节的比例 ≥ 50%;生成到可分享初稿 P95 ≤ 3 分钟。
14 天验证计划
Week 2 前 3 天:选择一个最有反馈的主题,把 demo 改成可分享页面。
Week 2 第 4-5 天:让 1 位创作者/培训负责人把它发给真实小群体,不少于 10 个学习者。
Week 2 第 6 天:收集学习数据:章节完成、二次提问、测验完成、收藏/转发、人工修改量。
Week 2 第 7 天:验证付费:创作者是否愿意为生成/发布/数据统计付费,或企业培训是否愿意按资料包付费。
14 天通过门槛 :至少 1 个真实知识书被发给真实学习者;学习者完成率和二次提问率明显高于普通文档;创作者愿意为节省时间或学员数据付费。
风险反证
如果用户只想要“一次性总结”或“一页 PPT”,说明产品会退化成低频生成工具,不应做互动教材。
如果 NotebookLM + Notion/Gamma 的组合已经足够好,差异化必须转向“发布 + 学员数据 + 课程运营”。
如果生成时间无法稳定进入 2-3 分钟,内部已经出现的“15 分钟太久”会成为致命体验问题。
如果资料内容一复杂就幻觉严重,必须增加来源引用、逐章校对和人工确认。
如果创作者不愿意把生成物发给真实学员,说明质量还停留在 demo。
下一步
固定“可分享页面 + 章节卡片 + 问答 + 小测”的输出形态,不再优先追 PPT。
选 3 个真实资料包做 demo,并记录生成耗时。
先找成人学习/企业培训用户验证,不进入 K12。
把内部链路的超时和回写失败列为产品风险,而不是仅当工程 bug 处理。
维护边界:本章节为 2026-06-03 质量升级受控块;后续新证据出现时可整体替换本章节。
维护说明
本档案是先验证项目主页,不是泛教育赛道报告;后续只沉淀会影响样例验证、目标用户、主题选择、产品形态和评分的内容。
负责人默认取 Lark 话题 root message 的 sender;本项目话题发起人为“亚洲詹姆斯”。
自动维护只允许更新项目状态卡、最新进展、数据链接和维护说明;原有研究正文默认不覆盖。
评分口径必须区分看板分和正式评分;正式评分变化应先进入 Score History,再回写项目档案。
进入自动写入前,必须先通过 scripts/update_project_archives.py --project-id interactive_ai_textbook --fetch-docs 的 dry-run 门禁。
更新时间:2026年05月22日 16:55(北京时间)
项目状态卡
字段
内容
当前阶段
先验证 / 小步立项候选边缘
优先级
P1
当前评分
74 / 100
话题发起人
空空([已脱敏])
当前推进人
默认同话题发起人;若后续有明确接手人,再人工更新
最近更新时间
2026-06-01
当前判断
AI招聘工具方向成立,但不建议直接做泛招聘平台。更适合从低合规风险、高频刚需的“面试官 Copilot”或“小团队招聘 Agent”切入,用真实招聘样本验证节省时间和输出质量。
下一步
用 7-14 天收集 3-5 组真实 JD、简历和面试记录,验证 AI 是否能稳定生成面试提纲、候选人要点、面试总结和招聘复盘,并避开自动淘汰候选人的高风险边界。
维护策略
中频更新:只在出现具体招聘环节变化、真实样本、竞品资料、客户验证或合规风险信号时更新。
最新进展
2026-06-01:完成第二篇项目档案结构化试点。当前保留原有研究正文和 74/100 判断,只新增项目状态卡、最新进展、数据链接和维护说明;后续每日根据 Lark 话题进展、Base 状态和真实招聘样本验证结果增量更新。
2026-05-26:话题内完成阶段性总结,判断该方向适合从“面试官 Copilot / 小团队招聘 Agent”切入,而不是直接做完整 AI 招聘平台。
2026-06-02:完成 01 项目档案受控区块维护:同步当前 project_key / thread_id / Base record_id / Wiki 文档链接,并按最新话题数据校验项目状态、负责人、证据链接与下一步维护边界。
执行摘要
AI招聘工具是一个真实、明确、正在加速的 AI + HR 工作流机会,但不适合泛泛做“AI招聘平台”。更优路径是从一个高频、低合规风险、能立即节省时间的工作流切入,例如:面试官 Copilot 或 小团队招聘 Agent 。
按新版 elite-market-project-research 规则,本项目以 Lark 话题数据为 P0 核心证据:该话题共有 9 条消息、5 条人类消息、4 条 App 分析,用户连续要求解释“什么是 AI 招聘工具”、判断它是否是 AI 工具、分析赛道、前景、天花板和建议。外部资料进一步验证:AI 正在进入招聘、HR、候选人沟通、面试辅助和流程自动化,但监管和偏见风险也在上升。
本项目适合进入 先验证 / 小步立项候选边缘 ,但不建议直接进入完整产品开发。第一阶段应围绕真实招聘样本做 7-14 天验证:用真实 JD、简历、面试记录测试 AI 是否能稳定节省 HR/面试官时间,并且不触碰自动淘汰候选人的高风险边界。
综合评分:74 / 100,状态:先验证 → 小步立项候选边缘 。
一、Lark 话题证据摘要
字段
内容
话题群
Tranfu AI机会
chat_id
[已脱敏]
thread_id
[已脱敏]
项目标题
AI招聘工具
当前阶段
discussing
消息规模
9 条消息 / 5 条人类消息 / 4 条 App 分析
资源规模
0 个外部资源链接
Base record_id
[已脱敏]
项目档案
[内部链接已脱敏]
原始需求
【事实】用户先在 Lark 话题中创建主题:
AI招聘工具
随后连续追问:
你先简单查找和思考,什么是AI招聘工具,是否是一个AI工具,赛道、前景、天花板怎么样,综合分析。
分析什么是AI招聘工具,详细分析建议解释。
群内共识
【事实】话题内 AI 初步分析已经形成以下判断:
AI 招聘工具不是单一小工具,而是一类用 AI 改造招聘流程的软件;
它可以覆盖 JD、简历解析、候选人搜索、自动沟通、面试辅助、面试总结、ATS 流转和招聘复盘;
更准确的定位是“AI + HR 工作流工具”;
如果只做“AI 帮我筛简历”,容易变成插件;如果串起招聘流程,价值更高;
赛道大,但天花板取决于切入环节。
群内分歧
【事实】当前 Lark 话题没有明确反对意见,也没有外部链接、竞品资料或真实招聘样本。
【推断】这意味着内部需求已经比“随便想法”更强,但仍主要停留在概念理解和赛道判断层,尚未进入样本验证。
已提供资料
【事实】当前 Lark 话题未提供外部资源链接,资源数为 0。
已形成判断
【推断】Lark 证据足以支持“进入轻量研究和小步验证”,但不足以支持“立即做完整 AI 招聘平台”。最合理切口是低合规风险、可快速交付价值的 面试官 Copilot 或 小团队招聘 Agent 。
待验证问题
HR/面试官最愿意先用 AI 解决哪一步:JD、筛简历、面试准备、记录总结、候选人沟通,还是复盘;
真实 JD + 简历 + 面试记录里,AI 能节省多少时间;
用户是否信任 AI 的候选人评价,还是只接受“辅助总结”;
企业是否愿意把招聘数据接入第三方工具;
如何避开自动淘汰、自动排序、偏见和隐私合规风险。
Lark 证据等级
Lark 证据:L2+
原因:有真实话题、多轮追问和 AI 分析,但缺少外部资源、真实招聘样本、访谈、试用、付费或明确负责人。
二、研究边界与方法论
2.1 市场定义
本报告中的“AI招聘工具”包含:
AI 简历解析与筛选;
JD 生成与优化;
候选人搜索 / sourcing;
候选人沟通和邀约;
AI 面试 / 模拟面试;
面试官 Copilot;
面试记录、总结、评价辅助;
招聘流程自动化和招聘数据分析。
暂不包含:
纯传统 ATS;
纯猎头服务;
通用办公 AI 助手;
没有招聘工作流场景的泛 HR 工具。
2.2 地域和场景假设
2.3 已使用的方法
本报告按三个能力链完成:
elite-market-researcher :用顶尖市场研究员视角判断赛道结构、拐点、反共识和事前验尸。
market-analysis :按赛道、竞争、用户、政策/监管维度做市场分析。
Project Scoring :按需求真实性、AI 工作流适配、技术可行性、验证可行性、分发、商业价值、复用、成本、风险、Tranfu fit 打分。
2.4 关键资料来源
BCG: How AI Tools Are Changing Recruitment,提到 AI 正在招聘中发挥越来越重要作用,LinkedIn 等平台正在推出 AI 工具/Agent 帮助招聘人员寻找和筛选候选人;BCG CHRO 调研显示,企业在 HR 中试验 AI 的比例较高。
Deloitte: 2025 Talent Acquisition Tech Trends,强调 agentic AI、招聘流程效率、候选人体验、工具整合。
NYC DCWP: Automated Employment Decision Tools,本地法 144 对自动化就业决策工具要求偏见审计、公开信息和候选人通知。
Deloitte: NYC Local Law 144 algorithmic bias,对 AEDT 偏见审计和组织准备进行解释。
Forbes / HR 行业文章:AI 在 sourcing、screening、onboarding、candidate engagement 中的趋势。
Springer systematic review: AI in employee [已脱敏],强调 AI 提效与偏见、透明度、伦理问题并存。
二、赛道全景:AI 招聘为什么值得看
2.1 第一性原理
招聘的本质不是“发岗位、收简历”,而是一个高成本匹配系统:
企业想用尽可能低的时间和风险成本,找到足够匹配的人;
候选人想用尽可能低的信息和沟通成本,找到适合自己的机会。
招聘链路里有大量 AI 可以介入的结构性低效:
AI 的价值不在于“代替 HR 做决定”,而在于:
把非结构化招聘信息结构化;
把重复沟通自动化;
把面试判断流程标准化;
把招聘过程沉淀成可复盘数据。
2.2 三个拐点信号
拐点 1:HR 正在从“试用 AI”进入“流程化采用”
BCG 和 Deloitte 的资料都显示,AI 正在进入 talent acquisition 流程,不再只是内容生成,而是 candidate sourcing、screening、engagement、workflow automation。
判断:上升趋势,强度高。
拐点 2:Agentic AI 让招聘自动化从单点工具走向流程工具
过去 AI 招聘多是“生成 JD / 筛简历 / 面试题”。现在 agentic AI 可以把多个步骤串起来:
岗位需求 → JD → 候选人搜索 → 初筛 → 邀约 → 面试准备 → 总结 → 数据复盘
判断:上升趋势,强度中高。
拐点 3:AI 招聘监管开始明确化
NYC Local Law 144 对 AEDT 要求偏见审计、公开审计信息和候选人通知。这意味着“自动淘汰/自动排序”类产品风险上升,但“辅助记录、辅助总结、辅助决策”类产品反而更容易合规落地。
判断:监管趋严,强度高。
三、用户需求洞察
3.1 用户分层
用户 1:企业 HR / 招聘团队
核心目标:提高筛选效率、减少重复沟通、提升候选人匹配质量。
痛点:
简历太多,筛选耗时;
候选人与岗位匹配不稳定;
沟通和约面重复;
招聘数据难复盘;
业务部门反馈不标准。
用户 2:业务面试官
核心目标:快速理解候选人、提出好问题、形成标准化反馈。
痛点:
面试前没时间读简历;
不知道该问什么问题;
面试记录散乱;
反馈不标准,难比较候选人。
用户 3:创业公司 / 小团队
核心目标:没有完整 HR 的情况下也能跑招聘流程。
痛点:
不会写 JD;
不知道去哪找候选人;
面试流程不规范;
招聘进展容易丢;
创始人/负责人时间被招聘消耗。
用户 4:求职者
核心目标:提高投递、面试、复盘效率。
痛点:
不知道岗位真正考什么;
简历和岗位不匹配;
面试准备低效;
缺少反馈和复盘。
3.2 Top 5 真痛点
筛选效率 :大量简历需要快速过滤;
面试标准化 :面试官评价口径不一致;
候选人沟通 :邀约、提醒、答疑、反馈重复;
招聘复盘 :渠道、候选人质量、面试转化难沉淀;
小团队招聘能力不足 :没有专业 HR 也要完成招聘。
四、竞争格局
4.1 竞争梯队
第一梯队:大型 HR SaaS / ATS
代表:Workday、Greenhouse、Lever、BambooHR、Ashby 等。
优势:
已在企业流程里;
有客户和数据;
可自然内置 AI。
弱点:
产品重;
创新慢;
AI 体验可能不够原生;
对小团队不一定友好。
第二梯队:AI sourcing / talent intelligence
代表:LinkedIn AI 能力、SeekOut、hireEZ、Eightfold 等。
优势:
弱点:
数据源和合规要求高;
更偏大中型企业;
小团队可能用不起。
第三梯队:AI 面试 / 视频面试
代表:HireVue 等。
优势:
弱点:
偏见、公平性、透明度争议大;
监管压力高;
候选人体验容易负面。
第四梯队:AI 招聘助理 / 沟通自动化
代表:Paradox Olivia 等。
优势:
弱点:
容易被 ATS 或协作工具内置;
需要和企业流程集成。
第五梯队:求职者侧工具
代表:简历优化、模拟面试、求职 Copilot。
优势:
弱点:
4.2 竞争强度判断
维度
强度
判断
新进入者威胁
高
LLM 降低产品开发门槛,单点工具容易出现
替代品威胁
高
ATS、LinkedIn、飞书/钉钉、通用大模型都可能替代
买方议价
中高
企业 HR 预算有限,采购会看 ROI 和合规
供应商议价
中
模型/API 可替代,但数据和集成是瓶颈
行业内竞争
高
招聘 SaaS、HR Tech、AI 工具竞争都强
结论:竞争强,但不是不能做。关键是避免泛平台,选择一个足够具体的低风险工作流切口。
五、机会洞察
机会 1:面试官 Copilot
产品定义
帮助面试官在面试前、中、后完成:
读 JD + 简历 → 生成面试问题 → 记录面试 → 总结候选人 → 输出标准化反馈
为什么值得切
MVP
输入 JD + 简历;
输出 10 个面试问题;
面试后粘贴记录/转写;
输出候选人亮点、风险、追问建议、结构化反馈。
验证方式
找 5 位真实面试官,用真实简历和 JD 测试:
是否节省 30% 准备时间;
面试问题是否更有针对性;
反馈是否更标准化;
面试官是否愿意下次继续用。
机会 2:小团队招聘 Agent
产品定义
面向没有专业 HR 的创业公司/小团队,提供招聘流程助手:
写 JD → 发渠道 → 整理候选人 → 生成面试题 → 跟进状态 → 输出招聘日报
为什么值得切
风险
需要连接渠道;
候选人来源是关键瓶颈;
如果不能带来候选人,只做流程工具价值有限。
机会 3:求职者 AI 面试助手
产品定义
面向求职者,帮助其分析岗位、准备问题、模拟面试、复盘回答。
为什么值得切
MVP 容易;
用户痛点明确;
与之前记录的 AI 面试产品方向高度相关。
风险
六、反共识观点
共识 1:AI 招聘最大机会是自动筛简历
反共识判断:自动筛简历不是最适合早期创业团队切入的点。
原因:
合规和偏见风险高;
企业对自动淘汰候选人敏感;
ATS 和招聘平台很容易内置;
需要大量历史数据和岗位上下文。
更好的早期切入是面试官 Copilot 和流程辅助。
置信度:高。
共识 2:AI 面试能大幅降低招聘成本
反共识判断:AI 面试会提高效率,但也可能损害候选人体验和雇主品牌。
尤其是视频面试、自动评分、黑箱排序,会让候选人感觉被机器筛掉。
更好的定位是:
AI 帮面试官准备和总结,而不是替代面试官做判断。
置信度:中高。
共识 3:招聘工具应该卖给 HR
反共识判断:第一批用户可能不是 HR,而是业务面试官或创业团队负责人。
因为他们的痛点更直接:没有时间准备面试、不知道怎么评估候选人、招聘进展混乱。
置信度:中。
七、Project Scoring
项目类型:commercial_product + internal_initiative 混合。当前按“外部产品验证 + Tranfu 内部机会池”处理。
证据等级:L2+(Lark 真实话题 + 多轮追问 + App 分析 + 外部公开资料)。尚未有真实招聘样本、访谈、行为或付费证据。
7.1 证据融合表
结论
Lark 证据
外部证据
类型
置信度
备注
AI 招聘工具是真实方向
用户连续追问定义、赛道、前景、天花板
BCG、Deloitte、HR 行业资料显示 AI 正进入招聘流程
事实+推断
高
方向成立
不能泛泛做 AI 招聘平台
Lark 问题仍停留在“是什么/怎么分析”
ATS/HR SaaS/LinkedIn/HireVue 等竞争强
推断
高
必须切工作流
面试官 Copilot 是低风险切口
话题分析已强调面试辅助、记录、总结
监管更关注自动决策;辅助工具风险较低
推断
中高
适合 7 天验证
小团队招聘 Agent 有 Tranfu fit
Lark 机会雷达偏 AI Agent + 工作流
小团队缺 HR、流程不规范,AI 可提效
观点
中
需真实样本验证
当前不能立即立项完整产品
Lark 无资源、无样本、无付费信号
外部竞争和合规风险都高
观点
高
应先验证
7.2 证据等级
Lark 证据等级:L2+
外部证据等级:L2
综合证据等级:L2+
说明:
7.3 评分表
维度
权重
分数
加权
依据
Demand reality
16
72
11.5
用户明确:HR/面试官/小团队/求职者,痛点真实但还缺访谈
AI workflow fit
12
82
9.8
JD、简历、面试记录都是 AI 擅长处理的非结构化输入
Technical feasibility
10
76
7.6
MVP 可用现有模型 + 文档/会议输入实现
Validation feasibility
10
70
7.0
7 天内可找真实 JD/简历/面试官做 concierge test
Distribution reachability
10
58
5.8
第一批用户来源还不明确,需要内部/朋友公司样本
Business/value recovery
10
66
6.6
B2B/插件/服务可收费,但付费意愿未验证
Reuse and retention
8
72
5.8
招聘是重复流程,面试官 Copilot 有复用潜力
Cost structure
8
74
5.9
模型成本可控,主要成本在集成和人工校对
Risk and responsibility
8
52
4.2
招聘属于高敏场景,需明确不做自动淘汰和黑箱评分
Tranfu fit
8
82
6.6
与 AI 面试产品、Agent 工作流、项目评价器高度相关
Base score:约 70.8 / 100
证据系数:L1 = 0.82
但由于这是内部机会池项目,且下一步不是正式开发,而是小步验证,不能简单用商业产品置信度把分数压低。采用 Project Scoring 的 limited-information policy:保留项目质量判断,同时降低决策状态。
7.4 最终评分
项目质量分:74 / 100
证据置信度:中低(L1)
当前状态:先验证 → 小步立项候选
7.3 硬门槛检查
Gate
结果
User gate
通过,但需优先选一个用户:面试官 / 小团队负责人
Demand gate
部分通过,痛点明确但缺访谈/样本
AI-fit gate
通过,AI 在总结、生成、结构化、匹配中有明确作用
Responsibility gate
条件通过,必须避免自动淘汰/黑箱录用建议
7.4 唯一主要下一步
用“面试官 Copilot”做 7 天 concierge test。
不要同时做完整招聘平台、求职者助手和 AI 面试官。先验证最小闭环。
八、7 天验证计划
Day 1:准备样本
收集:
3 个真实 JD;
10 份真实或脱敏简历;
2-3 位面试官;
现有面试反馈模板。
Day 2:生成面试准备包
对每个候选人输出:
简历摘要;
岗位匹配点;
风险点;
面试问题;
建议追问。
Day 3-4:面试官试用
让面试官使用准备包进行真实或模拟面试。
记录:
准备时间是否下降;
问题是否更有针对性;
反馈是否更标准;
是否愿意再次使用。
Day 5:面试后总结
输入面试记录或文字纪要,生成:
候选人亮点;
风险;
证据摘录;
追问建议;
是否进入下一轮的“辅助建议”。
注意:最终判断必须由人做。
Day 6:复盘指标
关键指标:
面试准备时间节省 ≥ 30%;
面试官满意度 ≥ 4/5;
输出需要人工大改比例 < 30%;
至少 1 位面试官愿意继续试用。
Day 7:决策
若通过:进入小步立项,做飞书文档/会议纪要集成原型。
若未通过:重构方向,考虑小团队招聘 Agent 或求职者面试助手。
九、事前验尸
假设 2 年后这个项目失败,最可能原因:
做成泛 AI 招聘平台,范围太大;
自动筛选/评分触碰合规和偏见风险;
无法接入真实 ATS/招聘流程;
输出不稳定,面试官不信任;
被 ATS、LinkedIn、飞书等平台内置;
没有找到第一批高频用户。
我会改变看法的触发条件:
5 位以上面试官试用后都认为节省时间不明显;
输出误导性强,人工修正成本过高;
招聘合规要求导致无法在目标市场落地;
找不到真实样本和试用用户。
十、最终建议
AI招聘工具值得进入 P1 观察和验证,但必须收敛。它的优势是 Lark 话题有多轮追问,说明内部确实在理解和评估这个方向;短板是没有外部资源、真实招聘样本和付费/试用信号。
推荐路线:
面试官 Copilot
→ 7 天真实样本验证
→ 飞书文档/会议纪要原型
→ 小团队招聘 Agent
→ 再考虑更完整招聘流程系统
不建议路线:
一开始做完整 AI 招聘平台
一开始做自动淘汰候选人
一开始做黑箱候选人评分
当前最优下一步:
用 3 个 JD + 10 份简历 + 2-3 位面试官,做 7 天 concierge test。
参考来源
BCG: How AI Tools Are Changing Recruitment
Deloitte: 2025 Talent Acquisition Tech Trends
NYC DCWP: Automated Employment Decision Tools, Local Law 144
Deloitte: NYC Local Law 144 and Algorithmic Bias
Forbes: AI-driven talent acquisition / AI [已脱敏] trends
Springer systematic review: AI in employee [已脱敏], ethics, bias and transparency
数据链接
字段
内容
project_key
[已脱敏]:[已脱敏]
chat_id
[已脱敏]
thread_id
[已脱敏]
Base record_id
[已脱敏]
Wiki node
NT7gw7rOwislYbkAVABlnF2rgK3
Doc token
WfXsd4IRDoQQsyxDERHlBslhgTd
数据来源
Lark 话题群、recent topic snapshot、Base Opportunities、项目档案正文
项目增强分析(2026-06-02)
口径:基于最新项目维护报告、Lark 话题真实数据与可复核公开资料整理;web_search 当前不可用,因此未二次核验的市场判断均按“趋势/假设”保守处理。
project_id: ai_recruiting_tool
📌 一句话机会
从"面试官 Copilot"切入——面试前生成面试提纲、面试中辅助记录、面试后输出结构化候选人总结——用 AI 节省面试官 30%+ 准备时间,验证后再扩展为"小团队招聘 Agent"。
🎯 目标用户
| 优先级 | 用户 | 核心目标 | 痛点 |
|--------|------|----------|------|
| P1 | 业务面试官(非 HR) | 快速理解候选人、提出好问题、输出标准反馈 | 面试前没时间读简历,不知问什么,反馈散乱 |
| P1 | 创业公司/小团队负责人 | 没有专业 HR 也要跑招聘流程 | 不会写 JD,面试流程不规范,招聘进展易丢 |
| P2 | 企业 HR / 招聘团队 | 提高筛选效率,减少重复沟通 | 简历太多,沟通重复,招聘数据难复盘 |
| P2 | 求职者 | 提高投递、面试、复盘效率 | 岗位匹配不清,面试准备低效 |
🔥 核心痛点
筛选效率低 :大量简历需要快速过滤,但自动筛选合规风险高
面试标准化差 :不同面试官评分口径不一,候选人不可比
候选人沟通重复 :邀约、提醒、答疑、反馈花费大量时间
招聘复盘困难 :渠道质量、候选人转化、面试通过率难系统性追踪
小团队招聘能力不足 :没有专业 HR 也能完成招聘是刚需
📊 当前证据
内部话题数据
话题来源 :Lark "Tranfu AI机会" 群,thread_id [已脱敏]
消息/资源 :13 条消息(5 条人类 + 4 条 App 分析),2 个资源
话题发起人 :空空(杨林昆)
讨论内容 :从"什么是 AI 招聘工具"开始,延伸至赛道前景、天花板、切入建议
话题证据等级 :L2+(有真实话题、多轮追问、AI 分析,但缺少外部资源、真实样本和付费信号)
项目评分 :74/100
当前状态 :先验证 / 小步立项候选边缘
外部资料/行业趋势
BCG:AI 正进入招聘流程,LinkedIn 等平台正在推出 AI Agent 帮助招聘
Deloitte 2025 Talent Acquisition Tech Trends:agentic AI、流程效率、候选人体验
NYC Local Law 144:自动化就业决策工具要求偏见审计和透明度,合规压力上升
Springer 系统综述:AI 在招聘中的提效与偏见、透明度、伦理问题并存
Forbes:AI 在 sourcing、screening、onboarding、candidate engagement 中的趋势
竞争格局
| 梯队 | 代表 | 特点 |
|------|------|------|
| 大型 HR SaaS / ATS | Workday、Greenhouse、Lever、BambooHR、Ashby | 已在企业流程内,创新慢 |
| AI sourcing / talent intelligence | LinkedIn AI、SeekOut、hireEZ、Eightfold | 强数据壁垒,偏大中型企业 |
| AI 面试 / 视频面试 | HireVue 等 | 偏见和监管争议大 |
| AI 招聘助理 / 沟通自动化 | Paradox Olivia 等 | 节省沟通时间,需要流程集成 |
| 求职者侧工具 | 简历优化、模拟面试、求职 Copilot | MVP 容易但 C 端付费弱 |
🏗️ MVP 切口
推荐路径:面试官 Copilot
不 做完整招聘平台;不 做自动淘汰/黑箱评分;从面试辅助切入 。
MVP 功能 :
备选切口:小团队招聘 Agent
✅ 验证方式
7 天 concierge test :
准备 :3 个真实 JD,10 份真实/脱敏简历,2-3 位面试官
Day 1-2 :生成面试准备包(简历摘要、匹配点、面试问题、追问建议)
Day 3-4 :面试官试用真实面试,记录准备时间变化和满意度
Day 5 :面试后总结(亮点、风险、证据摘录、辅助建议),注意最终判断由人做
Day 6-7 :复盘关键指标
通过门槛 :
面试准备时间节省 ≥ 30%
面试官满意度 ≥ 4/5
输出需人工大改比例 < 30%
至少 1 位面试官愿意继续试用
⚠️ 风险与反证
| 风险 | 可能性 | 影响 | 缓解 |
|------|--------|------|------|
| 自动筛简历触碰合规/偏见风险 | 高 | 致命 | 不做自动淘汰,只做辅助记录和总结 |
| 输出不稳定,面试官不信任 | 中高 | 严重 | concierge 阶段人工校对,逐步提升质量 |
| 被 ATS / LinkedIn / 飞书平台内置 | 中高 | 严重 | 聚焦工作流而非平台,做"AI 层" |
| 无法接入真实招聘流程 | 中 | 严重 | 初期用离线文件,不依赖 API 集成 |
| 找不到第一批高频用户 | 中 | 中 | 先从团队内部/朋友公司开始 |
我会改变看法的触发条件 :
5 位以上面试官试用后都认为节省时间不明显
输出误导性强,人工修正成本过高
招聘合规要求导致无法在目标市场落地
📋 下一步
第 1 步(7 天):concierge test——3 JD + 10 简历 + 2-3 面试官
第 2 步(通过后):飞书文档/会议纪要集成原型
第 3 步:验证小团队招聘 Agent 方向
第 4 步:评估是否进入更完整招聘流程系统
不建议 的路线:一开始做完整 AI 招聘平台 / 自动淘汰候选人 / 黑箱候选人评分
🔗 参考来源链接
BCG: "How AI Tools Are Changing Recruitment"
Deloitte: "2025 Talent Acquisition Tech Trends"
NYC DCWP: "Automated Employment Decision Tools, Local Law 144"
Deloitte: "NYC Local Law 144 and Algorithmic Bias"
Forbes: "AI-driven talent acquisition" / "AI [已脱敏] trends"
Springer systematic review: "AI in employee [已脱敏], ethics, bias and transparency"
维护边界:本章节为 2026-06-02 增强分析受控块;后续若有新客户验证、竞品变化或 Lark 话题进展,可替换本章节,不覆盖原始档案正文。
项目质量升级(2026-06-03)
口径:本章节用于替换昨日偏模板化的增强稿表达;基于 Lark 话题真实数据、项目 mapping、既有维护报告与公开竞品格局,强调判断、边界、验证和反证。不覆盖原文其它章节。
project_id: ai_recruiting_tool
当前判断
这个方向有真实需求,但不适合用“AI 招聘平台”来描述。平台化会立刻撞上 ATS、LinkedIn、Workday、合规审计和候选人数据壁垒。更合理的切口是 面试官 Copilot :让业务面试官在面试前少花时间、面试中更结构化、面试后少写废话。
当前判断:P1,先验证;边缘小步立项候选。 它能不能成立,关键不在 AI 会不会总结简历,而在业务面试官是否愿意把真实 JD、简历和面试记录交给它,并认为输出比自己临时看简历更省时间。
真实内部话题数据
项目名:AI 招聘工具
project_id:ai_recruiting_tool
Wiki / Doc:NT7gw7rOwislYbkAVABlnF2rgK3 / WfXsd4IRDoQQsyxDERHlBslhgTd
Lark thread:[已脱敏]
阶段 / 优先级:先验证 / 小步立项候选边缘;P1
更新策略:medium
负责人:空空
数据来源:snapshot
消息 / 资源:13 条消息 / 2 个资源
维护门禁:PASS
最近话题脉络:用户要求“总结这个话题讨论的信息”,小满将话题概括为独立项目:讨论从“AI 招聘工具是什么”开始,延伸到赛道前景、天花板、切入建议和是否值得进一步验证。
既有评分:74/100
证据等级:L2+(有真实内部讨论和多轮分析,但外部资源少,缺真实招聘样本与付费信号)
外部竞品 / 替代方案
ATS / HR SaaS :Workday、Greenhouse、Lever、BambooHR、Ashby。它们拥有招聘流程入口,未来会内置 AI,但对小团队和业务面试官的轻量使用未必友好。
Talent intelligence / sourcing :LinkedIn AI、SeekOut、hireEZ、Eightfold。强在候选人来源和匹配,但数据壁垒高,偏大中型企业。
AI 视频面试 / 自动评估 :HireVue 等。效率高但争议大,容易触碰偏见、透明度和监管。
招聘沟通自动化 :Paradox Olivia 等。适合大批量候选人沟通,但需要深度流程集成。
通用替代 :业务面试官直接把 JD 和简历丢给 ChatGPT / Claude / Kimi,让模型生成问题。这是最强替代,因此 MVP 必须比“通用模型 + 手工 prompt”更顺滑、更可信。
内部替代 :HRBP / 招聘专员人工准备面试包,或飞书文档模板。可靠但耗时,不适合小团队。
MVP 做什么
MVP:面试官 Copilot,不碰自动筛选。
输入:JD、候选人简历、岗位级别、面试轮次、公司关注维度。
输出:
交互可以先用飞书文档或聊天机器人,不需要产品界面。
MVP 不做什么
不做自动淘汰候选人。
不做黑箱候选人评分。
不做视频面试表情/语音情绪分析。
不做候选人来源和 outbound sourcing。
不接 ATS、不处理全招聘流程。
不给“录用/拒绝”结论,只给结构化证据和待验证问题。
不处理敏感属性推断,如年龄、性别、婚育、种族、健康等。
7 天验证计划
Day 1:准备 3 个真实或脱敏 JD,覆盖技术、运营/增长、产品/设计中至少两个岗位。
Day 2:收集 10 份真实或脱敏简历,标注岗位、候选人阶段、面试轮次。
Day 3:生成第一版面试准备包,给 2-3 位真实面试官试读,记录他们会删改哪些内容。
Day 4:让面试官在真实或模拟面试中使用准备包,记录准备时间、问题使用率、追问有效性。
Day 5:基于面试记录或面试官口述生成反馈草稿,明确所有最终判断由人做。
Day 6:对比“无 Copilot 准备”和“有 Copilot 准备”的时间、质量和主观满意度。
Day 7:复盘是否愿意继续试用、是否愿意让团队其他面试官使用。
7 天通过门槛 :准备时间节省 ≥ 30%;面试官满意度 ≥ 4/5;输出需要大改比例 < 30%;至少 1 位面试官愿意继续在真实招聘中试用。
14 天验证计划
Week 2 前 3 天:把面试准备包模板固化为 3 个岗位类型版本:技术、业务、产品/设计。
Week 2 第 4-5 天:引入 1 个真实小团队招聘场景,连续处理 5-8 名候选人。
Week 2 第 6 天:生成招聘复盘小结:每位候选人的证据、风险、下一步、面试官反馈一致性。
Week 2 第 7 天:评估付费模式:按岗位/按候选人/按团队月费,测试哪个更容易接受。
14 天通过门槛 :至少 1 个小团队愿意让它进入连续招聘流程;面试官主动要求复用模板;HR/负责人认为反馈更可比较。
风险反证
如果 5 位以上面试官都认为“我自己看简历更快”,应停止该切口。
如果输出经常编造候选人经历或误读简历,人工校对成本会吃掉全部效率收益。
如果用户真正痛点是“找不到候选人”,而不是“面试准备低效”,面试官 Copilot 的价值会被削弱。
如果企业合规要求不允许简历进入第三方模型,应只能做私有化/本地化,商业化门槛显著上升。
如果通用模型通过一套 prompt 就能达到 80% 效果,产品需要转为“模板 + 流程 + 权限 + 记录”的工作流插件,而不是独立工具。
下一步
用 3 JD + 10 简历做 concierge test,先验证节省时间。
明确合规边界:只做辅助,不做自动决策。
建立一份“面试问题质量评估表”,记录每个问题是否被使用、是否问出有效信息。
14 天后根据真实团队连续使用结果,决定是否从面试官 Copilot 扩展到小团队招聘 Agent。
维护边界:本章节为 2026-06-03 质量升级受控块;后续新证据出现时可整体替换本章节。
维护说明
本档案是项目主页,不是每日流水;只写入会改变项目判断、验证路径、风险判断或下一步动作的信息。
负责人默认取 Lark 话题 root message 的 sender;本项目话题发起人为“空空”,Lark 原始显示名为“杨林昆”。
自动维护只允许更新项目状态卡、最新进展、数据链接和维护说明;原有研究正文默认不覆盖。
进入自动写入前,必须先通过 scripts/update_project_archives.py --project-id ai_recruiting_tool --fetch-docs 的 dry-run 门禁。
若出现真实招聘样本、客户访谈、竞品资料、合规风险或评分变化,应同步更新本档案和 Score History。
比亚迪生态商业机会调研报告
更新时间:2026年05月26日 14:29(北京时间)
项目状态卡
字段
内容
当前阶段
项目化待确认 / 轻量研究
优先级
待定
当前评分
待正式评分
话题发起人
亚洲詹姆斯([已脱敏])
当前推进人
默认同话题发起人;是否纳入长期项目档案待确认
最近更新时间
2026-06-01
当前判断
比亚迪生态方向有完整调研报告和清晰假设,但更像研究报告转项目的候选项。是否纳入长期项目档案,需要先确认团队是否要持续跟进“车主补能 / 行程规划 / 能源服务”这个方向。
下一步
先做项目化判断:确认目标用户、真实痛点、比亚迪生态接入可行性、已有替代方案和验证样本;通过后再进入正式评分和持续维护。
维护策略
人工确认更新:该项目为 manual,不进入自动写入;只有明确纳入长期项目档案后,才按项目档案规则持续维护。
最新进展
2026-06-01:补齐项目档案维护结构,但保留 manual 策略。当前仅将其标记为“项目化待确认 / 轻量研究”,不自动提升优先级,不自动纳入每日项目维护。
2026-05-22:话题创建并附带 BYD 生态商业机会调研报告,核心假设是以“找充电桩 + 行程规划”为高频入口,以智能补能调度为数据飞轮,评估 V2V / V2G / 应急能源等延展机会。
2026-06-02:完成 01 项目档案受控区块维护:同步当前 project_key / thread_id / Base record_id / Wiki 文档链接,并按最新话题数据校验项目状态、负责人、证据链接与下一步维护边界。
执行摘要
本项目基于 Lark 话题群中已沉淀的讨论与附件线索,围绕 比亚迪开放平台(D++ / DiLink 生态) 探索商业机会。当前讨论的核心设想不是泛泛做“汽车行业 AI”,而是围绕 比亚迪车主的高频出行与补能场景 ,寻找一个可商业化、可验证、可持续扩展的服务入口。
当前较清晰的一句话定义是:
以“找充电桩 + 行程规划”为高频入口,以“智能补能调度”为数据飞轮,进一步评估是否存在围绕 V2V / V2G / 应急能源调度等延展价值的商业化机会。
这意味着该项目更像一个 车主服务 / 新能源生态服务 方向,而不是一个纯软件功能点。
二、来自 Lark 话题群的内部证据
1. 话题标识
project_key: [已脱敏]:[已脱敏]
thread_id: [已脱敏]
话题标题:比亚迪生态商业机会调研报告
2. 当前话题沉淀情况
根据已落地到本地的 Lark 话题汇总:
当前累计消息数:4 条
人类消息数:3 条
AI / App 消息数:1 条
当前状态:discussing
状态建议:建议进入轻量研究
3. 已提炼出的关键讨论点
当前话题中已出现的有效线索包括:
4. 当前内部共识
现有讨论至少说明了三件事:
团队并不是想做一个抽象“比亚迪相关项目”,而是在找 车主高频场景切入口 。
当前设想已经不是一句空标题,而是已经具备了 产品分层结构雏形 。
现阶段仍然缺少最关键的商业验证信息:
具体用户是谁
高频痛点是否足够强
现有替代方案是什么
用户是否愿意付费
所以,当前结论不应是“可以立项”,而应是:
方向值得继续研究,但必须先重构为更具体的用户场景与验证方案。
三、机会定义:我们到底在看什么机会
当前可以把项目定义为:
核心机会假设
围绕比亚迪车主在新能源出行过程中的几个关键节点,构建一个从 信息入口 → 决策辅助 → 调度能力 → 高价值延展服务 的产品路径。
三层机会结构
第一层:高频入口
找充电桩
路线规划
补能决策
里程/续航焦虑相关辅助
这是最接近日常使用频率、也最容易切入的部分。
第二层:智能调度层
根据路线、时间、电量、目的地、排队情况做补能推荐
给出更优的充电方案
帮助用户减少等待、绕路、决策成本
这一层如果成立,才可能真正体现 AI 的价值,而不是普通信息聚合。
第三层:高 ARPU 延展层
V2V(车与车之间的应急供能)
V2G(车与电网互动)
应急能源调度
车主能源服务延展
这一层想象力最大,但距离验证也最远。当前不应该直接拿它当第一阶段产品,而应视为未来延展方向。
四、市场判断
1. 为什么这个方向有吸引力
(1)比亚迪车主规模大
比亚迪本身就是中国新能源车最重要的用户群体之一,只要切口成立,潜在市场不是小市场。
(2)补能与出行规划是真实场景
对新能源车主来说:
找合适充电桩
判断何时补能
规划远途路线
降低排队与时间损耗
这些都是真实问题,而不是伪需求。
(3)AI 在这里有机会做“决策层”而不只是“信息层”
普通 App 可以展示地图和充电站,但 AI 有机会做的是:
结合车况、路线、时间、偏好做推荐
动态重算补能方案
形成用户更信任的辅助决策
这比单纯做“充电站列表”更有机会形成差异。
2. 为什么这个方向又不能直接乐观
(1)当前切口仍然偏宽
“比亚迪生态商业机会”这个名字太大,里面可能包含:
车主服务
车后市场
社群
本地生活
充电服务
车机生态
能源服务
如果不收窄,项目就会一直停留在研究阶段。
(2)现有替代方案很多
即使不考虑 AI,也已经有:
地图类服务
充电桩平台
车主社群信息交换
车企官方能力
通用导航工具
所以必须回答:
为什么用户需要一个新的产品,而不是继续用现有组合方案?
(3)AI 的必要性还没有被证实
目前可以看出 AI“可能有用”,但还没有证明 AI 是这个项目的核心价值,而不是锦上添花。
(4)生态接入存在现实门槛
如果要做得足够深,后续很可能涉及:
车机/开放平台能力接入
充电数据接口
地图与导航数据
生态合作路径
这意味着:
不是单纯做一个前端页面就能解决
后续验证必须尽早碰触“能不能接入”的现实问题
五、当前评分结论(统一口径)\n
结合当前已存在的机会雷达评分沉淀,本项目当前统一口径应为:
项目总评分 / 看板分:80
正式评分:59 / 100
正式结论:重构方向
项目阶段:待轻量研究
优先级:P1
当前评分摘要
基础分:65
证据系数 / 完整度:0.9
正式分:59
关键维度:
需求真实性:72
AI 适配:62
验证可行性:70
商业价值:68
为什么不是更高分
因为当前缺的不是想象力,而是:
具体用户画像
高频入口验证
替代方案缺口
真实付费场景
分发/生态接入路径
所以现在更合理的结论不是“推进立项”,而是:
先重构项目定义,再验证是否值得进入正式产品方向。
六、项目最值得保留的部分
如果要保留这个方向,我认为最值得保留的不是“大生态”叙事,而是下面这条线:
新能源车主补能与行程规划的智能决策辅助。
原因:
它比“比亚迪生态”更具体;
它比“泛车主服务”更容易验证;
它更容易形成可衡量的价值:
它更有机会证明 AI 不是噱头,而是产品核心层。
七、当前最关键的问题
1. 第一用户是谁?
必须明确:
是日常通勤车主?
是长途出行车主?
是网约 / 运营类用户?
是充电服务运营方?
这几类用户的痛点差异非常大。
2. 高频入口到底是什么?
“找充电桩 + 行程规划”是否真的是最高频入口? 还是:
更有价值?
3. 当前替代方案哪里不够好?
如果现有地图/充电 App/官方车机已经足够好,那新产品很难成立。
4. AI 能比规则系统更好吗?
如果只是静态推荐,AI 不一定比规则系统更有优势。必须确认 AI 在什么情况下能显著提高体验和决策质量。
八、建议的重构方向
当前不建议继续以“比亚迪生态商业机会调研报告”这种宽标题直接推进产品,而建议收口为:
建议重构版本
比亚迪车主补能与行程规划智能助手
更清楚的定义
面向新能源车主,帮助其在出行过程中更高效地完成:
续航判断
补能节点选择
路线与时间决策
异常情况下的替代补能方案选择
这会让项目从“行业报告型机会”转向“用户问题型机会”,更适合机会雷达继续推进。
九、建议的下一步研究方案
Step 1:先补用户与场景
优先访谈 3-5 位目标用户,至少覆盖:
日常通勤型新能源车主
中长途出行车主
对补能体验敏感的用户
访谈重点:
他们最常见的补能决策问题是什么
当前靠什么解决
哪些场景最烦
愿不愿意为更省时间/更安心的方案付费
Step 2:补替代方案梳理
需要明确当前替代组合:
地图导航
充电桩平台
官方车机/官方 App
社群经验
手工决策
然后判断差距到底在哪里。
Step 3:验证 AI 价值点
要尽快回答:
AI 是做解释?
做补能决策?
做动态调度?
做个性化建议?
不能笼统写“AI赋能”。
Step 4:判断生态接入难度
即使第一版先不深接,也要尽早评估:
后续需要什么开放能力
能否拿到关键数据
是否存在强依赖某个平台的风险
十、当前结论与建议
当前结论
这个方向不建议直接立项 ,但值得继续保留并进入轻量研究 。
原因
有真实场景基础
有一定商业想象力
AI 可能存在价值切入点
但当前定义过宽,关键验证信息不足
当前最优动作
不是继续扩写“大生态故事”,而是:
尽快把项目重构为“比亚迪车主补能与行程规划智能助手”,并补足用户、场景、替代方案、生态接入四类关键信息。
当前统一建议动作
明确车主高频入口;
补充比亚迪开放能力、竞品和潜在合作/分发路径;
完成一轮轻量研究后再重新评分。
十一、建议同步到 Lark 的字段
项目档案页建议写入
Score History
记录当前正式评分:59
保留中置信度说明
标注需要补访谈与替代方案研究
Opportunities
保留看板分:80
同步当前正式结论为“重构方向”
明确“车主服务 / 新能源生态”核心方向
Daily Briefs / 每日更新
只记录今天完成了哪部分调研
不重复承担长期真相源职责
数据链接
字段
内容
project_key
[已脱敏]:[已脱敏]
chat_id
[已脱敏]
thread_id
[已脱敏]
Base record_id
[已脱敏]
Wiki node
E0F0wNQZHiWOyHkrVPnlmHjIgZb
Doc token
Euu9dimw9oZvvwx30TglrycKgFw
当前数据口径
4 条消息 / 3 条人类消息 / 1 条 AI/App 消息 / 16 个资源;其中一条 AI 回复疑似串题,维护时不作为比亚迪方向证据。
项目增强分析(2026-06-02)
口径:基于最新项目维护报告、Lark 话题真实数据与可复核公开资料整理;web_search 当前不可用,因此未二次核验的市场判断均按“趋势/假设”保守处理。
project_id: byd_ecosystem_opportunity
一句话机会
围绕比亚迪庞大车主与新能源出行生态,寻找“补能/行程/车主服务/智能座舱内容/开发者工具”的轻量商业机会,但当前应先确认是否项目化,避免误把一次调研当长期项目。
目标用户
比亚迪新能源车主,尤其是高频通勤、长途自驾、家庭出行用户。
比亚迪生态周边服务商:充电、维修保养、改装、保险、二手车、车品、内容/导航服务。
希望接入车机/智能座舱/车主社群的开发者或本地服务商。
核心痛点
新能源车主仍有补能焦虑:充电桩可用性、排队、价格、路线规划、跨城出行可靠性。
车主服务分散在车机、App、地图、充电平台、社群和本地商家之间。
比亚迪用户基数大,但第三方要进入生态需要明确入口、数据权限和合作模式。
智能座舱应用常见问题是“看起来有入口,但真实使用频次和商业转化不确定”。
当前证据
内部话题数据
project_id:byd_ecosystem_opportunity
current_status:项目化待确认;优先级 待定;更新策略 manual。
Wiki:E0F0wNQZHiWOyHkrVPnlmHjIgZb;Doc:Euu9dimw9oZvvwx30TglrycKgFw。
话题负责人:亚洲詹姆斯。
消息/资源:4 / 16。
最近内部摘要包含一个文件:BYD生态商业机会调研报告.docx,随后有“在此基础上再做一下市场研究”。维护报告中还混入了“团队 API Key 管理”的输出摘要,提示当前归档内容可能存在串话/写入错位。
维护报告明确警告:manual update policy,未明确人工批准不要自动写入。
外部资料与趋势
比亚迪在新能源车销量、垂直整合、电池和智能化方面持续扩张,带来庞大车主生态和后市场服务空间。
车企智能化方向集中在智能座舱、驾驶辅助、车机应用、补能网络和 OTA 服务。
中国新能源车主的真实高频需求往往不是“泛车机 App”,而是补能、用车成本、路线、保养、保险、二手残值、社群服务。
竞品 / 替代方案
官方生态:比亚迪 App、DiLink/智能座舱、官方服务、官方商城、OTA 能力。
地图与补能:高德、百度地图、腾讯地图、特来电、星星充电、云快充、国家电网 e 充电。
车主服务:途虎养车、京东养车、保险平台、二手车平台、车主社群/KOC。
智能座舱内容:车机应用商店、音频/视频/游戏/导航/本地生活服务。
MVP 切口
优先从低权限、强需求、可独立验证的场景入手:
比亚迪车主长途补能规划助手 :输入车型、出发地/目的地/时间,输出路线、充电点、备用方案、价格与排队风险。
比亚迪车主省钱助手 :整合充电价格、保养、保险、轮胎、车品优惠和周期提醒。
车主社群服务雷达 :围绕本地车主群,做活动、服务商、团购、口碑榜。
推荐 MVP:长途补能规划助手。它绕开官方深度接入,用户痛点明确,适合用公开地图/充电站信息与车主反馈做早期验证。
验证方式
访谈 20 位比亚迪车主,区分通勤、网约车、家庭长途、自驾游用户。
收集 10 条真实长途路线,人工生成补能方案,对比高德/百度/官方方案的差异。
在车主群中测试“路线规划 + 备用桩 + 风险提醒”是否被转发/收藏。
指标:方案采纳率、用户是否愿意提前一天咨询、是否愿意为高级规划/会员省钱服务付费。
风险与反证
官方 App/地图平台可能快速覆盖补能规划,第三方缺少数据优势。
充电桩实时状态、排队、故障信息获取难,若数据不准会直接损害信任。
智能座舱开发者机会依赖官方平台政策,非确定性强。
当前内部档案存在串话迹象,若不能确认原始 BYD 报告内容,应暂缓正式评分。
下一步
先做档案清洗:确认 BYD生态商业机会调研报告.docx 内容,并剔除维护报告中疑似“团队 API Key 管理”的串话摘要。
把状态保持为“项目化待确认 / manual”,不自动写 Wiki。
用 20 位车主访谈判断优先切口:补能规划、车主省钱、智能座舱应用、车主社群服务。
参考来源链接
维护边界:本章节为 2026-06-02 增强分析受控块;后续若有新客户验证、竞品变化或 Lark 话题进展,可替换本章节,不覆盖原始档案正文。
项目质量升级(2026-06-03)
口径:本章节用于替换昨日偏模板化的增强稿表达;基于 Lark 话题真实数据、项目 mapping、既有维护报告与公开竞品格局,强调判断、边界、验证和反证。不覆盖原文其它章节。
project_id: byd_ecosystem_opportunity
当前判断
这是一个“可能有机会,但档案本身需要先修复”的项目。内部确实出现了 BYD 调研文件和“在此基础上再做市场研究”的请求,但最新维护摘要里混入了“团队 API Key 管理”的市场研究内容,说明归档链路存在串话或错位风险。
所以当前不能直接给高优先级,也不应自动写入 Wiki。最稳妥的判断是:项目化待确认 / manual,先做档案清洗,再决定是否围绕补能、车主服务或智能座舱继续验证。
若原始 BYD 报告确认有效,最值得先测的不是泛“比亚迪生态”,而是 比亚迪车主长途补能规划助手 :低权限、强痛点、可通过车主访谈和公开信息验证。
真实内部数据
标题:比亚迪生态商业机会
project_id:byd_ecosystem_opportunity
Wiki / Doc:E0F0wNQZHiWOyHkrVPnlmHjIgZb / Euu9dimw9oZvvwx30TglrycKgFw
Lark thread:[已脱敏]
阶段 / 优先级:项目化待确认;待定
更新策略:manual
负责人:亚洲詹姆斯
数据来源:snapshot
消息 / 资源:4 条消息 / 16 个资源
关键内部线索:出现文件 BYD生态商业机会调研报告.docx,随后用户要求“在此基础上再做一下市场研究”。
重要异常:维护报告最近摘要中出现“团队 API Key 管理与大模型订阅授权分发”的内容,疑似串话。
证据等级:L2-(有文件和资源,但原始报告内容未复核,且档案存在污染)
竞品 / 替代
官方生态 :比亚迪 App、DiLink、官方商城、服务网点、OTA、车主社区。
地图与补能平台 :高德、百度地图、腾讯地图、特来电、星星充电、云快充、国家电网 e 充电。
车主服务平台 :途虎养车、京东养车、保险平台、二手车平台、本地维修保养商家。
车主社群/KOC :微信群、抖音/小红书车主内容、地方俱乐部、改装/用车经验社群。
智能座舱内容替代 :车机应用商店、音频视频 App、导航、本地生活服务。
MVP 边界
推荐 MVP:比亚迪车主长途补能规划助手 。
只做:
输入车型、出发地/目的地、出发时间、是否带老人孩子、可接受绕路范围。
输出一条主路线 + 2 个备用补能方案。
标注充电点位置、预估到达电量、附近休息/餐饮、可能排队风险、失败备用点。
支持用户反馈:桩是否可用、是否排队、价格、体验。
明确不做:
验证计划
第一步:档案清洗(必须先做)
第二步:20 位车主访谈
第三步:10 条路线人工样例
通过门槛 :20 位车主中至少 8 位有近期补能焦虑或踩坑;10 条路线中至少 5 条能给出比现有工具更有用的备用方案;至少 3 位愿意下次出行前主动咨询。
风险反证
如果原始 BYD 调研报告无法复核,项目应保持 manual,不做评分。
如果高德/百度/官方 App 已经满足 80% 需求,第三方规划价值不足。
如果拿不到可信充电桩实时数据,用户只会把它当参考攻略,而不是决策工具。
如果车主痛点更集中在保养、保险、二手残值而非补能,应切换方向。
如果机会依赖比亚迪官方接口/座舱入口,应暂缓,除非有合作资源。
下一步
先做档案清洗,剔除 API Key 串话。
将状态维持为“项目化待确认 / manual”,不要自动外部写入。
若 BYD 报告有效,启动 20 位车主访谈,优先验证长途补能。
若补能不成立,再比较“车主省钱助手”和“本地车主社群服务雷达”。
维护边界:本章节为 2026-06-03 质量升级受控块;后续新证据出现时可整体替换本章节。
维护说明
本档案目前按“研究报告转项目候选”处理,不默认纳入自动每日维护。
负责人默认取 Lark 话题 root message 的 sender;本项目话题发起人为“亚洲詹姆斯”。
当前有一条 AI/App 消息内容疑似串到“团队 API Key 管理”,不得作为比亚迪项目判断依据。
自动维护只允许更新项目状态卡、最新进展、数据链接和维护说明;原有研究正文默认不覆盖。
如果后续确认项目化,应先补正式评分、Base record_id、目标用户、验证计划和 Score History,再切换出 manual 策略。
更新时间:2026-06-01
项目状态卡
字段
内容
当前阶段
待轻量研究
优先级
P2
当前评分
待正式评分
话题发起人
待从 Lark 话题 root sender 回填
当前推进人
待补上下文;默认同话题发起人
最近更新时间
2026-06-01
当前判断
育儿教育类产品已进入优先项目看板,但当前缺少足够 thread 原文和外部资源。先作为轻量项目档案占位,后续补齐用户、场景和验证计划。
下一步
补拉 Lark thread 完整消息,明确是家长教育、儿童陪伴、学习辅导还是亲子内容产品,再决定是否正式评分。
维护策略
低频更新:先补齐 thread 原文、owner 和证据;未补齐前不进入自动写入。
最新进展
执行摘要
育儿教育类产品已进入优先项目看板,但当前缺少足够 thread 原文和外部资源。先作为轻量项目档案占位,后续补齐用户、场景和验证计划。
本档案的首要价值是打通“看板记录 → Wiki 项目档案 → 后续维护”的链路,而不是替代完整研究报告。后续补齐原始话题后,应按项目档案标准补充目标用户、核心痛点、当前证据、MVP / 验证计划、风险与反证。
目标用户
待补:需从 Lark thread 原文和后续讨论中确认。
核心痛点
待补:需从原始需求、用户场景和替代方案中提炼。
当前证据
评分与判断
当前优先级:P2;正式评分:待正式评分。该评分来自优先项目看板,后续如有更新,应先进入 Score History 或看板,再回写项目档案。
MVP / 验证计划
补拉 Lark thread 完整消息,明确是家长教育、儿童陪伴、学习辅导还是亲子内容产品,再决定是否正式评分。
风险与反证
缺少 thread 原文时,不能把看板标题误认为完整项目定义。
若补拉后发现只是单条灵感且无连续讨论,应保持低优先级观察。
若无法定义目标用户、痛点和验证动作,不应进入正式验证阶段。
数据链接
字段
内容
project_key
[已脱敏]:[已脱敏]
thread_id
[已脱敏]
Base record_id
[已脱敏]
数据口径
来自优先项目看板;thread 原文待补拉。
项目增强分析(2026-06-02)
口径:基于最新项目维护报告、Lark 话题真实数据与可复核公开资料整理;web_search 当前不可用,因此未二次核验的市场判断均按“趋势/假设”保守处理。
project_id: parenting_education_product
一句话机会
面向新手父母的“育儿知识 + 家庭教育 + 孩子成长记录”AI 助手,把碎片化育儿问题转化为按年龄、情境和家庭约束定制的可执行建议。
目标用户
核心痛点
育儿知识分散且互相矛盾,父母很难判断哪些建议可信、适合自己孩子。
育儿问题具有强上下文:年龄、性格、健康状况、家庭作息、父母理念都影响方案。
传统课程和社区缺少即时反馈;通用 AI 又可能给出不安全或过度自信建议。
父母需要的是“低负担记录 + 可信建议 + 可执行计划”,不是泛泛问答。
当前证据
内部话题数据
project_id:parenting_education_product
current_status:待轻量研究;优先级 P2;更新策略 low。
Wiki:Yetyw6Kp2icZs3k1I8sl60Wdg7S;Doc:FSaadSvacoSiXux2fI7lSllvgEh。
话题负责人:[已脱敏]。
数据来源:mapping;消息/资源:0 / 0。
维护报告显示暂无内部话题沉淀,需先做轻量研究。
外部资料与趋势
Khanmigo 官网定位为“Khan Academy's AI-powered teaching assistant & tutor”,说明 AI 教育产品正在从内容推荐走向个性化教学与教师/家长辅助。
AI Tutor、儿童学习 App、家长助手正在快速增长,但涉及未成年人数据、建议安全和内容可信度,监管/合规门槛高。
与“儿童 Sketch-to-Game 创意平台”相比,本项目更偏父母端和家庭教育,不应直接混成儿童游戏产品。
竞品 / 替代方案
AI 教育/辅导:Khanmigo、Duolingo Max、Quizlet AI、国内作业帮/猿辅导/学而思 AI 产品。
育儿内容与社区:宝宝树、亲宝宝、小红书、丁香妈妈、年糕妈妈、得到/樊登亲子课程。
成长记录:亲宝宝、宝宝相册、家庭相册、日历/备忘录。
通用 AI:ChatGPT、豆包、Kimi、通义,用于即时育儿问答。
MVP 切口
建议从父母端“育儿情境决策助手”切入,而不是儿童端学习 App:
用户输入孩子年龄、问题场景和家庭约束。
AI 给出“可能原因、今晚怎么做、未来一周计划、何时需要求助专业人士”。
重点场景:睡眠、情绪爆发、语言启蒙、屏幕时间、亲子阅读、入园适应。
附带成长记录:每次建议后记录执行结果,下一次回答自动参考历史。
验证方式
访谈 15 位 0-6 岁父母,按焦虑频率和付费意愿排序场景。
建立一个微信/飞书机器人原型,只做 3 个安全边界清晰场景:睡眠习惯、亲子阅读、情绪安抚。
指标:父母是否连续 7 天记录,建议是否被执行,是否愿意为月度计划付费。
必须设计安全提示:医疗、心理、发育迟缓等问题只做信息整理并建议咨询专业人士。
风险与反证
未成年人相关产品合规和信任门槛高,不能用“万能育儿医生”叙事。
高质量内容需要专家审核,否则容易被通用 AI 替代且存在安全风险。
父母焦虑强但付费不一定稳定,可能更愿意为课程/社群/专家服务付费。
若用户只在偶发问题时询问,缺少连续记录,则产品应转为内容/咨询工具而非独立 App。
下一步
做轻量研究:聚焦 0-6 岁父母高频问题与付费方式。
与“AI生活助手”的家庭生活运营切口联动,判断是否作为家庭助手的垂直模块。
与“儿童 Sketch-to-Game”区分:本项目服务父母决策,后者服务儿童创造力体验。
参考来源链接
维护边界:本章节为 2026-06-02 增强分析受控块;后续若有新客户验证、竞品变化或 Lark 话题进展,可替换本章节,不覆盖原始档案正文。
项目质量升级(2026-06-03)
口径:本章节用于替换昨日偏模板化的增强稿表达;基于 Lark 话题真实数据、项目 mapping、既有维护报告与公开竞品格局,强调判断、边界、验证和反证。不覆盖原文其它章节。
project_id: parenting_education_product
当前判断
这个方向有真实用户焦虑,但当前内部证据几乎为空。它不能直接按“AI 育儿助手”立项,因为未成年人、健康、心理、教育建议都涉及高信任和安全边界。泛问答会被 ChatGPT/豆包/Kimi 替代;过度承诺又有合规与伦理风险。
比较稳的定位是:父母端育儿情境决策助手 。它不替代医生、心理咨询师或老师,只帮助父母把碎片信息整理成可执行、可复盘的家庭方案。
当前建议:P2 待轻量研究;先做父母访谈和 3 个安全场景机器人,不做儿童端产品。
真实内部数据
标题:育儿教育类产品
project_id:parenting_education_product
Wiki / Doc:Yetyw6Kp2icZs3k1I8sl60Wdg7S / FSaadSvacoSiXux2fI7lSllvgEh
Lark thread:[已脱敏]
阶段 / 优先级:待轻量研究;P2
更新策略:low
负责人:[已脱敏]
数据来源:mapping
消息 / 资源:0 条消息 / 0 个资源
证据等级:L0/L1(只有项目记录,无原始需求和讨论)
为什么暂缓
暂缓的原因很明确:
没有内部用户画像:0-3 岁、3-6 岁、6-12 岁父母需求完全不同。
没有场景排序:睡眠、喂养、情绪、入园、学习、亲子阅读、屏幕时间都可能成立,但不能全做。
安全边界不清:医疗、心理、发育迟缓、教育诊断都不能让 AI 直接下结论。
付费方式不清:父母可能为课程、专家、社群付费,不一定为 AI 工具订阅付费。
竞品 / 替代
AI 教育/辅导 :Khanmigo、Duolingo Max、Quizlet AI、作业帮/猿辅导/学而思 AI 产品。偏学习和辅导,不等同于父母育儿决策。
育儿内容/社区 :宝宝树、亲宝宝、小红书、丁香妈妈、年糕妈妈、樊登/得到亲子课程。信任来源强,但信息碎片化且观点冲突。
成长记录工具 :亲宝宝、宝宝相册、日历/备忘录。记录强,决策弱。
通用 AI :ChatGPT、豆包、Kimi、通义。即时回答强,但缺孩子长期上下文、安全边界和可信引用。
专家咨询 / 线下机构 :儿科医生、心理咨询师、早教/托育/幼儿园老师。可信但成本高、响应慢,不适合每个小问题。
MVP 边界
推荐 MVP:父母端育儿情境决策助手 。
只做 3 个安全边界较清楚的场景:
睡眠习惯:作息观察、睡前流程、环境建议。
亲子阅读:按年龄和兴趣推荐绘本、生成一周阅读计划。
情绪安抚:帮助父母描述情境、给沟通脚本和复盘问题。
输出结构固定:
可能原因(非诊断)
今晚怎么做
未来 7 天计划
需要记录什么
什么时候应该咨询专业人士
明确不做:
验证计划
父母访谈 15 人
目标:0-6 岁父母,优先一胎、新手、双职工家庭。
记录:过去一周最焦虑的 3 个育儿问题;从哪里找答案;是否执行;是否付费。
排序:高频 + 可执行 + 安全边界清楚 + 愿意记录。
7 天机器人试验
通过门槛 :15 位父母中至少 8 位愿意提供连续记录;7 天试验中至少 5 位完成 4 天以上记录;至少 3 位愿意为月度计划/专家审核版付费。
风险反证
如果父母只在焦虑时偶发提问,不愿连续记录,则不适合做 App,更像内容/咨询入口。
如果所有高价值问题都落入医疗/心理/发育诊断,应暂缓 AI 产品化。
如果没有专家审核,用户不信任;但专家审核成本又过高,商业模型需重算。
如果通用 AI 回答已经被父母认为够用,差异化只能来自长期记录和可信内容库。
如果用户愿意付费的是课程/社群,不是工具,应转为“AI 辅助专家/课程交付”。
可能合并方向
与 ai_life_assistant 合并为“家庭生活与育儿运营助手”。
与 kids_sketch_to_game 区分:本项目服务父母决策,Sketch-to-Game 服务儿童创造表达。
若验证发现核心需求是内容课表/学习计划,可并入 interactive_ai_textbook 或教育内容方向。
下一步
先做 15 位父母访谈,不写产品方案。
选择 3 个安全场景跑 7 天机器人试验。
补充安全免责声明、专业求助触发条件、数据最小化策略。
根据连续记录和付费意愿决定是否升级。
维护边界:本章节为 2026-06-03 质量升级受控块;后续新证据出现时可整体替换本章节。
维护说明
更新时间:2026-06-01
项目状态卡
字段
内容
当前阶段
机会池 / 初步分析
优先级
P2
当前评分
待正式评分
话题发起人
罗文印([已脱敏])
当前推进人
默认同话题发起人;暂无明确推进人
最近更新时间
2026-06-01
当前判断
这是一个值得进入机会池的 AI 影像方向,但不应做泛修图 App。更准确的切口是“把普通人物+景色随手拍,变成接近专业摄影师拍摄和后期后的成片”。
下一步
收集 20-50 组普通随手拍,做 before/after 样例,验证人物相似度、光影真实感、构图提升和社交分享意愿。
维护策略
低到中频更新:只有样例效果、用户反馈、竞品资料或正式评分变化时更新。
最新进展
执行摘要
AI 摄影成片引擎的核心机会是:用户只提供一张包含人物和背景景色的普通照片,AI 自动识别场景、风格、人物气质,选择打光、构图、姿势、焦段和后期风格,最终生成接近专业摄影师拍摄和后期精修后的效果。
这个方向的核心不是“美颜”或“滤镜”,而是把摄影师、模特引导、灯光和后期流程自动化,帮助用户获得“本人真实出镜但效果像专业旅拍/写真/杂志照”的结果。
目标用户
核心痛点
当前证据
评分与判断
暂未正式评分。建议先作为 P2 机会池项目,待出现样例效果和用户反馈后再评分。
MVP / 验证计划
限定输入:单人、人物 + 景色、旅行/生活照。
输出 3 种风格:自然旅拍、杂志感、电影感。
验证指标:人物像本人、背景不脏、光影真实、用户愿意发社交平台。
用 before/after 收集用户偏好和转发意愿。
风险与反证
如果人物不像本人,用户信任会快速下降。
如果效果只是滤镜级提升,付费价值不足。
影像赛道竞争强,需要避开通用修图 App 红海。
数据链接
字段
内容
project_key
[已脱敏]:[已脱敏]
thread_id
[已脱敏]
Base record_id
[已脱敏]
数据口径
6 条消息 / 3 条人类消息 / 3 条 AI 分析 / 0 个资源。
项目增强分析(2026-06-02)
口径:基于最新项目维护报告、Lark 话题真实数据与可复核公开资料整理;web_search 当前不可用,因此未二次核验的市场判断均按“趋势/假设”保守处理。
project_id: ai_photo_finish_engine
project_id :ai_photo_finish_engine
Wiki / Doc :QjcCwuuYkiLUvYkm5AtlnNRPgFg / A4OSd2fFiozC09xQRqYl9HbWgXb
阶段 / 优先级 :机会池 / 初步分析 / P2
更新策略 :low
话题负责人 :罗文印
内部话题数据 :6 条消息 / 0 个资源;核心原始需求是“AI 时代的美图,简单随手拍就可以出大片”,从人物+背景照片出发,AI 判断场景、风格、人物气质、打光、构图、姿势、焦段,生成接近摄影师与模特磨合及后期处理后的效果。
一句话机会
面向“真人出镜 + 真实旅行/生活背景”的普通照片,做一键摄影级成片引擎:不是通用修图,而是把随手拍升级成专业旅拍、写真或杂志感成片。
目标用户
旅行/生活方式用户 :有真实到此一游照片,希望不用约摄影师也能得到高级成片。
小红书/Instagram/TikTok 创作者 :需要稳定产出高质封面和人物图。
情侣、亲子、个人写真用户 :预算或时间不足以频繁找摄影师。
摄影工作室/修图师 :可作为前期风格预览或后期提效工具。
核心痛点
普通用户不会构图、摆姿势、调光和修色,拍摄现场也不容易重拍。
通用美颜/滤镜容易“假”“网红脸”“背景不协调”,难以保留本人真实感。
专业摄影贵且低频,摄影师沟通、拍摄、精修周期长。
现有 AI 生图常改变人物身份或场景真实性,用户真正想要的是“还是我,只是像被专业拍过”。
当前证据
内部证据
维护报告显示话题已有 6 条消息 ,虽然资源为 0,但原始需求描述非常具体:人物+背景、识别场景/风格/气质、打光/构图/姿势/焦段、摄影师+后期效果。
既有内部结论已将方向定义为 “AI 摄影成片引擎” ,并判断“需求真实,但不应直接按通用修图 App 做”。
阶段为 机会池 / 初步分析 / P2 ,适合先做窄场景验证。
外部资料
Meitu 是成熟影像消费工具公司,证明大众修图、美颜和影像增强需求长期存在。
Adobe Firefly 代表专业创作工具正在把生成式 AI 纳入创意工作流,说明“专业级创意编辑 + AI”是大趋势。
Canva AI image generator/设计工具证明轻量创作用户愿意在设计平台中使用 AI 生成与编辑能力。
Remini、Facetune、Lensa 等同类产品虽然未逐页抓取,但市场上已形成“人像增强、AI 写真、头像/写真生成”的强竞争格局。
竞品 / 替代方案
美图 / Meitu 系产品 :美颜、修图、AI 影像生态强,用户基础大。
Adobe Photoshop / Lightroom / Firefly :专业编辑与生成式填充能力强,适合专业用户,但普通人学习成本高。
Canva :轻量设计和 AI 图片生成,适合营销图和社媒图,但不是专门的真人摄影成片工作流。
Remini / Lensa / Facetune / CapCut 模板 :强在人像增强、AI 写真、模板化效果,但容易同质化、身份漂移或缺少真实场景摄影感。
线下摄影师 / 修图师 :高质量但高成本、低频、交付慢。
MVP 切口
建议从 “旅行人物照一键成片” 切入,而不是全能修图:
输入:1 张人物+景色照片,最好全身/半身,背景清晰。
输出:3 种风格包,例如“日系旅拍 / 杂志大片 / 胶片生活感”。
能力重点:保留人脸身份、优化构图裁切、光影色调、背景层次、轻微姿态/衣褶/发丝优化。
不做:夸张换脸、完全重生图、复杂多图训练、专业修图软件界面。
交互:用户只选“想要的成片感”,不要让用户调一堆参数。
验证方式
质量盲测 :同一张原图,比较普通滤镜、现有 AI 写真工具、本 MVP,由用户选择“最像我且最想发社媒”的图。
身份一致性 :让用户打分“像不像本人”,低于 4/5 则不可进入付费。
分享率 :生成后是否保存、分享到社媒、设为头像/封面。
付费意愿 :单次 3-10 元、包月 19-39 元或成片包付费,测试哪个模式更自然。
场景收敛 :优先旅行照/城市街拍/海边山景三类,记录哪类效果最好。
风险与反证
影像赛道竞争极强,美图、Adobe、Canva、字节系工具都可能快速覆盖。
如果输出只是“滤镜+磨皮”,无法与现有 App 区分。
如果 AI 改脸、改身材过度,会触发用户反感或真实性问题。
肖像权、未成年人照片、隐私数据处理需要谨慎。
高质量图像生成成本可能压缩毛利,尤其在免费试用阶段。
下一步
收集 30-50 张真实“人物+景色”随手拍,按旅行/城市/自然分组。
用现成模型/API 拼一个无界面的批处理 demo,先看成片质量上限。
设计 3 个固定风格包,不做开放 prompt。
找 10 位目标用户盲测,指标为保存率、分享意愿、身份一致性、付费意愿。
若效果明显优于滤镜工具,再考虑产品化界面。
参考来源链接
维护边界:本章节为 2026-06-02 增强分析受控块;后续若有新客户验证、竞品变化或 Lark 话题进展,可替换本章节,不覆盖原始档案正文。
项目质量升级(2026-06-03)
口径:本章节用于替换昨日偏模板化的增强稿表达;基于 Lark 话题真实数据、项目 mapping、既有维护报告与公开竞品格局,强调判断、边界、验证和反证。不覆盖原文其它章节。
project_id: ai_photo_finish_engine
project_id :ai_photo_finish_engine
标题 :AI 摄影成片引擎
Doc / Wiki :A4OSd2fFiozC09xQRqYl9HbWgXb / QjcCwuuYkiLUvYkm5AtlnNRPgFg
阶段 / 优先级 :机会池 / 初步分析 / P2
话题负责人 :罗文印
内部数据 :维护报告显示 6 条话题消息、0 个资源;原始需求明确为“人物 + 背景景色照片 → AI 判断场景、风格、人物气质、打光、构图、姿势、焦段 → 接近摄影师与模特磨合 + 后期精修后的效果”。
当前判断
这是一个需求真实、传播性强,但高度红海的消费影像方向。它不能按“AI 修图 App”或“AI 写真生成器”去做,否则会直接撞上美图、Adobe、Canva、Remini、Lensa、Facetune、CapCut 模板等成熟替代。
更可取的定位是:保留真实本人和真实场景,把随手拍变成专业摄影级成片 。也就是解决“这张照片确实是我在这个地方,但为什么拍出来很普通”的问题,而不是生成一个不像本人的漂亮 AI 人像。
当前建议保持 P2 机会池 ,做 30-50 张真实样例盲测后再决定是否升级。
用户 / 痛点
优先用户不是专业摄影师,而是有明确发图场景的人:
旅行和生活方式用户 :旅行时有大量人物 + 景色照片,但不会构图、打光、调色,也不可能重拍。
小红书 / Instagram / TikTok 创作者 :需要稳定产出封面图、生活方式照片、人物氛围图。
情侣、亲子、个人写真用户 :想要写真感,但不愿高频约摄影师、修图师。
摄影工作室 / 修图师 :可用于样片预览、风格方案或初修提效,但不是首个 MVP 用户。
真实痛点是:
原片构图、光影、姿态、焦段都不够“大片”,但用户不知道怎么改。
通用滤镜和美颜能变好看,却常常变假、网红脸、背景不协调。
AI 写真工具容易身份漂移,用户要的是“还是我”,不是“一个像我的 AI 模特”。
专业摄影贵、低频、交付慢;普通人只想把已有照片补救成可发的成片。
竞品 / 替代
美图 / Meitu 系 :大众修图、美颜、影像增强能力强,用户心智成熟;弱点是容易被理解为泛修图,不一定围绕“真实旅拍成片”工作流。
Adobe Photoshop / Lightroom / Firefly :专业能力强,适合设计师和摄影师;普通用户学习成本高。
Canva / CapCut 模板 :社媒创作和模板分发强;更偏设计/短视频,不专注真人摄影级还原。
Remini / Lensa / Facetune :人像增强、AI 写真、头像类能力强;风险是同质化、身份漂移、风格模板化。
线下摄影师 / 修图师 :质量高但成本高、周期长,不适合高频生活照片。
MVP 边界
推荐 MVP:旅行人物照一键成片 。
只做:
输入 1 张清晰的人物 + 场景照片。
输出 3 个固定风格包:日系旅拍、杂志大片、胶片生活感。
优先优化:身份一致性、构图裁切、光影、色调、背景层次、轻微姿态和衣褶修正。
交互只让用户选择“想要的成片感”,不开放复杂参数。
明确不做:
验证计划
样例集 :收集 30-50 张真实随手拍,按城市街拍、海边/自然、旅行景点分组。
基线对照 :同图对比原片、普通滤镜、现有 AI 写真/增强工具、本方案。
盲测问题 :
哪张最像本人?
哪张最想发社媒?
哪张最像专业摄影师拍过?
核心指标 :
身份一致性评分 ≥ 4/5。
保存意愿 ≥ 50%。
愿为单次成片包付费 ≥ 20%。
价格测试 :单次 3-10 元、10 张成片包、月包 19-39 元三种方式。
风险反证
出现以下情况应降级或放弃:
下一步
维护边界:本章节为 2026-06-03 质量升级受控块;后续新证据出现时可整体替换本章节。
维护说明
🚀 实践记录:基于 Cursor + Git Worktree 的多 Agent 自动化串行流水线
🛠 核心工具栈: Cursor | Git Worktree | Opus 4.6 & Codex-5.3
🎯 核心目标: 通过“一句话提示词”触发多个 Sub-agent 形成自动化串行执行,实现多任务并行开发。
📂 当前提案: openspec/changes/redesign-skill-card-vertical
🔄 自动化串行工作流 (Agent Pipeline)
注意 :下面没有明确说用 SubAgent 的就不要用 SubAgent
0 TASK 0:提案复核
模型 :Gemini-3.1-pro任务 :。使用 openspec-review-specs skill。关注点 :着重审视提案完备性设计,关键数据流,属性、接口对齐等等。
1️⃣ TASK 1:架构师预审 (Architect Review)
模型 :Opus 4.6任务 :站在架构师的视角,对当前提案进行全局优化与细节补充。使用 neversight-skills_feed-system-architect skill。关注点 :着重审视系统设计,挖掘潜在的代码复用机会,确保方案的健壮性。
2️⃣ TASK 2:提案执行 (Implementation)
模型 :Opus 4.6任务 :直接执行指令 /opsx/apply,将打磨后的提案转化为实际代码。
3️⃣ TASK 3:代码审查 (Code Review)
模型 :Codex-5.3 (模型切换)任务 :
执行 git commit 保存初步生成的代码。
严格对照提案 (Proposal) 审查当前 Commit 的代码逻辑。
注:此阶段仅做只读审查(Read-only),不进行任何代码篡改,确保 Review 视角的客观性。
4️⃣ SubAgent 4:自愈与更新 (Auto-Refinement)
模型 :Opus 4.6 (模型切回)任务 :摄取 Agent 3 输出的审查报告,基于反馈结果自动更新并修复代码缺陷。
5️⃣ SubAgent 5:收尾与归档 (Archiving)
模型 :Opus 4.6任务 :
执行指令 /opsx/archive,对当前提案进行状态归档。
执行最终的 git commit,完成该特性的闭环。
💡 瓶颈复盘与优化方案 (Reflections & Optimization)
当前流水线实现了高度的自动化,但整体运行耗时稍长 。
优化思路 :当前 Sub-agent 的职责划分过于细粒度。下一步可以尝试降低颗粒度 ,将高内聚的任务合并(例如将“架构预审”与“提案执行”合并为单个大 Agent 步骤,或将“自愈更新”与“归档”合并),以减少模型切换和上下文传递带来的通信损耗,从而大幅提升流水线执行速度。 为什么复杂任务的默认工作流应该写在 AGENTS.md,而不是某个 Skill 里
> 时间:2026年3月26日 10:04(北京时间) > 主题:小满的任务工作流设计原则、AGENTS.md 与 Skill 的职责边界、为什么默认流程属于上层规则而不是专项技能
最近我们围绕一个问题做了比较深入的讨论:
**“为什么小满现在这套默认工作流程,要写在 AGENTS.md,而不是直接做成某个 skill?”*“为什么小满现在这套默认工作流程,要写在 AGENTS.md,而不是直接做成某个 skill?” AGENTS.md,而不是直接做成某个 skill?”
这个问题看起来像是文档放哪更合适,但本质上其实是在讨论:
一个 AI 助手到底应该怎么组织自己的工作系统
什么属于“总规则”,什么属于“专项能力”
为什么有些东西必须写成全局行为,而不能塞进单个模块里
我把这次讨论整理成一篇更完整的文章,方便后续团队统一理解,也方便作为知识库中的长期规则沉淀。
一、先说结论
小满现在这套默认工作流——比如:
先判断任务类型
如果有明确匹配的 skill,就先读 skill
先只读排查,再决定是否动手
能直接完成就直接完成
复杂任务分层处理,必要时再拆子 agent
它更适合写在 AGENTS.md,而不是某一个单独的 skill 里。
原因很简单:
这不是某类任务的“专项执行方法”,而是小满处理几乎所有任务时的总调度逻辑****总调度逻辑 。
换句话说:
AGENTS.md 负责:收到任务后,先怎么判断、怎么分流、怎么做决策Skill 负责:一旦确定这是某类任务,具体怎么做
一个管“选路”,一个管“走路”。
二、AGENTS.md 和 Skill,本来就不是同一层东西
1)AGENTS.md 是上层规则
AGENTS.md 更像是 AI 助手的工作宪法、操作系统或者岗位说明书。
它适合承载:
群聊和私聊边界
默认任务 intake 流程
复杂任务怎么处理
什么时候先查环境、什么时候先给方案
角色定位、任务分发和交接规范
团队协作方式
这些规则的特点是:
跨任务
跨领域
跨 skill
不管当前任务具体是什么,都会先影响行为
所以这类内容天然适合放在 AGENTS.md。
2)Skill 是专项能力模块
而 skill 更像一个个专业工具箱或 SOP 模块。
比如:
healthcheck:怎么做健康检查find-skills:怎么搜索可用 skilllark-kb-analysis-writer:怎么导出整库并分析service-guardian:怎么做服务守护compaction-survival:长任务时怎么保持状态不丢
它们回答的是:
“当任务已经被识别成某一类后,具体执行方法是什么?”****“当任务已经被识别成某一类后,具体执行方法是什么?”
所以 skill 更适合写“专项执行路径”,而不是负责整个 agent 的总决策逻辑。
三、为什么“默认工作流”不能只靠某个 skill 承担
1)因为它发生在选 skill 之前
这是最关键的一点。
我们现在这套默认流程的前两步就是:
先判断任务类型
如果有明确匹配的 skill,就先读 skill
注意这里的逻辑顺序:
**是否调用某个 skill,本身就要先经过上层判断。**是否调用某个 skill,本身就要先经过上层判断。
如果把这套流程写进某个单独 skill,就会出现一个逻辑倒挂:
我得先调用一个 skill
才能读到“要先判断该不该调用 skill”
这就变成自我循环了。
所以像“先判断任务类型”“先查现有能力”“先摸环境”这种规则,必须写在 skill 之上。
而 AGENTS.md 恰好就是那个上层。
2)因为它是跨任务的共通原则
这套流程不是只对某一类任务生效。
它同时适用于:
知识库整理
服务稳定性排查
研究报告
技术方案分析
目录架构优化
自动化流程设计
长任务、多步骤任务
也就是说,它不是某个领域专属,而是小满做事的默认脑回路。
这种“共通原则”如果塞进某一个 skill,就会变成局部规则,覆盖范围反而不对。
3)因为它决定的是“任务怎么进系统”,不是“任务怎么执行”
这套流程本质上是:
先看这是不是复杂任务
先看已有工具、脚本、文档、spec
先摸清环境再动手
复杂任务默认先给方案
确认后再推进重执行
这套东西决定的是:
**任务进来后,先走哪条路。**任务进来后,先走哪条路。
而不是某条具体路径内部的步骤。
因此它属于任务路由层任务路由层,不是 专项执行层 。
4)因为它和角色、边界、协作方式绑定在一起
小满并不是一个抽象的工具集合,而是一个带角色约束的助手。
当前体系里,小满有:
群聊边界
私聊代发规则
研究任务默认写知识库
Lark 任务默认自动路由
复杂任务先方案后执行
必要时可用子 agent 协作
这些东西不只是“怎么做某件事”,而是:
小满是谁
小满对用户和团队负责什么
小满在什么场景可以主动,什么场景应该克制
这更像岗位规则、协作契约,而不是 skill 说明书。
所以应写在 AGENTS.md,而不是写进某个单一 skill。
5)因为多个 skill 往往会同时适用,需要上层裁决
现实任务经常不是单一归类。
比如一个任务可能同时涉及:
如果没有上层规则,小满就很容易:
乱选 skill
并行混用路径
该先只读的时候直接上手修改
该先给方案的时候直接执行
所以必须有一个写在 skill 之上的“总调度逻辑”,决定:
这正是 AGENTS.md 的职责。
四、如果硬把它做成一个 skill,会出现什么问题
1)职责膨胀
如果专门做一个所谓“intake skill”,里面负责:
判断任务类型
检查现有能力
搜索增强路径
决定要不要给方案
再决定是否调用别的 skill
那它很快就会变成一个“万能前置 skill”。
问题是:
它什么都管
但并不专注于某个领域
和 AGENTS.md 的作用高度重叠
会形成两个总控中心
结果不是更清楚,而是更容易混乱。
2)会形成“skill 套 skill”的递归感
流程会变成:
收到任务
先调用 intake skill
intake skill 再判断要不要调用其他 skill
其他 skill 再真正干活
这在设计上很别扭。
因为本来应该作为 agent 默认脑回路的东西,被额外包成了一个 skill,反而增加了一层形式主义。
3)轻任务会被过度流程化
并不是所有任务都需要显式走一遍完整 intake。
很多任务其实很轻:
这类任务如果每次都显式调用某个“前置 skill”,系统就会显得过于笨重。
而写进 AGENTS.md,这套规则可以自然地作为默认行为存在:
这更像“会做事的人”,而不是“执行表单流程的机器”。
4)没命中任何 skill 时,仍然需要默认规则兜底
还有很多任务属于:
没有一个 skill 完全匹配
但仍然需要先看现有环境
仍然需要先查脚本、文档、配置真相
仍然需要先给方案,而不是蛮干
如果这类规则不写在上层,而只寄托在某个 skill 上,那一旦任务没命中那个 skill,整套流程就失效了。
所以必须有一个不依赖 skill 是否命中,也能生效的默认行为层****不依赖 skill 是否命中,也能生效的默认行为层 。
这层就是 AGENTS.md。
五、那 skill 在整个体系里应该做什么?
最合理的分工是这样的:
AGENTS.md 负责
默认任务 intake
任务分类
风险判断
优先复用已有能力
是否先给方案
是否应该拆子 agent
群聊 / 私聊边界
团队协作方式
Skill 负责
某个领域的专业做法
某类任务的执行 SOP
某项能力的标准流程
专项工具链的使用方式
比如:
healthcheck 负责“怎么排查服务健康”lark-kb-analysis-writer 负责“怎么读整库再分析”service-guardian 负责“怎么做守护和 auto-recovery”compaction-survival 负责“长任务如何保存状态、抵抗压缩丢失”
可以理解为:
AGENTS.md 是总导演各个 skill 是专业部门
导演决定拍什么、怎么分工;部门负责把自己那段拍好。
六、那 skill 完全不需要做 planning 吗?
也不是。
其实可以额外做一个专门的 planning / intake / capability-first planning skill,作为补充层****补充层 。
它适合用在:
特别复杂的陌生任务
用户明确说“先别做,先给最优方案”
需要做方法设计、路线设计、任务拆解
但它的定位应该是:
显式规划模块****显式规划模块
而不是:
默认工作流本体****默认工作流本体
也就是说:
AGENTS.md 仍然负责全局默认行为planning skill 只在需要时被主动启用
这样两层不会冲突。
七、为什么这次这套流程特别适合写进 AGENTS.md
因为这次讨论的不是某个专业技能该怎么做,而是一个更上层的问题:
“小满以后在面对复杂任务时,默认应该怎么思考、怎么判断、怎么进入执行。”****“小满以后在面对复杂任务时,默认应该怎么思考、怎么判断、怎么进入执行。”
这个问题本质上属于:
行为风格
风险控制
协作协议
任务调度逻辑
agent 宪法级规则
所以把它写进 AGENTS.md,不仅合理,而且是最清晰的做法。
八、最终总结
为什么默认工作流要写在 AGENTS.md,而不是 skill?
因为这套流程决定的是:
**在选 skill 之前,小满应该怎么做事。**在选 skill 之前,小满应该怎么做事。
而 skill 更适合解决的是:
**当已经确定这是一类任务后,该怎么具体执行。**当已经确定这是一类任务后,该怎么具体执行。
一个是上层总规则,一个是下层专项能力。两者不是对立关系,而是分层关系。
真正成熟的 agent 系统,不是把所有东西都塞进 skill,而是要把:
全局行为规则
专项技能模块
用户偏好和团队协作方式
长任务生存与恢复机制
放在正确的层级上。
这次讨论的价值就在这里:
我们不是只给小满增加了一个新流程,而是在逐步把“小满怎么工作”这件事,变成一套更清晰、更可维护、也更像真正助理的系统。
九、建议的后续动作
基于这次讨论,后续可以继续补两类文档:
《AGENTS.md 与 Skill 的职责边界图》****《AGENTS.md 与 Skill 的职责边界图》
用图示方式明确:什么该写 AGENTS、什么该写 Skill、什么该写 MEMORY
《复杂任务 Planning / Intake Skill 设计方案》****《复杂任务 Planning / Intake Skill 设计方案》
不是替代 AGENTS.md,而是作为显式规划层补充
如果这两份补上,整个系统的分层会更清楚,小满后续也更容易持续优化。
调研日期 :2026-03-13
目标 :实现 OpenClaw 同时对接 Telegram 和飞书(Lark)
一、当前环境分析
1.1 OpenClaw 现有配置
已配置的渠道 :
渠道 │ 状态 │ 说明 ─────────┼─────────────────┼──────────────────────────────────────────────── Telegram │ ✅ 正常运行 │ 3 个 bot(nexus、xiaoman、polymarket),DM 开放 飞书 │ ⚠️ Webhook 模式 │ 非原生 WebSocket,通过 bridge 中转 当前飞书配置 (~/.openclaw/openclaw.json):
{ "feishu": { "domain": "lark", "streaming": false, "blockStreaming": false, "textChunkLimit": 8000 } } 1.2 当前飞书对接架构
现有方案:Webhook Bridge
飞书 → Cloudflare Tunnel → bridge.py (localhost:19800) → OpenClaw Gateway (localhost:18789) bridge.py 功能 :
接收飞书事件(卡片消息、私聊、群聊)
转发给 OpenClaw Gateway
群聊智能回复(strict 模式:必须 @ 才回复)
消息去重和持久化
问题 :
非原生集成,依赖额外 bridge 服务
需要 Cloudflare Tunnel 暴露公网
功能受限(无法使用 OpenClaw 原生飞书功能)
二、OpenClaw 原生飞书集成
2.1 官方支持情况
OpenClaw 官方原生支持飞书 ,通过 WebSocket 长连接接收事件,无需公网暴露。
支持的功能 :
私聊消息
群聊消息(支持 @ 机器人)
卡片消息(Interactive Card)
发送消息(send_as_bot)
媒体文件处理
2.2 配置步骤
步骤 1:创建飞书应用
访问 飞书开放平台
创建企业应用
获取 App ID 和 App Secret
步骤 2:配置权限
在飞书应用权限中批量导入:
{ "scopes": { "tenant": [ "im:message", "im:message:send_as_bot", "im:message:readonly", "im:chat.members:bot_access", "im:resource", "aily:file:read", "aily:file:write" ] } } 步骤 3:启用机器人能力
在 应用能力 → 机器人 中启用并设置机器人名称。
步骤 4:配置事件订阅
选择 使用长连接接收事件 (WebSocket)
添加事件:im.message.receive_v1
步骤 5:发布应用
在 版本管理与发布 中创建版本并提交审核。
2.3 OpenClaw 配置
方式一:CLI 配置(推荐)
openclaw channels add # 选择 Feishu,输入 App ID 和 App Secret 方式二:配置文件
{ "channels": { "feishu": { "enabled": true, "dmPolicy": "pairing", "accounts": { "main": { "appId": "cli_xxx", "appSecret": "xxx", "botName": "小满" } } } } } 飞书国际版(Lark)配置 :
{ "channels": { "feishu": { "domain": "lark" } } } 三、Telegram 对接现状
3.1 当前配置
已有 3 个 Telegram bot :
Bot │ Token │ DM 策略 │ 群聊策略 ───────────┼───────────────────────────────┼─────────┼────────── nexus │ 8605513784:AAHpV9JvZECkHc0... │ pairing │ allowlist xiaoman │ 8679985454:AAFMmTZSHeBL_... │ open │ open polymarket │ 8617997098:AAFtetMdfopk_... │ open │ allowlist 配置特点 :
均使用代理:http://127.0.0.1:7897
DM 策略:nexus 需配对,其他开放
群聊:xiaoman 完全开放,其他需白名单
3.2 优化建议
统一代理 :可考虑移除代理(如果网络可达)安全策略 :生产环境建议使用 pairing 模式Streaming :可开启流式响应提升体验
四、完整对接方案
4.1 目标架构
┌─────────────────────────────────────────────────────────────┐ │ 用户 │ ├──────────────┬──────────────────────┬──────────────────────┤ │ Telegram │ 飞书 │ │ │ (原生) │ (原生) │ │ └──────┬───────┴──────────┬──────────┴──────────┬───────────┘ │ │ │ ▼ ▼ ▼ ┌──────────────────────────────────────────────────────────────┐ │ OpenClaw Gateway │ │ ┌─────────────┐ ┌─────────────┐ ┌─────────────────────┐ │ │ │ Telegram │ │ Feishu │ │ 其他渠道 │ │ │ │ (WebSocket)│ │ (WebSocket)│ │ (WhatsApp等) │ │ │ └─────────────┘ └─────────────┘ └─────────────────────┘ │ └──────────────────────────────────────────────────────────────┘ 4.2 实施步骤
第一步:切换到原生飞书集成
停止当前 bridge 服务
配置 OpenClaw 飞书原生支持
重启 Gateway
验证飞书消息接收
# 配置飞书 openclaw channels add # 选择 Feishu,输入 App ID 和 App Secret
# 重启 Gateway openclaw gateway restart
# 查看状态 openclaw gateway status 第二步:优化 Telegram 配置
根据需要调整 DM 和群聊策略:
{ "channels": { "telegram": { "dmPolicy": "pairing", "groupPolicy": "allowlist", "streaming": "partial" } } } 第三步:配置群聊回复规则
飞书群聊支持两种模式:
strict:必须 @ 机器人才回复smart:智能判断,无 @ 也回复有价值的消息
{ "channels": { "feishu": { "accounts": { "main": { "groupPolicy": { "groups": { "oc_0c097efa8e1dd026ed84a61d7a22fe80": { "requireMention": true } } } } } } } } 五、飞书 Bot 高级功能
5.1 当前飞书 Bot 能力
基于现有配置,空空拥有的飞书 Bot:
能力 │ 状态 │ 说明 ─────────────┼──────┼───────────────── 接收私聊消息 │ ✅ │ DM 策略:开放 接收群聊消息 │ ✅ │ 需 @ 或在群里 发送消息 │ ✅ │ send_as_bot 发送卡片消息 │ ✅ │ Interactive Card 处理媒体 │ ✅ │ 图片、文件等 5.2 飞书 API 能力(需额外配置)
能力 │ 权限名称 │ 用途 ─────────────┼───────────────────────────────────┼───────────── 读取用户信息 │ contact:user.employee_id:readonly │ 获取用户身份 上传文件 │ im:resource │ 文件上传下载 创建群聊 │ im:chat:create │ 自动建群 @人 │ at:user │ 群聊@功能 5.3 消息类型支持
类型 │ 支持 │ 说明 ───────┼──────┼───────────────── 文本 │ ✅ │ 基础文本消息 富文本 │ ✅ │ post 消息 卡片 │ ✅ │ Interactive Card 图片 │ ✅ │ image 消息 文件 │ ✅ │ file 消息 语音 │ ✅ │ audio 消息 六、问题排查
6.1 常见问题
问题 │ 可能原因 │ 解决方案 ───────────────┼──────────────────┼───────────────────────── 飞书消息收不到 │ Gateway 未运行 │ `openclaw gateway start` 事件订阅失败 │ WebSocket 未连接 │ 检查 gateway 状态 权限不足 │ 权限未配置 │ 在飞书开放平台添加权限 群聊无法回复 │ 未发布应用 │ 提交审核并发布 6.2 调试命令
# 查看 Gateway 状态 openclaw gateway status
# 查看飞书通道日志 openclaw logs --follow | grep -i feishu
# 测试发送消息 openclaw message send --to <user_id> --message "测试"
# 飞书通道诊断 openclaw doctor 七、结论与建议
7.1 当前评估
维度 │ Telegram │ 飞书 ───────────┼────────────────┼───────────────────────── 集成方式 │ 原生 WebSocket │ Webhook Bridge(需改造) 稳定性 │ 高 │ 中(依赖 bridge) 功能完整性 │ 完整 │ 部分(bridge 限制) 维护成本 │ 低 │ 高(额外服务) 7.2 建议方案
推荐:切换到原生飞书集成
优点:
无需公网暴露(WebSocket 长连接)
功能完整(原生支持所有飞书能力)
维护简单(OpenClaw 内置)
稳定性高
实施难度:
中等(需要重新配置飞书应用)
需要停机迁移(约 5 分钟)
7.3 实施优先级
P0 :切换飞书到原生集成P1 :优化 Telegram 配置P2 :添加飞书高级功能(文件上传、用户识别等)
附录
A. 飞书应用权限清单
im:message # 接收消息 im:message:send_as_bot # 发送消息 im:message:readonly # 读取消息 im:chat.members:bot_access # 获取群成员 im:resource # 资源文件 aily:file:read # 读取文件 aily:file:write # 写入文件 B. 相关链接
C. 当前配置参考
飞书 App ID: cli_a9147270bf785eef 飞书 App Secret: E0uJ4NbE4eAlMzN2wxbZIfTLgtmxZahD GenGo 群 chat_id: oc_0c097efa8e1dd026ed84a61d7a22fe80 测试群 chat_id: oc_ff7ba9324d31ac25051ddb1e927cfa2b 空空 open_id: ou_f51b1ac9513c91b557b2e1017ae75fc4 报告撰写 :小满 🌾
最后更新 :2026-03-13 18:55 GMT+8
更新时间:2026-06-01
项目状态卡
字段
内容
当前阶段
机会池 / 初步整理
优先级
P2
当前评分
待正式评分
话题发起人
[已脱敏]
当前推进人
默认同话题发起人;显示名待补充
最近更新时间
2026-06-01
当前判断
这是一个面向 3-8 岁儿童的 AI Native 创意互动方向,核心价值不是把画变漂亮,而是让孩子画出来的对象进入游戏世界并动起来。方向有想象力,但儿童产品需要更谨慎验证安全、家长付费和内容边界。
下一步
先做一个场景、三类对象、五种行为的最小闭环样例,验证孩子是否能独立理解并反复创作,家长是否认可教育/创造力价值。
维护策略
低到中频更新:只有样例、儿童/家长反馈、合规安全、竞品或正式评分变化时更新。
最新进展
执行摘要
儿童 Sketch-to-Game 创意平台面向 3-8 岁儿童,核心理念是“让孩子画出来的东西活起来”。孩子选择交通、海洋、太空、动物园等主题场景后,在画板上自由绘画;AI 识别并优化儿童画,生成可动画、可互动的游戏对象,并放入场景中形成孩子自己的互动世界。
这个产品不是传统绘画工具,而是儿童想象力生成引擎。关键 aha moment 是孩子画完一个东西,几秒内它真的能动、能互动、能进入自己的世界。
目标用户
3-8 岁儿童。
希望孩子进行创造性表达的家长。
儿童教育、亲子互动和创造力训练场景。
核心痛点
传统绘画工具反馈弱,画完后很快结束。
传统儿童游戏偏消费内容,创造和表达空间有限。
家长希望孩子有创造性活动,而不是纯刷屏娱乐。
当前证据
评分与判断
暂未正式评分。建议先作为 P2 机会池项目,补充样例和家长/儿童反馈后再评分。
MVP / 验证计划
只做一个场景,例如海洋。
支持三类对象,例如鱼、船、海草。
每类对象只做基础行为,例如游动、躲避、碰撞、发声。
观察孩子是否能在 10 分钟内理解、创作并重复添加对象。
访谈家长是否愿意让孩子持续使用和付费。
风险与反证
儿童产品有安全、隐私、内容边界和家长信任问题。
如果生成反馈太慢,孩子会失去兴趣。
如果只是“画变好看”,价值会弱于“画变可玩”。
家长可能认为它仍是游戏,教育价值需要证明。
数据链接
字段
内容
project_key
[已脱敏]:[已脱敏]
thread_id
[已脱敏]
Base record_id
[已脱敏]
数据口径
6 条消息 / 4 条人类消息 / 2 条 AI 分析 / 0 个资源。
项目增强分析(2026-06-02)
口径:基于最新项目维护报告、Lark 话题真实数据与可复核公开资料整理;web_search 当前不可用,因此未二次核验的市场判断均按“趋势/假设”保守处理。
project_id: kids_sketch_to_game
project_id :kids_sketch_to_game
Wiki / Doc :WZRWwJcQMiyPiNkAV9NlM2WRgse / I5RgdidsKoRhOsxbWcDlgvv7gCh
阶段 / 优先级 :机会池 / 初步整理 / P2
更新策略 :low
话题负责人 :[已脱敏]
内部话题数据 :6 条消息 / 0 个资源;核心描述是面向 3-8 岁儿童的 AI Native 创意互动平台,“让孩子画出来的东西活起来”,孩子选择交通、海洋、太空、动物园等主题,在画板上画汽车、鱼、动物、火箭,AI 实时识别、卡通化优化、结构补全、动画生成,并进入游戏世界。
一句话机会
做儿童版“画出来就能玩”的 AI 想象力世界生成器:把孩子的涂鸦实时变成可互动角色、道具和小游戏,核心价值是创造力表达,不是让孩子被动刷游戏。
目标用户
3-8 岁儿童 :喜欢画画、角色扮演、搭建世界,但不会复杂操作。
家长 :希望孩子使用更有创造性、低沉迷、可展示作品的数字产品。
幼儿园 / 少儿美术 / STEAM 机构 :需要课堂互动工具和作品展示。
亲子内容创作者 :需要把孩子作品变成短视频、故事或小游戏。
核心痛点
传统儿童画画 App 停留在涂色/贴纸,作品“不会动”,反馈弱。
儿童游戏多是消费内容,孩子只能玩别人设计好的关卡。
ScratchJr/Roblox 等创造工具有学习门槛,低龄儿童难以从零搭建可玩内容。
家长担心屏幕时间与沉迷,需要更明确的教育/创造价值。
AI 识别儿童涂鸦存在不稳定,若反馈错误会挫伤孩子表达欲。
当前证据
内部证据
维护报告显示该话题有 6 条消息 ,虽然资源为 0,但产品愿景和交互描述完整。
原始需求明确年龄段 3-8 岁 、主题场景、画板、识别、卡通化、补全、动画、进入游戏世界,已经具备 MVP 场景定义。
既有内部整理已概括为 “儿童版画出来就能玩的 AI 想象力世界生成器” ,与本稿机会定义一致。
外部资料
ScratchJr 官网说明其面向 5-7 岁儿童 ,让孩子编程自己的互动故事和游戏,证明低龄创造型数字产品有成熟教育先例。
Roblox Creator 页面定位为 “Make anything you can imagine”,证明 UGC 游戏创作平台长期有大市场,但更偏大龄与复杂创作。
AI 图像识别、卡通化、动画生成能力成熟度提升,使低龄儿童从“编程创造”降级为“画画创造”成为可能。
竞品 / 替代方案
ScratchJr :面向 5-7 岁,儿童可编程互动故事和游戏;教育属性强,但仍需要理解积木和逻辑。
Scratch :更大龄的编程创作社区,能力强但不适合 3-6 岁无辅助使用。
Roblox Creator / Roblox Studio :创作和发布生态强,但操作复杂、年龄段偏高。
Toca Boca / Sago Mini / Pok Pok 等儿童开放式游戏 :强调探索和创造,但孩子画的内容通常不能成为游戏资产。
儿童画画/涂色 App :低门槛但互动反馈有限,缺少“作品活起来”的惊喜。
MVP 切口
建议从 “主题场景 + 单个涂鸦角色活起来” 开始:
选择一个主题:海洋 / 交通 / 太空 三选一。
孩子画一个对象:鱼、车、火箭等。
AI 识别并给出 2-3 个候选:“这是小鱼吗?还是潜水艇?”让孩子/家长确认。
系统自动卡通化、补全轮廓、生成简单动画。
放入预设小游戏:鱼游泳吃星星、车在赛道跑、火箭躲陨石。
输出可保存作品:一张作品卡 + 10 秒短视频。
验证方式
儿童即时反应 :看到自己的画动起来是否有惊喜、是否愿意继续画第二个。
家长接受度 :家长是否认为这是创造力产品而不是普通游戏;是否愿意控制使用时长。
识别容错 :AI 识别失败时,候选确认是否能避免挫败。
复玩率 :孩子是否在 24 小时/7 天内回来画新对象。
机构验证 :少儿美术/STEAM 老师是否愿意用于课堂作品展示。
风险与反证
未成年人产品涉及隐私、数据留存、图片上传、家长授权,需要极高合规标准。
3-8 岁年龄跨度大,3-4 岁更依赖家长,7-8 岁可能嫌玩法幼稚,需要分层。
如果 AI 识别儿童画错误率高,体验会从“神奇”变成“沮丧”。
游戏化过强可能被家长视为增加屏幕时间,削弱教育价值。
内容安全、UGC 分享、聊天/社区功能必须谨慎,MVP 不建议开放社区。
下一步
只做一个主题 demo(推荐海洋):画鱼 → 识别确认 → 卡通化 → 游进海里。
做离线/本地样例测试,收集 20-30 张儿童真实涂鸦,评估识别与补全稳定性。
设计家长可见的“创造力报告”:孩子画了什么、选择了什么、故事是什么。
找 5 个亲子家庭或 1 个少儿美术班做观察测试,不先上线公开产品。
明确隐私策略:不默认保存儿童照片/头像,不开放公开社区。
参考来源链接
维护边界:本章节为 2026-06-02 增强分析受控块;后续若有新客户验证、竞品变化或 Lark 话题进展,可替换本章节,不覆盖原始档案正文。
项目质量升级(2026-06-03)
口径:本章节用于替换昨日偏模板化的增强稿表达;基于 Lark 话题真实数据、项目 mapping、既有维护报告与公开竞品格局,强调判断、边界、验证和反证。不覆盖原文其它章节。
project_id: kids_sketch_to_game
project_id :kids_sketch_to_game
标题 :儿童 Sketch-to-Game 创意平台
Doc / Wiki :I5RgdidsKoRhOsxbWcDlgvv7gCh / WZRWwJcQMiyPiNkAV9NlM2WRgse
阶段 / 优先级 :机会池 / 初步整理 / P2
内部数据 :维护报告显示 6 条话题消息、0 个资源;原始需求明确为面向 3-8 岁儿童,让孩子画汽车、鱼、动物、火箭等对象,AI 实时识别、卡通化、补全、动画生成,并进入游戏世界。
当前判断
这是一个非常有想象力的儿童 AI Native 产品,但立项门槛比普通消费工具高。它的核心不是“画画 App”,也不是“儿童游戏”,而是 让孩子自己的画变成可互动对象 。
真正的 aha moment 是:孩子画了一条鱼,几秒后这条鱼游进海里,还能吃星星、躲章鱼、和其他自己画的东西互动。
当前建议保持 P2,不直接做公开产品,先用家庭/课堂 demo 验证三件事:孩子是否惊喜、是否愿意继续画第二个、家长是否认为这是创造力而不是又一个游戏。
用户 / 痛点
3-8 岁儿童 :喜欢画画、编故事、角色扮演,但不会复杂编程和搭建。
家长 :希望孩子使用更有创造性、低沉迷、可展示作品的数字产品。
少儿美术 / STEAM / 幼儿园老师 :需要课堂互动、作品展示、亲子活动素材。
亲子内容创作者 :希望把孩子作品转成短视频、故事或小游戏。
痛点更细地看:
儿童画画 App 常停留在涂色、贴纸,画完就结束。
儿童游戏多是消费内容,孩子玩别人设计好的关卡,很少创造自己的世界。
ScratchJr / Scratch / Roblox Studio 有创造力价值,但低龄儿童有明显理解门槛。
家长对屏幕时间敏感,产品必须把“创造”和“表达”放在“游戏刺激”前面。
AI 识别儿童涂鸦如果经常猜错,会迅速破坏孩子信心。
竞品 / 替代
ScratchJr :面向 5-7 岁,孩子可编程互动故事和游戏;教育属性强,但仍需理解积木逻辑。
Scratch :创作生态成熟,更适合大龄儿童。
Roblox Creator / Roblox Studio :UGC 游戏创作市场巨大,但门槛高、年龄偏大。
Toca Boca / Sago Mini / Pok Pok :开放式儿童游戏体验好,但孩子手绘内容通常不能变成游戏资产。
儿童画画 / 涂色 App :低门槛,但反馈弱,缺少“作品活起来”。
MVP 边界
推荐 MVP:海洋主题:画鱼 → 识别确认 → 游进海里 。
只做:
不做:
不做开放社区。
不做聊天功能。
不做无限主题和复杂关卡编辑器。
不默认上传/保存儿童照片或头像。
不做强付费道具和沉迷型循环。
验证计划
素材测试 :收集 20-30 张真实儿童涂鸦,评估识别、卡通化、补全效果。
家庭观察 :找 5 个 3-8 岁亲子家庭,观察孩子第一次看到作品动起来的反应。
课堂测试 :找 1 个少儿美术/STEAM 老师,看是否能作为 30 分钟课堂环节。
核心指标 :
孩子是否主动画第二个对象。
家长是否愿意保存/分享作品。
家长是否认为它有创造力/教育价值。
AI 识别失败时,候选确认是否能避免沮丧。
付费判断 :先验证 B2B2C 课堂工具或家庭作品包,不急于做订阅。
风险反证
下一步
维护边界:本章节为 2026-06-03 质量升级受控块;后续新证据出现时可整体替换本章节。
维护说明
你可能见过这样的同事:周报、资料整理、会议纪要都交给 AI 处理,下午 6 点准时下班。而你自己打开 AI,却还是一问一答——背景要反复解释,格式要反复纠正,最后不像在用工具,更像在和 AI 斗智斗勇。
差别不一定在你怎么跟 AI 说话,而在于他用的是能执行任务的 AI Agent(可以理解成“会自己动手干活的 AI 助理”)。
这一章不讲复杂概念,也不写代码。我会带你在 Codex App 里完整走一遍:准备一个空文件夹,做好基本配置,让 Codex 自己安装一个公司 Skill 库(一批别人攒好、打包在一起的方法),最后用一个现成 Skill 帮你审一篇文章。整个过程不涉及命令行,你只需要照着做,看到 Codex 真的动起来、并留下结果,就完成了最重要的一步。
顺利的话,这一篇从准备到跑通大概二三十分钟,中间每一步都有截图,跟着做就行。
这里先假定你已经会注册、安装、登录 Codex,这些不在本文展开。
为什么要用 Agent
普通聊天 AI 主要是在“回答”你:你问一句,它答一句;你补一句,它改一点。AI Agent 不一样——你给它一个目标,它会按步骤执行,能检查文件、发起必要的操作、看结果,再把结果写回文件。
普通聊天 AI
AI Agent
你问一句,它答一句
你给目标,它拆步骤执行
主要给建议和文本
能读文件、跑命令、调用工具、检查结果
每次都要重新解释背景
可以复用已有的工作方法
更像顾问
更像会动手的助理
这一章你先不用理解所有细节,先体验一次:把一个明确任务交给 Codex,让它真的动起来。
Skill 的作用
Agent 会动手,但它不一定知道你的工作习惯:什么内容要先查固定口径、什么情况不能直接改、会议纪要按什么格式归档、复盘里哪些话不能写得太虚。这些通常得你一次次告诉它。
你可以先把 Skill 理解成一份给 Agent 用的工作方法 :它会告诉 Agent 什么时候用、按哪几步做、输出什么、遇到什么情况要先停下来问你。
一句提示词解决“这一次怎么说”;一个 Skill 解决“以后都按这套做”。
这一章不会让你写 Skill,你只需要先用 Codex 跑一次安装任务,再亲手试一次它的效果。
第一步:准备好文件夹——Codex 的主战场
Codex 做事需要一个文件夹。它会在这个文件夹里读文件、写文件、执行检查,所以文件夹就是它干活的工作台。没有文件夹,它就只能跟你聊天,发挥不出 Agent 的价值。
怎么管理这些文件夹,有一条简单原则值得从一开始就养成:
一个项目一个文件夹。
这样做有两层好处:
文件隔离 :每个项目的产出各放各的,Codex 生成、修改的文件不会和别的资料混在一起,也不会误伤你的正式文档。上下文隔离 :Codex 只看得到当前文件夹里的内容。文件夹越聚焦,它对“你在做什么”的判断就越准,不会被无关资料带偏。
第一次上手,先在桌面新建一个空文件夹,命名为 codex-tranfu-demo。新建文件夹这种事你肯定已经会了,这里不再赘述。需要稍微留意的,是怎么在 Codex 里打开 它。
打开 Codex,找类似这样的入口(不同版本叫法略有差异):
鼠标移动到“项目”那一行
会出现最右边那边文件夹然后有一个加号角标的图标,点击它
选择“使用现有文件夹”
选择刚才新建的 codex-tranfu-demo。如果 Codex 提示你确认是否信任这个文件夹,放心确认——它是你刚新建的空文件夹,里面没有任何东西。
打开好之后应该是这样。
打开错了文件夹也不要紧,退出重新选 codex-tranfu-demo 即可。
第二步:做好基本配置——让 Codex 放开手脚
默认设置下,Codex 每做一个动作都可能停下来问你“能不能执行”,模型也未必是最强的那个。第一次上手为了顺畅,建议先调两个地方。
设置项
建议
为什么
权限
设为 Full access(完全访问)
Codex 在当前文件夹里读写文件、执行检查时不必每一步都来问你,体验会顺很多。你打开的是一个隔离的空文件夹,就算 Codex 自由发挥,能影响的也只有这个练习文件夹里的内容,碰不到你的正式资料。
模型
选 GPT-5.5,推理强度选 Extra High,速度选 Fast
任务越是多步骤,模型的推理能力越关键。推理强度拉到 Extra High,Codex 拆解和执行任务时更稳,少走弯路。以 100 美元的 Pro 套餐为例,5 小时的用量基本上是用不完的,除非你同时开好几个任务一起跑。第一次上手,放心用最好的配置。
配置好之后,后面 Codex 执行任务时基本不会再频繁打断你。它仍然会把每一步显示出来,你照样能看着它做事——如果哪一步看起来不对劲,随时可以喊停。
第三步:安装 Skill 库——别人攒好的方法直接用
想用好 Skill,一个准确、常用、好维护的 Skill 仓库很重要。你不需要自己一个个去写、去攒——直接装一个现成的库,里面别人打磨好的方法就都能用了。这里用我们公司日常在用的 Skill 库做演示。
你只需要把下面这句话复制给 Codex:
请阅读 https://github.com/tranfu-labs/tranfu-skills/blob/main/INSTALL.md 并按文档步骤帮我安装公司 skill 库.
发出去后,Codex 会按文档一步步来:
检查当前文件夹
打开安装说明
确认是否已安装
按步骤安装
最后检查结果
因为你已经开了 Full access,它通常不必再来征求许可,会自己走完。
安装完成后会大概有这样的输出(不同版本可能略微不一样)。
怎么算安装成功? 你可以这样验证:
打开一个新会话,注意一定要是咱们刚刚创建的项目右侧的开始新对话按钮
然后告诉它:
查询一下tranfu库中有哪些skill
如果不顺利,它一般也会告诉你:
无论成功还是报错,先把这张结果截图保存下来。
第四步:跑一个 Skill——当场审一篇文章
库装好了,但你还没见它干活。这一步就让一个现成 Skill 当场跑给你看。
我们先创建一个新对话。
每一个独立任务的时候,最好都新开一个对话。
我们用「营销号审核」这个 Skill 举例——它能帮你判断一篇文章是不是营销号套路、有没有夸大和带节奏。先让 Codex 把它装进当前项目:
安装 Tranfu 库中的营销号审核 Skill 到项目中
装好后,还是新开一个对话。
然后随便找一个文章链接丢给它审一审:
用营销号审核 Skill 审查这篇文章:https://zazencodes.substack.com/p/build-your-own-developer-tools-with
注意看 Codex 的反应:它会主动调用 刚装的营销号审核 Skill,而不是随口给你一段泛泛点评。看到它在执行过程里点名用到了这个 Skill,就说明 Skill 被正确激活了。
注意:这里需要两次展开才会看到它。
跑完后,它会按 Skill 设定的方式给出审查结果——哪里像营销号、哪些说法站不住脚、整体可信度如何。
到这里你已经完整体验了一遍:装库 → 装具体 Skill → Skill 真的帮你干了一件事。
第一轮完成标准
先别用“我是不是完全懂了”来判断自己。第一次动手的标准很具体——只要满足下面任意一种,就算完成。
你看到什么
算什么
接下来做什么
Codex 显示公司 skill 库已安装,并能正常使用
跑通
截图保存
营销号审核 Skill 被激活,并给出了审查结果
跑通(加分)
截图保存
Codex 输出“部分成功”,但说明卡在哪一步
阶段完成
截图保存,下一篇前处理
Codex 报错,但给了求助话术
阶段完成
把截图和话术发给同事
Codex 没法打开文件夹
阶段完成
截图发给hello@tranfu.com
保存证据比追求完美更重要。最有用的截图有这么几张:
打开 codex-tranfu-demo 的画面
Codex 开始执行的画面
安装结果的画面
Skill 被激活和审查结果的画面(如果走到了)
常见卡点
你大概率会卡在这几类地方。先列在这里,是想让你知道:第一次上手卡住,很正常。
卡点
可能原因
你现在怎么做
找不到打开文件夹的入口
Codex 版本或界面不同
截图问同事“Codex 里怎么打开文件夹”
打开了重要资料文件夹
选错文件夹
退出,重新选 codex-tranfu-demo
找不到 Full access 或模型设置
设置项位置因版本而异
截图问同事,或先用默认设置往下走
Codex 只回答概念,不执行
可能没在工作区里发任务
确认当前打开的是 codex-tranfu-demo
Codex 没给出最终结果
可能卡在安装某一步
截图保存,对话结果也算
tranfu-skills 安装失败
网络、权限或本机设置问题
截图,使用它给的求助话术
营销号审核 Skill 没被激活
库或 Skill 没装好
确认库已安装,再重发安装该 Skill 的指令
它输出一堆英文报错
本机设置或权限问题
截图,直接用它生成的求助话术
第一次上手只需要判断一件事:
这一步该继续,还是该截图求助。
最小完成版本
如果你只想先快速试一下,做到这几步就够:
在桌面新建 codex-tranfu-demo,用 Codex 打开它
设好 Full access 和模型
复制安装指令,让 Codex 装好公司 Skill 库
保存最终截图
能留下下面任意一种截图,就可以先停:
打开空文件夹的截图
执行中的截图
安装结果截图
清晰的报错截图
有报错也算——因为你已经从“我不知道从哪里开始”,走到了“我知道卡在哪一步”。
如果还有 10 分钟
可以顺手再多试一个 Skill:
让 Codex 换几个关键词搜搜库里还有什么:写作、复盘、review
挑一个看起来用得上的,让它装进项目
再像刚才审营销号那样跑一次
不用判断哪个最好,把搜到的 Skill 名称或一次执行结果截图保存下来就行。
下一篇会用一个现成 Skill,审一次你自己写给 AI 的任务说明。
关掉之后,什么还在?
你可能会担心:今天装的、聊的,关掉 Codex 是不是就没了?
记住一句话就行:
聊的会忘,装的会留。
这次对话会忘 :退出 Codex 再打开,就是一个全新的对话,它不记得你们刚才聊过什么。这跟你平时用 ChatGPT 一样,正常。装好的 Skill 不会忘 :它就存在 codex-tranfu-demo 这个文件夹里。明天打开 Codex,还选这个文件夹,它就还在。
所以明天想接着用,不用重装、也不用重新解释。打开文件夹,再说一句“用营销号审核 Skill 审这篇”就行——你不用它记得,它只要在这个文件夹里找得到 Skill 就够了。
打个比方:一个 Skill 就像贴在工位上的一张 SOP。今天带的实习生下班走了(对话关了),明天来个新实习生(新对话),墙上那张 SOP 还在,新人照样照着做。
顺带记住一条,你以后一直用得上:
想留下的东西,得落到文件里;只在对话里说的,关掉就没。
这也是为什么这一章我一直让你截图保存——审查结果也一样,想留就截图,或者让它写进文件夹。
完成结果
这篇的关键不在术语,也不在复杂工具,而在一个很关键的转变:
从“我问 AI 一个问题”,变成“我让 Codex 执行一个任务”。
从“每次重新解释”,变成“开始使用可复用的工作方法”。
从“AI 只给我一段回答”,变成“AI 能在一个文件夹里留下可检查的结果”。
这就是 Skill 系列的第一步:先让它动起来一次。后面才谈得上用好别人写的 Skill、判断自己的经验适不适合沉淀、写出自己的 Skill,最后发布给同事用。
什么样的工作值得做成 Skill
你大概以为,越难、越高大上的事,越值得做成 Skill。
恰恰相反。真正值得装进去的,往往是那种你都懒得跟人说、说出来还有点不好意思的小破事——就因为它太琐碎,你每次用 AI 都得重新交代一遍。
我们先把这件事掰开。
一句话标准:装一次,反复用
想象你身边来了个新同事,绝顶聪明,啥都会,唯独有一个毛病:他记不住你们公司的规矩 。
每次派活,你都得从头讲一遍——表格要哪几列、审稿卡哪几条、文件名按什么格式起。他做得很好,但下次你还得再讲一遍。讲到第十遍,你是不是想抓狂?
Skill 就是那张你递给他的小抄。**值得写进小抄的,是你每次都得重新交代、而他自己打死也猜不到的那套规矩和步骤。**写一次,以后他自己揣着。
听起来谁的事都能装?别急,先过两道关。两道都过,才值得动手。
第一关:这事,是不是只有你们才知道?
你随手想个活——比如"把这段话改通顺"。
打住。这种谁都会的,AI 生下来就会,你装它纯属脱裤子放屁。它早就会的东西,你写进小抄,等于教鱼游泳。
那什么才值得?是它猜不到、只能你教 的那些:你们部门那张鬼才看得懂的表格模板、你们主编那套刁钻的审稿标准、你们归档时那串龟毛的命名格式。
一句话——谁都会的,划掉;你们独有的,留下。
反例
案例
解释
"帮我把这封邮件改得更礼貌一点。"
AI 本来就会,不用做成 Skill。
"帮我给这篇文章想 10 个更吸引人的标题。"
这是通用写作能力,不用做成 Skill。
"帮我把这段话翻译成英文。"
除非你们有一套特殊术语和翻译口径,否则不用做成 Skill。
正例
案例
解释
"每周把销售同事发来的客户拜访记录,整理成 CRM 里那 6 列固定字段。"
字段名、合并规则、缺失信息怎么标,这些只有你们知道。
"发布 Practice 文章前,按我们自己的清单检查标题、摘要、series/order、未发布链接和 MOCK 标记。"
这不是普通审稿,是你们站点自己的发稿规矩。
"把候选人的面试反馈,改成 HRBP 可以直接转发的固定口径。"
哪些话能写、哪些话要收住、结论怎么排,这是你们公司的表达边界。
第二关:你能一句话说清"它什么时候该上场"吗?
这一关最容易漏,可它偏偏要命。
Skill 装好之后,不是你喊一声它才动——是 AI 自己判断什么时候该把这张小抄掏出来 。它靠什么判断?就靠你写的那句使用说明。
所以你得能一口气说清:"当我要做 XX 的时候,用它。 "说得清,它该上场时就上场。说不清,那张小抄就躺在兜里睡大觉,该用的时候它压根想不起来。
你试试对着自己的活说这句话。卡壳了?那这关没过。
反例
案例
解释
"做一个能帮我处理内容运营的 Skill。"
太大了,到底是选题、改稿、排期,还是发布前检查?AI 不知道什么时候该掏出来。
"帮我提升客户沟通质量。"
触发条件是散的:售前邮件、会议纪要、投诉回复,每一种都不是同一件事。
"遇到我觉得棘手的写作任务时,帮我判断怎么写。"
这得先靠你自己觉得棘手,AI 没法自己判断什么时候该上场。
正例
案例
解释
"当我要把客户访谈录音整理成产品需求卡片时,用它。"
场景、输入、输出都清楚,AI 知道什么时候该用。
"当我要发布一篇 Practice 系列文章前,用它检查 frontmatter、series/order、未发布链接和 MOCK 标记。"
触发点就是发稿前检查。
"当我要把一次面试反馈整理成 HRBP 可转发版本时,用它。"
不是所有面试工作都用,只在改写反馈口径这一步用。
还有一条藏起来的关:这事,你是不是老在干?
前两关都过了,先别急着庆祝。
回头看一眼:这事你多久干一次 ?要是一年才碰一回——比如年终才填那张表——那做成 Skill 也白搭。等明年用到它时,你早忘了自己还装过这么个玩意儿。
得是你反复在做、做到手疼的事,装进去才划算。
反例
案例
解释
"每年年底把部门预算表整理成老板要看的版本。"
一年才做一次,等下次用到时你很可能已经忘了这个 Skill。
"帮我为这次公司年会写一套主持人口播。"
这是一次性任务,没有反复调用的价值。
"帮我研究一下我们要不要进入日本市场。"
这更像一次决策前调研,不是会反复执行的固定流程。
正例
案例
解释
"每天把客服工单整理成产品问题、操作问题、情绪问题三类。"
高频、重复、分类规则稳定,值得沉淀。
"每周把销售拜访记录整理成 CRM 里的固定字段。"
每周都做,而且每次都要按同一套字段和规则处理。
"每次发布 Practice 文章前,检查 frontmatter、series/order、未发布链接和 MOCK 标记。"
只要发稿就要检查,重复频率够高。
拿你自己的活往里一套,无非这么几种结果
规矩讲完了。现在你脑子里那件事,往这两道关上一撞,无非这么几种结局:
结果
怎么处理
两道都过 别犹豫,就是它,动手。
卡在第一关 AI 本来就会,或者纯靠你的手感、压根没规矩可教,当场划掉,这事不配。
卡在第二关 说不清它啥时候用,多半是这事本身就说不清边到哪儿。换一件清清楚楚的先练手。
一半过一半不过 别整个扔掉,切一刀:该按死规矩、该掐准时机的那半截做成 Skill,剩下要你拿主意的那半截,自己留着。
最后这种最常见,也最值钱——下面专门说。
一个 Skill,只干一件事
你可能想造一个无所不能的超级 Skill,啥都能干。
千万别。一个啥都干的大块头,"什么时候用"这句话根本说不清——你想想,一个号称"什么都会"的同事,你反而不知道该派他干嘛。结果就是 AI 要么乱用,要么干脆不用。
**切得越小,叫得越准。**从那种"三句话能说明白、每周要重复好几遍"的小动作下手,一个 Skill 咬死一件事。
下面这些事,先别碰
照着上面的逻辑往下推,有几种活天生就过不了关,趁早死心:
类型
为什么先别碰
AI 本来就会的 谁都会的本事,你教它等于白教。
全靠手感、说不出规矩的 出创意、判断好坏,你自己都讲不清章法,拿什么写进小抄?
一年碰不上几回的 装了也想不起来用。
必须你本人拍板的 定方向、做决策,这是你的事,不是小抄能替的。
下面直接交给 AI 来判断。
直接交给AI来判断
先安装 skill-content-fit
可复制:
安装 Tranfu 库中的 skill-content-fit skill 到项目中
然后把你的例子发给它让它判断
反例
可复制:
这个适合作为skill吗 --- 上周产品评审会开完后,大家都以为别人会跟进,结果三个待办没人认领,项目延期了两天。
正例
可复制:
这个适合作为skill吗? --- 凡是涉及多人协作的会议,纪要必须在会后 24 小时内整理出行动项,每个行动项都要包含负责人、截止时间、交付物和确认人;没有负责人或截止时间的事项不能进入待办列表。
把你的方法写成第一个 Skill
你可能以为,写第一个 Skill 最难的是学会 SKILL.md 怎么写。
其实不是。
SKILL.md 看着像技术文件,但这部分最不用你操心。格式、字段、目录、排版,Codex 都会。真正难的是把你脑子里那套“我平时就是这么做的”,说成一组别人也能照着执行的规则。
先把一个误区拆掉:你会判断,不代表 Codex 会复用你的判断。
比如,一篇稿子哪里虚、会议纪要漏了哪个待办、prompt 为什么跑偏,你通常一眼能看出来。但写 Skill 不能只写结论,要把判断依据写出来:你看哪些信号、缺了什么就放进待确认、什么情况必须停下来问。
所以不要写这种规则:
帮我整理得清楚一点。
这句话太空。Codex 会按通用理解去整理,最后给你一份格式整齐、语气礼貌的东西。但哪些决定必须保留、哪些内容要放进待确认、哪些表达不符合你的习惯,它还是不知道。
这一篇只解决一个问题:把这套判断依据写进当前项目的 Skill 文件。不是让 Codex 在聊天里生成一段草稿,而是让项目里真的多出一个下次还能继续调用的 SKILL.md。
按下面五步走:
先定题目高度。
让 Codex 访谈你。
让 Codex 在当前项目里落文件。
立刻用 prompt-review 压一遍。
拿真实素材跑一遍。
别跳步。前面没定准,后面会写散;没有真实素材验证,Skill 看起来能用,实际使用时还是会跑偏。
第一步:先把题目高度定准
一个 Skill 最怕两种死法。
第一种是太窄。你把它写成“飞书会议聊天记录整理”,结果下次别人给你一段录音转写,Codex 想不起来用它。
第二种是太宽。你把它写成“资料整理”,结果会议纪要、读书笔记、销售线索、周报复盘全往里塞。最后这就不是 Skill,是大杂烩。
你要的是中间那一档:
题目
判断
飞书会议聊天记录整理
太窄
资料整理
太宽
会议记录整理
能用
先写三句话:
这个 Skill 处理:[输入是什么]
它产出:[结果长什么样]
它不处理:[边界是什么]
比如:
这个 Skill 处理:会议录音转写、会议聊天记录、零散会议笔记
它产出:结构化会议纪要
它不处理:会议观点润色、战略判断、替负责人拍板
这三句话像给 Skill 画地盘。地盘太小,它出不了门;地盘太大,它开始乱跑。
判断标准很粗暴:
换一个同类输入,它还适用吗?
适用,就保留。
不适用,就太窄。
什么输入都适用,就太宽。
如果你卡住,别自己闷头想。直接把这一步丢给 skill-domain-framing。
安装 skill-domain-framing
安装 Tranfu 库中的 skill-domain-framing skill 到项目中
还是以之前的会议纪要为例,你只需要这样说
创建skill --- 凡是涉及多人协作的会议,纪要必须在会后 24 小时内整理出行动项,每个行动项都要包含负责人、截止时间、交付物和确认人;没有负责人或截止时间的事项不能进入待办列表,内容是当提到小王的时候,就合并进他的工作安排中,工作安排通常在项目路径下的week-jobs/xiaowang.md中 然后AI会加载对应的Skill
这时候你会发现它自动就帮你锁定比较合适的领域来定义你的skill了
第二步:让 Codex 访谈你
AI有一个毛病是做得太快想得太少,刚刚它直接全流程走完直接就生成了一个Skill,但实际上还有很多不清楚的地方
这个事情的时候就需要你对AI说
根据我最开始的描述,通过提问的方式帮我细化各种不明确的地方,在选项中你会帮我思考几个可能的选择和最推荐的选择以(推荐)为开头来标注
跟AI一起思考把各个流程细化,越贴合你们的真实场景,这个Skill就越有用
第三步:确认 Skill 创建的位置
你可能注意到了,我们一路创建Skill下来,没有指定在哪里创建,那么这个Skill去哪了?
告诉我这个Skill在哪,路径是什么
路径在我们项目文件夹下的 .codex/skills/organize-meeting-actions
第四步:立刻用 prompt-review 测一遍
现在我们已经写好初始版本了,但是是以我们自己的视角,尽可能还原工作流等等约束来写的,这就一个问题
后面是AI读取它之后不一定会完全按照它的来,这就需要我们略微修改它里面的措辞和全篇的结构
这里我们直接用tranfu库中的prompt-review来帮我们做这一步即可
用tranfu skill 中的 prompt-review skill来审核它
没有安装这个Skill也没有关系,AI会自动帮我们安装,最后执行过是这样
具体的修改你可以点击这里已编辑Skill看到,你会看到它做的修改一般是:
一类改动是把具体的一些单词变成大写,这是因为关键的NOT这类单词大写之后在大模型读取的权重会更高一些,更能够听从指令
还有一类改动增加正例与反例,这是因为你告诉AI一些抽象约定它理解的意思可能和你表达的意思有很多不一致的地方,这个时候就需要正例与反例对齐你们的理解
第五步:拿真实素材跑
到这里,Skill已经写好了,也优化过一遍了。现在才轮到测试。
回顾一下我们的skill的目标
凡是涉及多人协作的会议,纪要必须在会后 24 小时内整理出行动项,每个行动项都要包含负责人、截止时间、交付物和确认人;没有负责人或截止时间的事项不能进入待办列表,内容是当提到小王的时候,就合并进他的工作安排中,工作安排通常在项目路径下的week-jobs/xiaowang.md中
那么当我们提供一个新的会议纪要的时候,AI应该识别里面小王的内容,然后把他对应的工作写进week-jobs/xiaowang.md中
下面是我们的案例:
会议案例:小程序改版排期讨论
小张:今天我们主要确认小程序改版的排期。首页、活动页和数据埋点都要同步推进,先听一下进度。
小丽:设计稿已经完成七成,首页结构没问题,但活动页的优惠规则还没最终确认。我需要运营在明天下午前给到完整文案和规则。
小王:开发这边可以先做首页和基础组件,活动页等规则确定后再接入。现在风险主要是接口字段不稳定,如果后端本周五前不能定稿,下周联调会被影响。
小张:后端我来协调。小王,你先按现有字段做 mock,不要等接口完全完成。
小王:可以。我今天会把组件拆分方案发出来,明天开始写首页,预计三天完成第一版。
小丽:我会在今晚补齐首页细节,包括空状态、加载状态和错误提示,避免开发时反复确认。
小张:很好。那结论是:小丽明晚前交完整设计细节,小王本周完成首页开发,我负责推动接口定稿。周五下午我们开一次短会,只看阻塞项,不重新讨论方案。
你会看到AI已经加载了我们的Skill,并正确修改了xiaowang.md,具体内容点击之后可以查看得到,
这一篇你真正完成了什么
你不是学会了写一个文件。
你是把一段每次都要重新解释的工作方法,搬进了当前项目。
以前你每次都要说:
这个会议纪要按我们那个格式来。
没有负责人别乱写。
没拍板的别写成结论。
不确定先问我。
现在这些话进了 SKILL.md。下次在同一个项目里,Codex 不需要你从头讲一遍。
这就是 Skill 和普通 prompt 最大的区别。
prompt 像一句临时吩咐,说完就散。
Skill 像贴在项目墙上的规矩。对话换了,任务换了,只要项目还在,那张规矩还在。
最后只记这条路径:
skill-domain-framing 定高度Codex 访谈你
Codex 在当前项目落文件
prompt-review 立刻优化真实素材跑两轮
写 Skill 不是把话说得更漂亮。
是把话说到下次不用再说。
发布你的第一个 Skill:tranfu-publish 流程
你可能以为,发布一个 Skill,就是打开终端,敲一串看起来很专业的命令。
但在这里,真正的玩法刚好反过来:你不自己搬箱子,你让 Codex 把箱子搬到公司库门口,再让它给你拿回一张 GitHub PR 小票。拿到它,才算这个 Skill 真正走上了“可以被别人看到、检查、合并”的发布流程。
开始之前,先确认三件事:
已经读完第 1、2、3 章。
已经有一个本地 Skill。
当前正在用 Codex 操作。
本章的目标很简单:
让 Codex 把本地 Skill 提交到公司库,拿到 GitHub PR 链接。
全程只和 Codex 对话。
不要自己敲命令。
这句话很重要。发布流程里最怕的不是慢,而是你手一快,绕过了检查点。就像寄快递,地址、收件人、包裹内容都还没核对,你已经把箱子扔上车了。车是开了,至于开到哪里,就不好说了。
1. 先检查钥匙:GitHub 登录
发布到公司库,第一道门是 GitHub 登录。
你可以把 GitHub 理解成公司库大门上的电子锁。Codex 再能干,也得先确认这台机器有没有开门权限。不然它最多只能站在门口,礼貌地告诉你:我进不去。
复制下面这段话给 Codex:
检查当前机器是否具备发布 Skill 到公司库的 GitHub 登录状态。
要求: 1. 全程你来检查 2. 告诉我当前 GitHub 用户名 3. 如果已登录,输出:GitHub 登录已就绪 4. 如果未登录,引导我完成授权 5. 如果缺少发布所需工具,输出一段给环境负责人的求助话术 你要看到的成功标准是:
GitHub 登录已就绪GitHub 用户名:[你的账号]
2. 检查货物:本地 Skill 能不能发布
发布前先确认两件事:
请确保你的 Skill 已经走完了上一章的创建 Skill 的流程,保证 Skill 是一个基础合格的 Skill。
确保 AI 可以读取到你的 Skill,如果你不确定,可以问一下 AI。
示例话术可以这样判断:
类型
示例话术
判断
反例
我打算发布一个 meeting-saver skill,你可以访问得到它吗?
访问不到时,要检查名字是否打错,或者之前的 Skill 是否不在这个文件夹。
正例
我打算发布一个 organize-meeting-actions skill,你可以访问得到它吗?
organize-meeting-actions 是我们上一篇创建的,它可以正确访问得到。
反例截图:
正例截图:
3. 开始发布:
这里不需要执行什么终端命令,只需要告诉Codex一句话,它就会帮我们做:
把 organize-meeting-actions skill 分享到 Tranfu 库
为什么这里会有一个临时文件?
项
说明
默认 SKILL.md
只有 name 和 description 两个属性。
Tranfu 库补充字段
version、author、updated_at、origin。
临时文件作用
先把这些准备好,然后放到 Tranfu 库中。
接下来你需要干什么
跟它说一句发布即可。
4. 拿到 PR 链接:发布成功长什么样
跟AI说发布了之后,你会发现它返回了一个链接,
如果你是我们Tranfu公司的员工,还会收到一条通知
这里我解释一下里面最核心的概念:
等待审批完成之后,你会看到这样一条消息在Lark群中
5. 发布成功
到这里,你已经完成了第一次 Skill 发布。
用会议后事项跟进 Skill 讲透新手最常见的 8 个坑
这一章不再泛泛讲“Skill 要不要装很多”。
我们只盯着一个真实场景:
凡是涉及多人协作的会议,纪要必须在会后 24 小时内整理出行动项,每个行动项都要包含负责人、截止时间、交付物和确认人;没有负责人或截止时间的事项不能进入待办列表,内容是当提到小王的时候,就合并进他的工作安排中,工作安排通常在项目路径下的 week-jobs/xiaowang.md 中。
这不是一个“会议纪要润色”需求。
它真正要做的是会议后事项跟进:
从会议材料里识别行动项。
过滤掉缺少负责人或截止时间的事项。
保留负责人、截止时间、交付物、确认人。
遇到小王相关事项时,合并进 week-jobs/xiaowang.md。
这类 Skill 特别适合拿来讲新手坑。
因为它看起来很小,实际边界很容易滑坡。你一不小心,就会把它写成“所有会议都管、所有待办都管、所有人的工作安排都管、所有项目管理都管”的超级 Skill。到最后,它既容易误触发,又容易改错文件,还会在每次触发时吃掉一大块上下文。
先把结论放前面:
会议后事项跟进 Skill 应该是项目级、强触发、轻正文、窄边界、可回归的工作单元。
为什么?
因为 Skill 不是常驻大脑增强包。Codex 通常先看到 Skill 的名字和 description,等任务相关时才加载完整 SKILL.md。一旦加载,正文就会进入上下文,和用户请求、对话历史、系统提示一起竞争空间。1 2
所以这一章用同一个会议后事项跟进 Skill,讲 8 个新手最常踩的坑。
1. 把项目规则装到用户级
会议后事项跟进 Skill 的第一件事不是写正文,而是先判断它应该装在哪里。
这个案例里有一条非常关键的线索:
工作安排通常在项目路径下的 week-jobs/xiaowang.md 中
只要规则写到了项目路径、项目文件、项目成员,就优先放项目级 Skill。
比如你的项目是 /Users/wing/Develop/codex-tranfu-demo,那么这个 Skill 更适合放在 /Users/wing/Develop/codex-tranfu-demo/.codex/skills/organize-meeting-actions/SKILL.md。
它不适合直接装到用户级。
原因很简单:week-jobs/xiaowang.md 不是你所有项目都有的文件。小王也不是你所有项目里都有的人。把这条规则装到用户级,Codex 在别的项目里也可能误以为应该找这个文件,甚至创建一个不该出现的 week-jobs/xiaowang.md。
用户级更适合放通用方法,例如:
如何判断 Skill 是否值得创建。
如何审查 Skill 的 description。
如何发布或安装 Skill。
如何用提问澄清不明确需求。
项目级才适合放这类规则:
多人协作会议会后 24 小时内整理行动项。
行动项必须包含负责人、截止时间、交付物、确认人。
没有负责人或截止时间不能进入待办列表。
小王相关事项要合并到 week-jobs/xiaowang.md。
判断方法很直接:
规则内容
推荐位置
所有项目都适用的 Skill 写作方法
用户级
所有会议都适用的行动项基本格式
可能用户级
绑定某个项目路径的工作安排规则
项目级
绑定某个成员文件的小王跟进规则
项目级
新手常犯的错,是把“我常用”误认为“所有项目都该用”。
会议后事项跟进 Skill 要反过来想:
只要它会读写当前项目里的具体文件,就先按项目级处理。
2. 不先判断主 Skill,就让相邻 Skill 抢边界
更准确地说,问题通常不在“你会不会拆出很多微 Skill”。
真实工作里,很少有人按程序步骤拆零件,把每个字段检查都做成独立 Skill。
更真实的问题是:你的工作台里已经有几个“看起来都能处理一点”的 Skill。
比如:
Skill
看起来能处理的部分
meeting-notes-summary把会议记录整理成正式纪要
project-todo-triage从项目材料里提取待办和风险
weekly-worklog-sync把成员事项合并进 week-jobs/
lark-meeting-cleanup清理飞书会议转写和聊天记录
follow-up-message-draft根据待办起草会后提醒话术
这些名字都合理,也都不是瞎拆。
问题是,用户只说一句:
把这次会议里小王的后续事项整理一下。
到底该用哪个?
Skill 不是越多越强。它更像按需调用的操作卡片。装很多 Skill,不代表它们每次都会一起帮忙;Skills 会按任务相关性自动使用,不需要你每次手动点名。3
这里要先判断“主 Skill”。
主 Skill 不看输入长什么样,而看最后不可省的结果是什么。
如果用户只是要:
把这段会议记录整理成纪要。
那主 Skill 可以是 meeting-notes-summary,甚至普通 prompt 就够。
如果用户要:
把会议里小王的后续事项整理出来,并合并进他的工作安排。
那主 Skill 就应该是项目级的:
organize-meeting-actions
因为这个任务的成败,不取决于纪要写得漂不漂亮,而取决于:
有没有提取可跟进的行动项。
有没有过滤掉缺负责人或截止时间的事项。
有没有把小王相关事项合并进 week-jobs/xiaowang.md。
有没有保护旧任务不被覆盖。
其它 Skill 可以作为辅助,但不应该抢主导。
比如飞书转写很乱,可以先让 lark-meeting-cleanup 清理材料;但真正决定行动项是否进入待办、是否写入 week-jobs/xiaowang.md 的,仍然应该是 organize-meeting-actions。
装之前先问这 5 个问题:
问题
通过才装
下周还会处理同类会议吗?
会
是否每次都要检查行动项字段?
是
是否每次都要更新小王工作安排?
是
是否比临时 prompt 更稳定?
是
是否能和已有会议、待办、周报 Skill 分清主次?
能
这些就先别装:
只是把会议内容总结得更好听。
只偶尔给小王整理一次任务。
description 写成“资料整理、待办管理、项目推进”。和已有会议纪要 Skill 只有名字差异,没有不同失败标准。
需要读写文件,但你没确认它会改哪些路径。
你可以让 Codex 先帮你清理 Skill 工具台:
帮我审查当前可用的 Skills。
只围绕“会议后事项跟进”判断: 1. 哪个 Skill 应该做主 Skill 2. 哪些 Skill 只能作为前置清理或辅助输出 3. 哪些 description 太泛,可能抢错任务 4. 哪些应该合并、改名、收窄或暂时不用
输出判断理由和建议动作,不要解释概念。 一个好 Skill 不靠名字多,而靠主任务判断稳定。
会议后事项跟进就是这种任务:重复、规则明确、出错成本不低。
3. description 写成了“会议纪要整理”
会议后事项跟进 Skill 最容易死在 description 上。
坏例子通常长这样:
description : 整理会议纪要、提取待办事项、优化会议内容。 这句话看起来没错,但太宽。
它会带来三个问题。
普通会议摘要也可能触发它。用户只是想要一段纪要摘要,Codex 却可能开始检查负责人和截止时间。
普通待办整理也可能触发它。用户只是整理个人 todo,Codex 却可能去找 week-jobs/xiaowang.md。
文章或周报润色也可能误触发。因为“优化会议内容”这几个字太像内容处理 Skill。
description 是 Skill 的门牌。Codex 通常先看门牌,再决定要不要把完整 SKILL.md 读进来。门牌写宽了,路过也会进;门牌写窄了,该进的时候不进。4
这个案例的 description 要把四件事写清楚:
维度
要写清楚的内容
输入
多人协作会议的录音转写、聊天记录、零散会议笔记
输出
可跟进的行动项,以及小王工作安排文件的合并更新
触发
用户要求整理会议后事项、会后待办、小王相关会议任务
排除
普通摘要、文章润色、个人备忘、替负责人拍板
可以这样写:
description : 整理多人协作会议的录音转写、聊天记录和零散笔记,提取会后行动项,并检查每个行动项是否包含负责人、截止时间、交付物和确认人;没有负责人或截止时间的事项不得进入待办列表。当会议内容提到小王,或用户要求同步小王的会议后事项时,把属于小王的行动项合并进项目内 week-jobs/xiaowang.md。用于会议后事项跟进、会后待办整理和小王工作安排同步。不要用于普通会议摘要、文章润色、个人备忘、战略判断、绩效评价,或替负责人确认未拍板事项。 写完以后不要凭感觉说“应该可以”。直接做触发测试。
应该触发:
把这次会议里的行动项整理出来,提到小王的同步到他的工作安排。
这段飞书会议记录按会后待办处理,负责人和截止时间不全的不要进列表。
小王在会上认领的任务帮我合并进 week-jobs/xiaowang.md。
不应该触发:
把这次会议摘要写得更正式一点。
帮我润色这篇周报。
整理一下我今天的个人 todo。
评价一下小王这周表现怎么样。
可复制:
请帮我优化这个会议后事项跟进 Skill 的 description。
要求: 1. 保留“多人协作会议 -> 行动项 -> 小王工作安排文件”的边界 2. 明确负责人、截止时间、交付物、确认人四个字段 3. 明确没有负责人或截止时间不能进入待办列表 4. 补上 8 条应该触发的真实用户说法 5. 补上 8 条不应该触发的相邻场景 6. 只改 description,不改正文
Skill 路径: [粘贴 SKILL.md 路径] 如果会议后事项 Skill 经常误触发,先别急着怪模型。多数时候,是 description 把“会议摘要”“待办管理”“项目管理”这些相邻任务也写进来了。
4. 把所有会议规则都塞进 SKILL.md
会议后事项跟进 Skill 一旦触发,完整 SKILL.md 会进入上下文。
这就是为什么它不能写成一份“会议管理百科”。
上下文窗口是公共资源。Skill 会和系统提示、对话历史、其他 Skill 元数据、用户请求一起竞争上下文。即使 SKILL.md 写得有道理,只要它太长,一旦加载,每个 token 都会和其它信息抢位置。1
这个案例的主文件应该很短。
应该放进 SKILL.md 的,是执行时必须马上知道的规则:
只处理多人协作会议后的事项跟进。
行动项必须包含负责人、截止时间、交付物、确认人。
没有负责人或截止时间,不得进入待办列表。
提到小王时,合并进 week-jobs/xiaowang.md。
更新文件前先读取现有内容,避免覆盖旧任务。
无法判断负责人、截止时间或确认人时,放入待确认,不要编造。
不应该放进主文件的,是低频背景:
公司会议文化说明。
所有团队成员的职责介绍。
会议纪要写作教程。
项目管理理论。
历史会议完整样例。
如果确实需要长资料,拆到 references/:
Reference
放什么
references/action-item-format.md行动项字段和示例
references/team-members.md团队成员角色说明
references/follow-up-examples.md历史会议样例
但只拆出去还不够。你还要写清楚什么时候读。
这样写才有用:
当用户要求解释行动项字段格式时,读取 references/action-item-format.md。
当会议里出现不熟悉的成员简称时,读取 references/team-members.md。
当用户要求对齐历史写法时,读取 references/follow-up-examples.md。
默认不要读取 references/ 下的长样例。
别只写:
更多资料见 references/。
这句话对 Codex 没什么帮助。它知道有仓库,但不知道该翻哪一箱。
固定检查可以脚本化。
比如这个 Skill 的稳定校验可以放到 scripts/:
检查输出行动项是否都有负责人。
检查输出行动项是否都有截止时间。
检查是否意外删除 week-jobs/xiaowang.md 里的旧任务。
检查是否把待确认事项写进正式待办列表。
还有一类内容既不是 references/,也不是 scripts/。
它是关键任务流程里的显式动作。
比如会议后事项跟进 Skill 如果只写:
这不够。
这些话太软,Codex 很可能直接往下做。关键流程缺失时,要把 Codex 里更接近的动作写明白。Codex 官方建议复杂或模糊任务先 plan,也可以让 Codex 先 interview 你;subagents 也不会自动触发,必须明确要求 spawn / delegate。5 6
在这个 Skill 里可以这样写:
缺的不是规则,而是流程动作
在 Codex 里应该写成
会议目标、确认人、目标文件不清楚
先进入 Plan mode,或先 interview 用户,问清缺失字段再执行
步骤多,容易漏读旧文件或漏验证
维护执行计划,逐步更新 update_plan:提取、过滤、读旧文件、合并、验证7
会议材料很长,提取行动项会污染主上下文
显式 spawn 一个 subagent,只负责从材料里提取候选行动项并返回摘要
需要实际落地到项目文件
明确读 week-jobs/xiaowang.md、合并编辑、再检查 diff
注意,这里不是把 Claude Code 的 AskUserQuestion、TaskCreate 这些名字照搬进 Codex Skill。
更稳的写法是写 Codex 能直接执行或理解的动作:
如果关键字段缺失,先进入 Plan mode 或 interview 用户,不要继续写文件。
如果会议材料超过一屏或包含多场会议,spawn 一个 subagent 只做候选行动项提取;主 agent 负责判断哪些能进入正式待办。
执行过程中维护 update_plan,至少包含:提取行动项、过滤缺字段事项、读取小王旧工作安排、合并新事项、检查 diff。
可复制:
请压缩这个会议后事项跟进 Skill。
目标: 1. 删除会议管理科普和 Agent 已经知道的通用解释 2. 保留触发边界、行动项字段、待确认规则、文件更新规则 3. 把低频样例拆到 references/ 4. 把可机械检查的字段完整性规则放到 scripts/ 5. 在 SKILL.md 里写清每个 reference 和 script 什么时候使用 6. 补上关键流程动作:什么时候 Plan/interview,什么时候 update_plan,什么时候 spawn subagent,什么时候读写文件 7. 不改变“多人协作会议 -> 行动项 -> 小王工作安排”的任务边界
Skill 路径: [粘贴 SKILL.md 路径] 会议后事项跟进 Skill 费不费 token,不只看它有没有用,还看它有没有把低频资料全带上桌。
5. 把会议后事项跟进扩大成项目管理
这个 Skill 应该写大一点,还是拆小一点?
不要按字数判断。
按工作单元判断。
更稳的方法是问三件事:
输入是不是同一类?
产出是不是同一种?
失败标准是不是同一个?
对会议后事项跟进来说:
维度
会议后事项跟进的判断
输入
多人协作会议材料
产出
结构化行动项,以及小王工作安排文件更新
失败标准
漏掉行动项、编造负责人、缺少截止时间、覆盖旧任务、误改无关文件
这些可以放在同一个 Skill 里:
候选范围
判断
会议录音、会议聊天记录、零散会议笔记 -> 行动项
可以合
行动项字段完整性检查
可以合
小王相关行动项 -> week-jobs/xiaowang.md
可以合
读取旧工作安排并合并新任务
可以合
这些不要顺手塞进去。不是因为它们不重要,而是它们更像另一个主任务:
候选范围
判断
把所有成员的事项统一归档到 week-jobs/
可能是 weekly-worklog-sync
从会议结论更新项目排期表
可能是项目排期维护 Skill
给参会人起草会后提醒消息
可能是会后沟通 Skill
把会议记录改写成正式纪要
可能是会议纪要 Skill
根据会议内容生成周报
可能是周报 Skill
为什么“写入小王文件”可以合?
因为它不是另一个任务,而是这个会议后事项跟进流程的落地动作。会议里提到小王,如果不更新他的工作安排,这个 Skill 的目标就没完成。
为什么“所有成员事项归档”不要直接合?
因为输入、输出、失败标准都变了。它不再是处理一场会议里的小王事项,而是在维护一套成员工作台账。那可以是另一个 Skill,也可以是后续工作流,但不该悄悄塞进当前 Skill。
可复制:
帮我判断这个会议后事项跟进 Skill 应该拆还是合。
候选范围: 1. 整理多人协作会议行动项 2. 检查负责人、截止时间、交付物、确认人 3. 小王相关事项写入 week-jobs/xiaowang.md 4. 把所有成员事项统一归档到 week-jobs/ 5. 根据会议内容起草会后提醒消息
只按这 3 个标准判断: 1. 输入是不是同一类 2. 产出是不是同一种 3. 失败标准是不是同一个
最后输出: 1. 保留一个 / 拆成几个 / 合并到已有 Skill 2. 推荐 Skill 名称 3. 推荐 description 边界 4. 不要覆盖的相邻场景 判断拆还是合,不要问“它能不能顺手也做”。会议后事项跟进 Skill 的边界,通常就是被“顺手把所有人的安排也同步一下”撑爆的。
6. 把每次 prompt 都复制成 Skill 正文
prompt 管这一次。
Skill 管以后每一次。
会议后事项跟进特别适合说明这个区别。
如果你只是在某一次会议后说:
这次纪要写得口语一点。
这次只保留技术相关事项。
这次不要更新小王文件,先给我看草稿。
这些是 prompt。
它们只影响这一次,不应该写进 Skill。
但下面这些是每次都要遵守的规则:
多人协作会议会后 24 小时内整理行动项。
每个行动项必须包含负责人、截止时间、交付物、确认人。
没有负责人或截止时间,不能进入待办列表。
提到小王时,要合并进 week-jobs/xiaowang.md。
更新前读取旧文件,合并而不是覆盖。
不确定时放入待确认,不编造。
这些应该写进 Skill。
资料里对这个区别说得很清楚:prompt 是对话级的一次性指令;Skill 是按需加载的可复用专业能力。Skills 适合团队流程、品牌规范、会议纪要格式、数据分析流程这类可重复工作。Custom instructions 更广泛地应用,Skills 只在相关任务加载。8 2
简单判断:
内容
放哪里
这次纪要语气轻松一点
prompt
这次只看技术事项
prompt
先输出草稿,不写文件
prompt
行动项必须有负责人和截止时间
Skill
小王事项合并进 week-jobs/xiaowang.md
Skill
旧任务不能被覆盖
Skill
长样例和历史写法
references/
字段完整性和文件差异检查
scripts/
千万别把 Skill 写成“我每次都可能想说的话合集”。
会议后事项跟进 Skill 只应该固定这几件事:
遇到哪类会议材料。
按什么步骤提取行动项。
输出什么字段。
哪些事项不能进入待办。
什么时候更新小王文件。
不确定时怎么处理。
怎么验证没有漏字段、没覆盖旧任务。
可复制:
请判断下面这些要求应该放进会议后事项跟进 Skill,还是留在本次 prompt。
规则列表: 1. [规则 1] 2. [规则 2] 3. [规则 3]
判断标准: 1. 只对这次会议有效 -> prompt 2. 每次会议后都要遵守 -> Skill 3. 很长但低频 -> references/ 4. 可自动校验 -> scripts/
输出表格,不要展开解释。 一句话:你只是今天想这么做,用 prompt;你不想以后每次都重新解释,就写进 Skill。
7. 发布后跑歪了就整份重写
会议后事项跟进 Skill 发布后,第一次跑歪很正常。
但不要整份重写。
要先分类。
同样是跑歪,原因可能完全不同:
现象
先改哪里
用户说“整理小王会后事项”但 Skill 没触发
description 太窄
用户只是要会议摘要,Skill 却触发
description 太宽
输出了没有截止时间的待办
workflow 或 gotchas 缺规则
把“待确认”写进正式待办
输出模板不清
覆盖了 week-jobs/xiaowang.md 旧内容
文件更新步骤缺读旧文件
把小张的事项写给小王
负责人归属规则不清
每次都手动检查字段
应该补 scripts/
关键字段缺失时还继续写文件
应该显式要求 Plan mode 或 interview 用户
经常漏掉读取旧文件、合并、验证这几个步骤
应该显式要求维护 update_plan
会议材料太长,主线程里塞满转写细节
应该明确 spawn subagent 做候选行动项提取
第一版 Skill 本来就常常要靠真实任务继续修改。更重要的是,你要看执行轨迹,不只看最终结果。如果 Agent 浪费步骤,常见原因是规则太泛、不适用,或者给了太多同级选项。触发问题还要用 should-trigger / should-not-trigger 查询集反复测。9 4
修改时记住三条:
一次只改一个问题。
每次改完用同一条会议材料回归。
不要为了一个失败案例,把 description 改到过拟合。
再加一条更关键的:
如果缺的是任务流程,不要只补一句“注意检查”;要补显式动作。
如果缺的是长子任务,不要让主 agent 硬扛;要明确交给 subagent,并规定返回摘要。
比如失败现象是:
会议里说“小王先按现有字段做 mock”,但没有明确截止时间。Codex 把它写进了正式待办。
这时候不要重写整个 Skill。
只补一条 gotcha:
如果行动项缺少负责人或截止时间,必须放入“待确认”,不得写入正式待办,也不得写入 week-jobs/xiaowang.md。
再用同一条会议材料回归。
如果失败现象是:
会议材料很长,Codex 在主线程里贴了大量转写细节,最后漏掉了小王的两条任务。
也不要只补一句“仔细阅读会议材料”。
要补成可执行的子 Agent 规则:
当会议材料很长、包含多段转写或多场会议时,spawn 一个 subagent。该 subagent 只做候选行动项提取,返回负责人、截止时间、交付物、确认人和原文依据。主 agent 不接收原始长转写,只接收摘要后再判断哪些事项能进入正式待办和 week-jobs/xiaowang.md。
如果失败现象是:
Codex 提取了行动项,但忘了先读取 week-jobs/xiaowang.md,直接覆盖了旧内容。
要补成计划规则:
执行时必须维护 update_plan,且不能跳过这 5 步:提取候选行动项、过滤缺负责人或截止时间的事项、读取 week-jobs/xiaowang.md 旧内容、合并新事项、检查 diff 确认旧事项未被删除。
可复制:
这个会议后事项跟进 Skill 发布后跑歪了。
失败现象: [写清楚哪里错]
真实会议材料: [粘贴触发请求和会议内容]
请先分类: 1. 触发问题 2. 执行步骤问题 3. 输出格式问题 4. 缺少 gotcha 5. 应该脚本化 6. 是否缺少 Plan/interview/update_plan/文件读写这类显式流程动作 7. 是否应该把过长子任务交给 subagent
然后只做最小修改。 不要重写整份 SKILL.md。 改完后,用同一条会议材料再跑一次。 会议后事项跟进 Skill 的迭代,不靠豪华重构。它靠一次抓住一个偏差。
8. 从公司库安装前不看权限和脚本
公司库里的 Skill 也不能闭眼装。
会议后事项跟进 Skill 尤其要小心,因为它通常会读写项目文件:
读取会议材料。
读取 week-jobs/xiaowang.md。
修改 week-jobs/xiaowang.md。
可能读取 references/ 里的团队成员说明。
可能运行 scripts/ 做字段检查。
资料里说得很直接:只从可信来源安装 Skill;安装不太可信的 Skill 前,要检查其中的文件、依赖、资源和外部网络访问。Skill 的主要风险包括 prompt injection 和 data exfiltration。3
翻译成人话就是:
它可能诱导 Agent 做不该做的事,也可能把不该出去的数据带出去。
安装这个 Skill 前,至少看 6 件事:
SKILL.md 的任务边界是不是只处理会议后事项跟进。description 有没有泛化到资料整理、项目管理、绩效评价。allowed-tools / disallowed-tools 有没有给过大权限。scripts/ 是否会读写 week-jobs/ 之外的路径。是否要求安装第三方包。
是否会访问外部网络或上传会议内容。
优先安装这些:
团队验证过。
边界只覆盖会议后事项跟进。
明确写了读写文件路径。
更新文件前会读取旧内容。
没有负责人或截止时间不会写入正式待办。
脚本只做本地字段检查。
先别安装这些:
description 写成“整理会议、同步待办、推进项目、跟踪成员”。脚本默认扫描整个项目目录,而不是限定 week-jobs/ 和会议材料。
需要联网但没说明原因。
会把会议内容发到外部服务。
会根据会议内容自动评价成员表现。
可复制:
帮我审查这个公司库里的会议后事项跟进 Skill 是否适合安装到真实项目。
检查: 1. SKILL.md 是否只覆盖多人协作会议后的行动项跟进 2. description 是否太泛,是否会误触发普通摘要、周报、项目管理 3. allowed-tools / disallowed-tools 是否合理 4. scripts/ 是否只做本地字段检查,是否读写敏感文件 5. 是否会访问外部网络或上传会议内容 6. 是否明确保护 week-jobs/xiaowang.md 的旧内容 7. 是否和我已有会议纪要或待办 Skill 重叠
输出: 1. 建议安装 / 先不安装 / 只在练习项目试用 2. 风险点 3. 安装前要问维护者的问题 公司库不是自动可信区。会议内容和成员工作安排都可能敏感,越是会读写项目文件的 Skill,越要先看清楚它能碰哪里。
会议后事项跟进 Skill 避坑清单
把这张表贴到每次审查前面。
问题
判断标准
1. 装到哪里?
写到项目路径和小王文件,就放项目级
2. 怎么判断主 Skill?
看最后不可省的结果,不看输入材料像什么
3. 为什么误触发?
多半是 description 把会议摘要、待办管理、项目管理都写进来了
4. 为什么更费 Token?
SKILL.md 太重,触发后抢上下文
5. 写大还是拆小?
输入、产出、失败标准一致就合,否则拆
6. Skill 和 prompt 怎么分工?
一次性偏好放 prompt,重复流程放 Skill
7. 发布后不好用怎么办?
分类问题;流程缺失补显式动作,长子任务指定 subagent
8. 公司库能不能直接装?
先审来源、权限、脚本、联网和文件读写范围
最后给 Codex 的总检查 prompt:
请按“会议后事项跟进 Skill 避坑清单”审查这个 Skill。
检查 8 件事: 1. 是否应该装到项目级 2. 是否值得创建或安装 3. description 是否容易误触发 4. SKILL.md 是否太重 5. 范围应该拆还是合 6. 哪些内容应该留在 prompt 7. 是否缺少 Plan/interview/update_plan/文件读写/subagent 这些显式流程动作 8. 是否适合从公司库安装到真实项目
要求: 1. 先给结论:保留 / 修改 / 不建议安装 2. 每条只写问题和最小修改建议 3. 不要重写整份 Skill
Skill 路径: [粘贴 SKILL.md 路径] 会议后事项跟进 Skill 真正厉害的地方,不是把“会议纪要”四个字写进一个新文件。
它厉害在:把会后跟进里最容易漏、最容易编、最容易改错文件的规则固定下来。
下次你再丢一段会议记录,Codex 不应该只是写一段漂亮摘要。
它应该知道:
哪些是行动项。
哪些缺字段不能进待办。
哪些属于小王。
应该合并到哪个项目文件。
哪些不确定必须问。
这才是 Skill 和普通 prompt 的区别。
prompt 解决这一次。
Skill 固定以后每一次。
参考资料
这篇只用了能落到操作上的一手资料: